81.3%mIoU!华中科大等提出Context Prior:在语义分割中引入上下文先验 | CVPR2020
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达


论文链接:https://arxiv.org/abs/2004.01547
代码链接:https://git.io/ContextPrior
最近的工作广泛探索了上下文相关性在语义分割任务中的重要性,通过充分捕获上下文信息以获得更准确的分割结果。但是,大多数方法很少区分不同类别之间的上下文相关性,这可能会影响语义分割模型的性能。例如,之前的经典工作non-local网络关注的是特征图像素点之间的关系,而忽略了不同类别之间的上下文依赖关系,因为并不是所有的类间依赖关系都对语义分割模型有用,有些甚至会造成混乱。non-local机制细节可以参考文章:视觉注意力机制 | non-local和自注意力机制的区别和联系)
在这项工作中,作者直接监督特征聚合以清楚地区分类内和类间上下文。具体来说,在亲和度损失下设计了一个即插即用的通用模块:context prior layer(上下文先验层)。给定一个输入图像和相应的ground truth,根据亲和度损失构建了一个Ideal Affinity Map以监督类内和类间信息的产生,使得学习的上下文先验提取属于同一类别的像素,而反向先验则关注于不同类别的像素,规范了类内和上下文信息的分离。
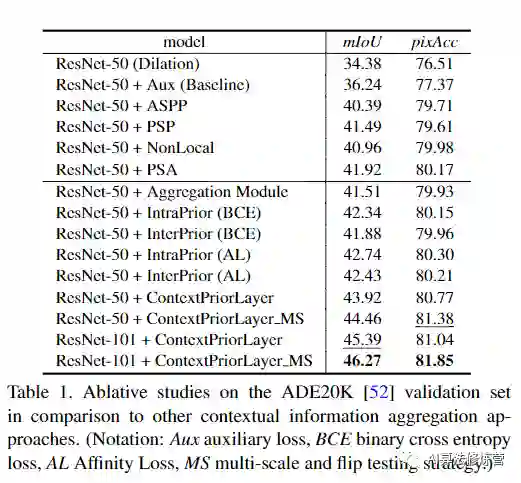
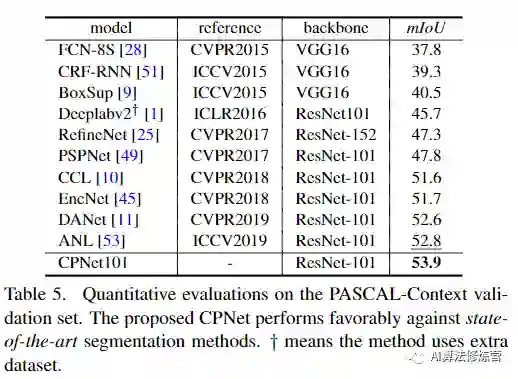
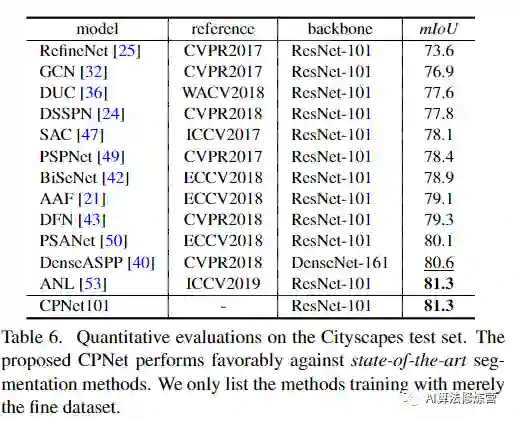
提出的context prior layer可以有选择地捕获类内和类间上下文相关性,从而实现可靠的特征表示。为了验证有效性,设计了有效的上下文先验网络(CPNet)。大量的定量和定性评估表明,所提出的模型与最新的语义分割方法相比具有良好的性能,实现SOTA。更具体地说,在ADE20K上达到46.3%mIoU,在PASCAL-Context上达到53.9%mIoU,在Cityscapes上达到81.3%mIoU。
主要贡献:
1)构造了一个上下文先验,并监督嵌入上下文先验层中的亲和力损失,以明确捕获类内和类间上下文依赖关系;
2)为语义分割设计了一个有效的上下文先验网络(CP-Net),其中包含骨干网络backbone和上下文先验层context prior layer;
3)所提出的方法在ADE20K,Pascal-Context和Cityscapes上实现SOTA。
文章的核心思想在于:根据标签,事先知道哪些像素属于同一个类,那么就可以利用这个先验知识去监督标签预测,使得预测结果尽量让同类像素的预测结果相同。
受卷积层结构的限制,全卷积网络FCN提供的上下文信息不足,有待改进。近年来各种方法被提出来用于探索上下文依赖性,以获得更准确的分割结果。
目前,聚合上下文信息主要有两种方法:
(1)基于金字塔的聚合方法
有几种方法如PSPNet采用基于金字塔的模块或全局池化来有规律的聚合区域或全局上下文信息。然而,它们捕获了同类的上下文关系,却忽略了不同类别的上下文,如图1(b)所示。当场景中存在混淆类别时,这些方法可能会导致上下文可靠性降低。
(2)基于注意力的聚合方法
最近基于注意力的方法,如通道注意力、空间注意力、point-wise attention,有选择地聚合不同类别之间的上下文信息。然而,由于缺乏明确的区分,注意力机制的关系描述不太清楚。因此,它可能会选择不需要的上下文依赖关系,如图1(e)所示。
总体而言,这两种方式都在没有明确区分类内和类间上下文的情况下聚合了上下文信息,从而导致了不同上下文关系的混合,造成混乱。
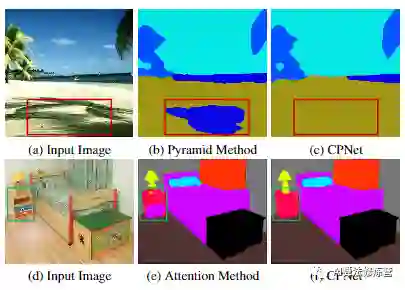
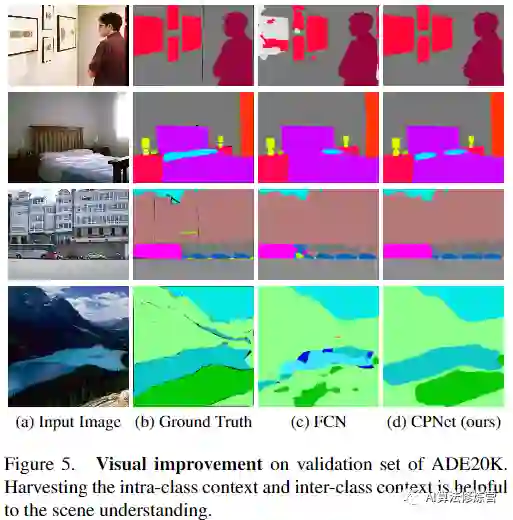
图1:语义分割中很难分割的情形示例。在第一行中,红色方框中的sand的中心部分被误分类为大海,因为阴影部分的外观与大海相似。使用基于金字塔的聚合方法,混淆的空间信息的聚合可能导致不良的预测,如(b)所示。在第二行中,绿色框中的桌子的外观与床的底部相似。基于注意力的方法在没有先验知识的情况下无法有效地区分混淆的空间信息,从而导致预测结果不正确,如(e)所示。在作者提出的CPNet中,以清晰的区分方式聚合了上下文相关性。值得注意的是,上下文先验将类内和类间关系建模为上下文先验知识,以捕获类内和类间上下文相关性。
作者注意到,确定的上下文依赖关系有助于卷积神经网络理解场景。相同类别的相关性(类内部上下文)和不同类别之间的差异(类间上下文)使特征表示更鲁棒,并减少了可能类别的搜索空间。因此,将ground truth建模类内和类间的先验知识,从而去监督网络上下文信息的学习,以获得更准确的预测,这对于场景分割非常重要。
文中,将上下文先验公式化为二进制分类器,以区分哪些像素属于当前像素的同一类别,而相反的先验可以集中于不同类别的像素。
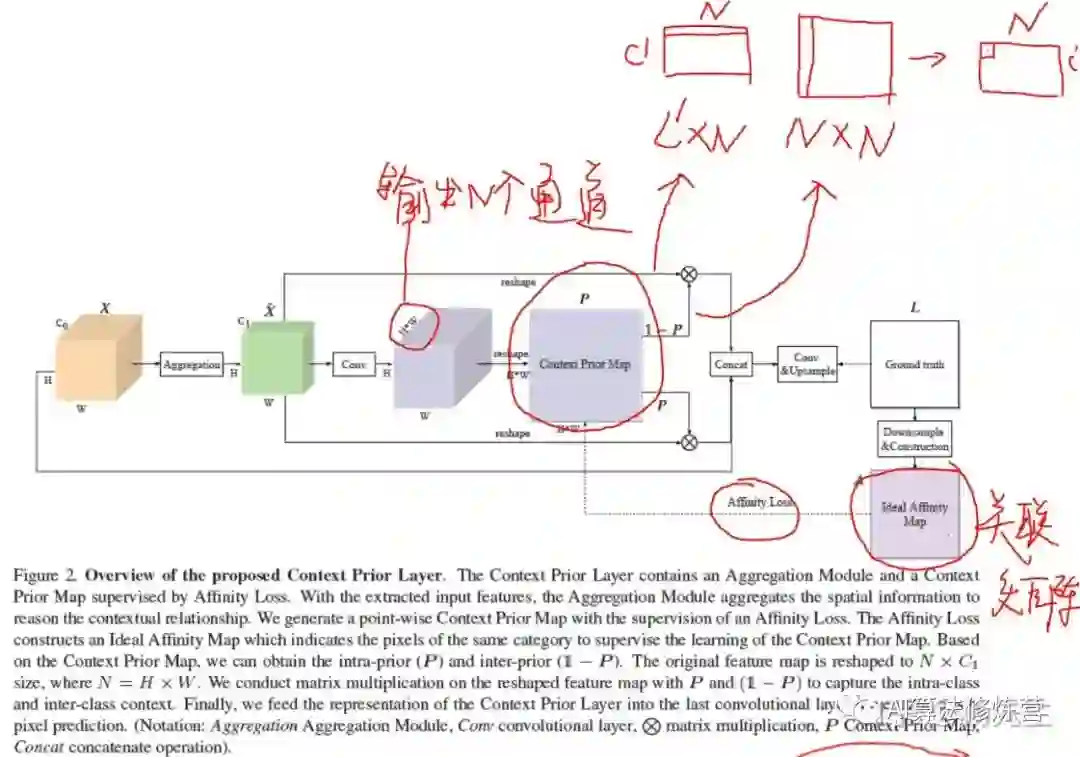
具体来说,首先使用全卷积网络来生成特征图和相应的先验图。对于特征图中的每个像素,先验地图可以有选择地突出显示属于同一类别的其他像素,以聚合类内上下文,而相反的先验可以聚合类间上下文。将先验地图嵌入到网络中,设计了包含亲和力损失Affinity Loss的Context Prior层,该层直接监督先验的学习。同时,Context Prior还需要空间信息来推理这些关系。为此,设计了一个聚合模块,该模块采用完全可分离的卷积(在空间和深度维度上分开)来有效地聚合空间信息。
2.1、亲和力损失(Affinity Loss)和上下文先验层(Context Prior Layer)
语义分割网络很难从孤立的像素中建模上下文信息。为了让网络建模类别之间的关系,引入了亲和度损失。对于图像中的每个像素,此损失让网络考虑相同类别的像素(上下文内)和不同类别之间的像素(上下文间)。然而,要想用亲和力损失对网络的学习进行监督,就要得到预测图和真值。那么Affinity Loss的真值是怎么产生的呢?
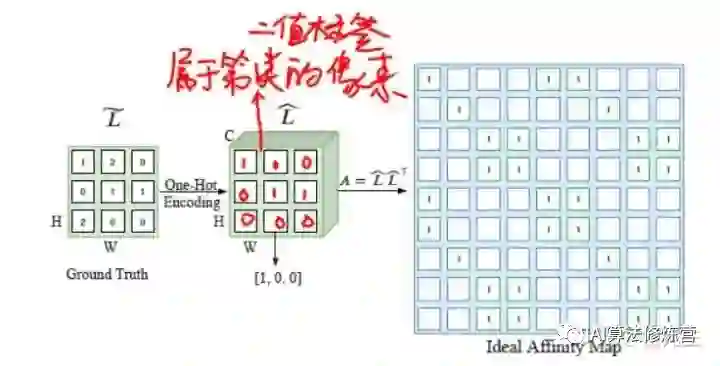
文章首先就从真值标签出发,经过one-hot编码之后,生成每一个类的像素二值标签(如上图)(实际上可以理解成根据标签对每一类做二值分割),于是得到C个HW大小的二值标签MAP。
但是每一个单独的二值标签只代表了某一类像素之间的关联,所以作者进一步将C个HW大小的二值标签MAP扩展成 C个长度等于像素数量N的向量,于是得到N*C的一个矩阵(如下图)。
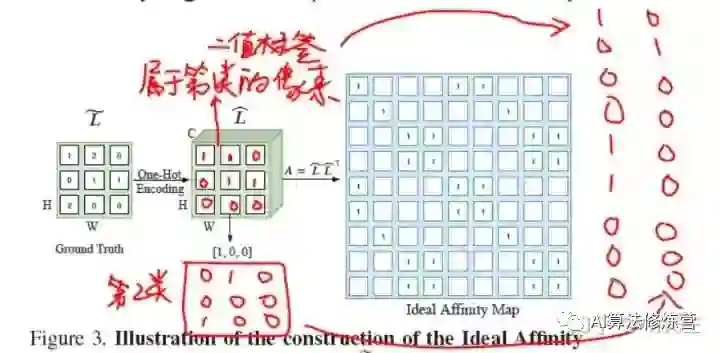
由于这个矩阵是个二值矩阵,所以作者将它与它的转置相乘,于是得到一个像素与像素之间相互关联(关联主要是指是不是同一类)关系的关联矩阵(图中的Affinity Map)。其实,可以看出Ideal Affinity Map中的第j行(1 <= j <= N)代表着H×W个像素中的第j个像素,与所有像素的关系。举例:如果第j个像素与第i个像素属于相同类别,那么Ideal Affinity Map中第j行第i列的值为1,否者为0。于是,Ideal Affinity Map中蕴含了相当丰富的类内信息,而1-Ideal Affinity Map则为丰富的类间信息。所以通过Affinity Loss使得Context Prior Map能够学习到这些信息。
对于Affinity Loss的就提表示,总的来说:
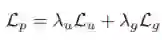
其中,表示Lp,Lu,Lg分别表示Affinity Loss,二元交叉熵损失,和全局损失。Lu,Lg前面的为权重参数,实验时作者设置为均为1。

二元交叉熵损失很好理解,就是预测关联矩阵各处的二值分类损失:
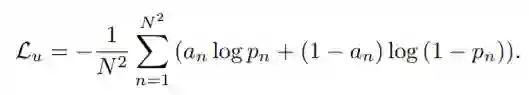
全局损失(j表示第j行,i表示第i列),作者设计了三种:
1、精确率好不好,即被预测为有关联的中确实有关联的比率;
2、召回率好不好,即被正确预测的有关联的占所有真实有关联的比率;
3、无关联的召回率好不好:和上面理解一样,只是针对无关联的样本。

有了这个关联矩阵,作者就尝试在网络中输出一个这样的矩阵,然后用这个真值关联矩阵训练网络。这个输出的关联矩阵,是通过卷积输出N个通道特征后,形状调整而来。根据预测关联矩阵P,就可以得到类间关系P, 还有类外关系1-P,用它们与原输入特征相乘,从而可以强迫同类像素特征相似,非同类像素特征距离增大。
2.2、聚合模块(Aggregation)
Context Prior Map需要一些局部空间信息来推断语义相关性。因此,作者设计了一个具有完全可分离的卷积(在空间和深度维度上都是分离的)的高效聚合模块来聚合空间信息。将标准卷积在空间上分解为两个不对称卷积。对于一个k×k卷积可以使用一个k×1卷积再加上一个1×k卷积,称为空间可分离卷积。与标准卷积相比,它可以减少k/2运算并保持相等的感受野大小。
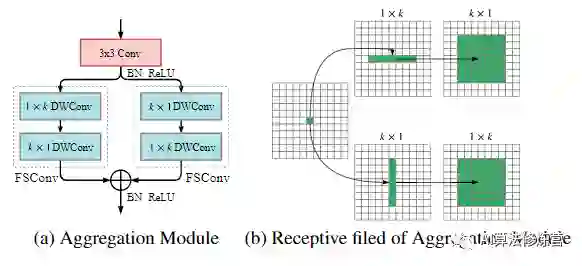
图4:聚合模块及其感受野的示意图(a)使用两个不对称的完全可分离的卷积来聚合空间信息,其输出具有与输入特征相同的通道。(b)聚集模块具有与标准卷积相同的感受野大小,但是计算量减少了。
2.3、CPNet
上下文优先级网络(CPNet)是由骨干网络backbone和上下文优先级层组成的全卷积网络。除了亲和度损失之外,在backbone的阶段4上使用了辅助损失,同样也是交叉熵损失。
作者设计上下文先验层(Context Prior Layer),它可以在任何backbone的最后插入以进行语义分割的任务。Context Prior Layer使用backbone如resnet50输出的特征图(图中最左边的黄色立体)作为输入。经过聚合模块(Aggregation)聚合局部上下文信息之后,送入一个卷积层与sigmoid层进行处理,最后进行reshape得到了Context Prior Map。Context Prior Map由ground truth产生的Ideal Affinity Map进行监督,学习得到了类内的上下文信息并与经过聚合后的特征图相乘后得到富含类内上下文信息的特征图。与此同时,用1-P得到可以得到类间上下文,同样的操作可以得到富含类间上下文信息的特征图。将类间、类内、原图进行concat后上采样,便得到了预测图。
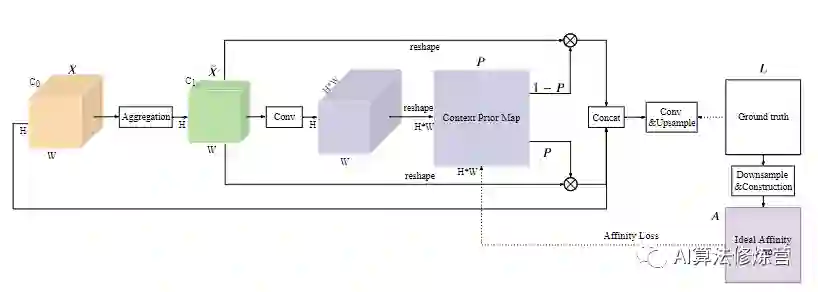
图2:上下文先验层(Context Prior Layer)概述。上下文优先层包含一个聚合模块和一个由亲和力损失(Affinity Loss)监督的上下文先验特征图(Context Prior Map)映射而成。利用提取的输入特征,聚集模块聚集空间信息以建立上下文关系。我们在亲和度损失的监督下生成point-wise的上下文先验映射。根据亲和度损失构建了理想的亲和度图(Ideal Affinity Map),用来指示相同类别的像素,以监督对上下文先验图的学习。
论文在ADE20K、Cityscapes和Pascal Context数据集上进行了实验。在ADE20K上达到46.3%mIoU,在PASCAL-Context上达到53.9%mIoU,在Cityscapes上达到81.3%mIoU。具体实验细节,可以参考论文原文。
参考:知乎文章 https://zhuanlan.zhihu.com/p/126426243
重磅!CVer-图像分割 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已汇集1300人!涵盖语义分割、实例分割和全景分割等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、TensorFlow和PyTorch等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加群
▲长按关注我们
麻烦给我一个在看!



