深度了解自监督学习,就看这篇解读 !大规模预训练视觉任务的BERT模型:iBOT

极市导读
字节提出的一篇最新的论文 iBOT 中,提出了适用于视觉任务的大规模预训练方法,通过对图像使用在线 tokenizer 进行 BERT 式预训练让 CV 模型获得通用广泛的特征表达能力。该方法在十几类任务和数据集上刷新了 SOTA 结果,在一些指标上甚至超过了 MAE。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
系列文章:
深度了解自监督学习,就看这篇解读 !Hinton团队力作:SimCLR系列
深度了解自监督学习,就看这篇解读 !微软首创:运用在 image 领域的BERT
深度了解自监督学习,就看这篇解读 !何恺明新作MAE:通向CV大模型
本文目录
1 iBOT
1.1 Self-supervised Learning
1.2 iBOT 方法概述
1.3 MIM 任务
1.4 Self-distillation
1.5 iBOT 的具体方法
1.6 模型结构
1.7 ImageNet-1k 实验结果
1.8 MIM 想要学习的模式可视化
Self-Supervised Learning系列解读目录
https://zhuanlan.zhihu.com/p/381354026
Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。
1 iBOT
论文名称:iBOT:Image BERT Pre-training with Online Tokenizer
论文地址:
https://arxiv.org/abs/2111.07832
前段时间,何恺明等人的一篇论文成为了计算机视觉圈的焦点。这篇论文仅用简单的 idea(即掩蔽自编码器,MAE)就达到了非常理想的性能,让人们看到了 Transformer 扩展到 CV 大模型的光明前景,给该领域的研究者带来了很大的鼓舞:
深度了解自监督学习,就看这篇解读 !何恺明新作MAE:通向CV大模型
在字节提出的一篇最新的论文 iBOT 中,他们提出了适用于视觉任务的大规模预训练方法,通过对图像使用在线 tokenizer 进行 BERT 式预训练让 CV 模型获得通用广泛的特征表达能力。该方法在十几类任务和数据集上刷新了 SOTA 结果,在一些指标上甚至超过了 MAE。
1.1 Self-supervised Learning
在预训练阶段我们使用无标签的数据集 (unlabeled data),因为有标签的数据集很贵,打标签得要多少人工劳力去标注,那成本是相当高的,太贵。相反,无标签的数据集网上随便到处爬,它便宜。在训练模型参数的时候,我们不追求把这个参数用带标签数据从初始化的一张白纸给一步训练到位,原因就是数据集太贵。于是 Self-Supervised Learning 就想先把参数从一张白纸训练到初步成型,再从初步成型训练到完全成型。注意这是2个阶段。这个训练到初步成型的东西,我们把它叫做 Visual Representation。预训练模型的时候,就是模型参数从一张白纸到初步成型的这个过程,还是用无标签数据集。等我把模型参数训练个八九不离十,这时候再根据你下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到完全成型,那这时用的数据集量就不用太多了,因为参数经过了第1阶段就已经训练得差不多了。
第一个阶段不涉及任何下游任务,就是拿着一堆无标签的数据去预训练,没有特定的任务,这个话用官方语言表达叫做:in a task-agnostic way。第二个阶段涉及下游任务,就是拿着一堆带标签的数据去在下游任务上 Fine-tune,这个话用官方语言表达叫做:in a task-specific way。
以上这些话就是 Self-Supervised Learning 的核心思想,如下图1所示,后面还会再次提到它。
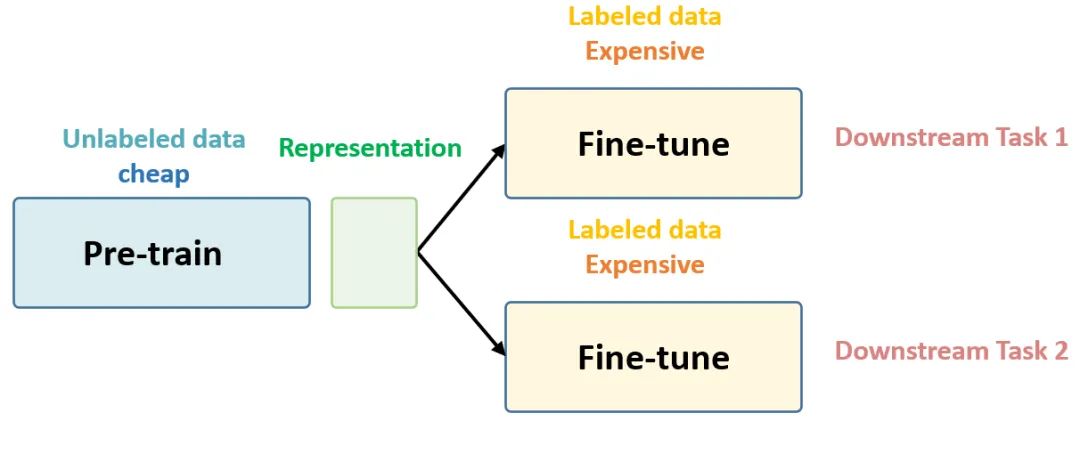
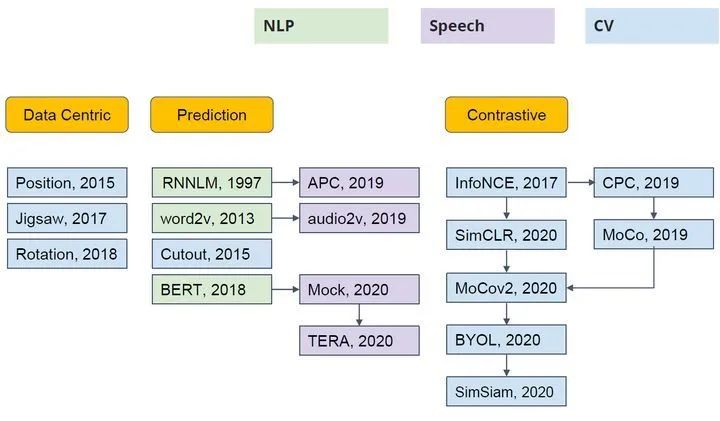
Self-Supervised Learning 不仅是在NLP领域,在CV, 语音领域也有很多经典的工作,如下图2所示。它可以分成3类:Data Centric, Prediction (也叫 Generative) 和 Contrastive。
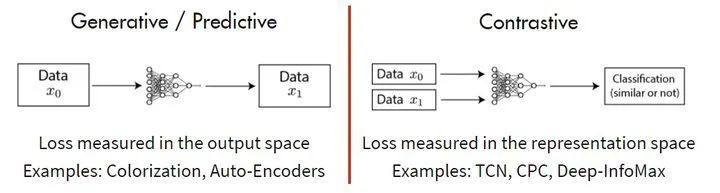
其中的主流就是基于 Generative 的方法和基于 Contrative 的方法。如下图 3 所示这里简单介绍下。基于 Generative 的方法主要关注的重建误差,比如对于 NLP 任务而言,一个句子中间盖住一个 token,让模型去预测,令得到的预测结果与真实的 token 之间的误差作为损失。基于 Contrastive 的方法不要求模型能够重建原始输入,而是希望模型能够在特征空间上对不同的输入进行分辨。
1.2 iBOT 方法概述
在 NLP 的大规模模型训练中,MLM (Masked Language Modeling)是非常核心的训练目标,其思想是遮住文本的一部分并通过模型去预测这些遮住部分的语义信息,通过这一过程可以使模型学到泛化的特征。NLP 中的经典方法 BERT 就是采用了 MLM 的预训练范式,通过 MLM 训练的模型已经被证明在大模型和大数据上具备极好的泛化能力,成为 NLP 任务的标配。
但是在大多数 CV 中的自监督学习任务里面,关注的往往是图片的 global view,比如 MoCo v3。而没有认真研究 image 的内部结构,也就不算是真正的 MIM (Masked Image Modeling)。
-
对于 NLP 任务的 MLM 中,lingual tokenizer 非常重要。它的任务是把 language 变成富含文本语义的 tokens。
-
与此相似,对于 CV 任务的 MIM 中,visual tokenizer 非常重要。它的任务是把 image 变成富含图像语义的 tokens。
但是,图片不像是文本,文本中自然蕴含有语言的语义信息,NLP 中 tokenization 通过离线的词频分析即可将语料编码为含高语义的分词。但是图片不一样,图片的信息比较连续,图像 patch 是连续分布的且存在大量冗余的底层细节信息,而图像 patch token 的语义信息丰富。所以图像 patch 的 visual semantic 信息不那么容易被提取。这个属性直观地带来了一个多阶段的训练策略,即:在训练目标模型之前,我们需要首先训练一个 off-the-shelf 的 tokenizer,它能够把 image 转换成语义丰富的 tokens。BEiT 中使用的是一个 Pre-trained discrete VAE 作为 tokenizer。虽然提供了一定程度的抽象,但discrete VAE 仍然只能在局部细节中捕获低级语义。
1.3 MIM 任务:
MIM 任务一般是对于一个 image token sequence , 首先随机采样 random mask, , 定义 , 把它们用 mask token 代替掉。得到 corrupted 的输入图片:
MIM 任务目的是根据 corrupted 的输入图片 去重建原图 。也就是去最大化:
BEiT的做法是最大化下式1:
式中, 是 tokenizer 的参数, 是目标模型的参数。
1.4 Self-distillation:
自蒸馏的方法,不同 prior 模型 中学习有用的信息,而从本模型的 past iteration 参数 中学习有用的信息。比如,一张图片 的两个不同的 data augmentation 版本 。并以此得到它们的输出: 和 。自蒸馏方法的做法是最小化下式2:
教师和学生网络的架构一致,但参数不同。学生网络参数 是教师网络参数 的 Model EMA。
1.5 iBOT 的具体方法:
在 iBOT 中,作者认为一个能够提取图像 patch 中高层语义的 tokenizer 可帮助模型避免学习到冗余的这些细节信息。作者认为视觉的 tokenizer 应该具备两个属性:(a)具备完整表征连续图像内容的能力;(b) 像 NLP 中的 tokenizer 一样具备高层语义。作者首先将经过 mask 过的图片序列输入 Transformer 之后进行预测的过程建模为知识蒸馏的过程,从 tokenizer 中获得知识。
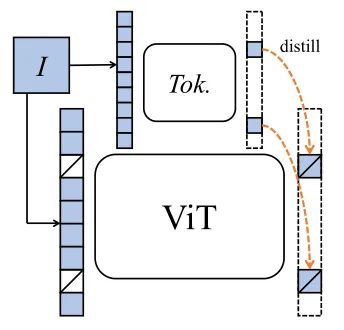
如上图4所示,待训练的目标网络 (比如 ViT) 输入 masked images,Online tokenizer 接收原始图像。目标是让待训练的目标网络将每个 masked patch token 恢复到其相应的 token。
注意 MAE 是使得 Decoder 的输出直接重建 masked patch,而 iBOT 则希望目标网络 (相当于是 Encoder) 的输出重建 masked patch token。所以图4的过程中:Online tokenizer 与目标网络一起学习,希望 Online tokenizer 能够捕获到图片高维的语义信息。
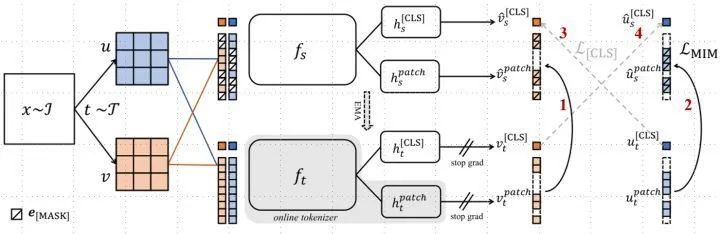
如上图5所示是 iBOT 的具体方法,一张图片 的两个不同的 data augmentation 版本 ,对它们进行 random mask 操作,得到 mask 版本 。
学生网络 :目标网络 (使用 BP 更新参数)
教师网络 :tokenizer (不使用 BP 更新参数,而是通过目标网络 EMA 更新参数)
1. 学生网络 输入 mask 版本 ,得到 tokens 。
2. 教师网络 输入 unmask 版本 ,得到 tokens 。
3. 希望 mask 版本经过学生网络之后可以得到重建,即最小化下式3:
4. mask 版本 和 unmask 版本 ,经过相同的处理。
作者发现,通过使用在线 tokenizer 监督 MIM 过程,即 tokenizer 和目标网络同步学习,能够较好地保证语义的同时并将图像内容转化为连续的特征分布。具体地,tokenizer 和目标网络共享网络结构,在线即指 tokenizer 其参数从目标网络的历史参数中滑动平均得出。
我们看到图5中一共有4个损失,为了帮助读者更好地理解图5的过程,我们把 iBOT 和 MAE 做个简单对比,如下图6所示:
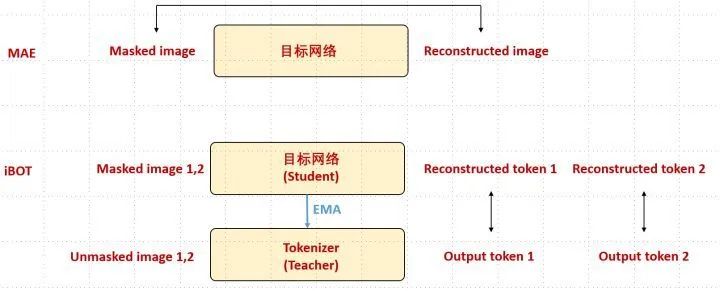
我们看到 MAE 就是把 masked image 通过目标网络,得到 Reconstructed image,然后让二者越接近越好。
我们看到 iBOT 是把2个 masked image 通过目标网络,把2个 unmasked image 通过教师网络,然后让目标网络的2个输出 tokens 和教师网络的2个输出 tokens 分别越接近越好。
所以图5的4个损失中:
1,2: 是 patch 标签上的自蒸馏。就是让目标网络的2个输出 tokens 和教师网络的2个输出 tokens 分别越接近越好。
3,4: 是在 [CLS] 标签上的自蒸馏保证了在线 tokenizer 学习到高语义特征。注意是不同的增强版本交叉进行。

iBOT 的伪代码如上图7所示,我们逐行分析,从进入循环开始:
第1行: 对输入图片进行数据增强。
第2,3行: 得到 的 random mask 版本 。
第4,5行: 学生网络 输入 mask 版本 ,得到 tokens。
第6,7行: 教师网络 输入 unmask 版本 ,得到 tokens。
第8行: 在 [CLS] 标签上的自蒸馏,就是让目标网络的 class token 1 和教师网络的 class token 2,让目标网络的 class token 2 和教师网络的 class token 1 越接近越好。对应图5的损失函数3,4。
第9行: 是 patch 标签上的自蒸馏。就是让目标网络的2个输出 tokens 和教师网络的2个输出 tokens 分别越接近越好,对应图5的损失函数1,2。
第10行: 合并2个损失。
第11行: BP 方式更新学生网络参数。
第12行: EMA 方式更新教师网络参数。
1.6 模型结构和训练设置:
目标网络结构上,作者依次尝试了 ViT-S/16, ViT-B/16, ViT-L/16, 和 Swin-T/{7,14},7和14代表 window size。优化器使用 AdamW,batch size=1024。在 ImageNet-1k 上预训练 ViT-S/16,ViT-B/16 和 Swin-T/{7,14} 的 Epoch 数分别是800,400和300。在 ImageNet-22k 上预训练 ViT-B/16,ViT-L/16 的 Epoch 数分别是80和50。
学习率 Linear warmup 10个 epochs 到 。weight decay 从0.04余弦退火到0.4。
Student temperature=0.1,Teacher temperature=0.04到0.07。
1.7 ImageNet-1k 实验结果:
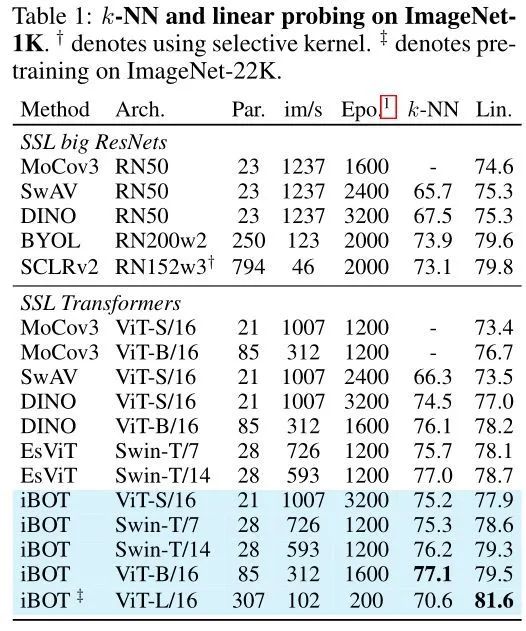
1 kNN: 把目标网络 Backbone 部分的权重冻结,在模型最后使用 k-nearest 完成分类。
2 Linear Probing: 把目标网络 Backbone 部分的权重冻结,在模型最后添加一层线性分类器 Linear Classifier (它其实就是一个 FC 层) 完成分类,只训练 Linear Classifier 的参数。
以上结果如下图8所示,只使用 ImageNet-1k 数据集时,使用 ViT-S/16 模型得到的 kNN 和 Linear Probing 的 Accuracy 分别是:75.2%和77.9%。使用 ViT-B/16 模型得到的 kNN 和 Linear Probing 的 Accuracy 分别是:77.1%和79.5%。使用 Swin-T/{7,14} 模型得到的 Linear Probing 的 Accuracy 分别是:78.6%和79.3%,超过了之前 EsViT 的78.1%和78.7%。
借助 ImageNet-22k 数据集,使用 ViT-L/16 模型得到的 Linear Probing 的 Accuracy 是:81.6%,使用 ViT-B/16 模型得到的 Linear Probing 的 Accuracy 是:79.5%。
3 Fine-tuning: 在模型最后添加一层线性分类器 Linear Classifier (它其实就是一个 FC 层) 完成分类,同时使用全部 label 训练目标网络 Backbone 部分的权重和分类器的权重。结果如下图9所示:只使用 ImageNet-1k 数据集时,使用 ViT-S/16 模型得到的 Fine-tuning 的 Accuracy 是:82.3%,使用 ViT-B/16 模型得到的 Fine-tuning 的 Accuracy 是:83.8%。借助 ImageNet-22k 数据集,使用 ViT-S/16 模型得到的 Fine-tuning 的 Accuracy 是:84.4%,使用 ViT-B/16 模型得到的 Fine-tuning 的 Accuracy 是:86.3%。
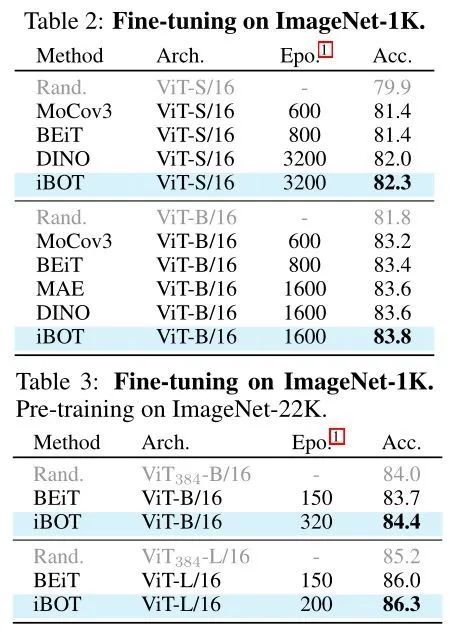
注意 MAE 使用 ViT-B/16 达到 83.6% 线性分类准确度 (fine-tuning) ,没超越 iBOT 的 83.8%。MAE 使用 ViT-B/16 达到 68% 线性分类准确度 (Linear Probing) ,也没超越 iBOT 的 79.5% 。
4 Semi-supervised Learning: 在模型最后添加一层线性分类器 Linear Classifier 完成分类,同时只使用1% 或10%的 label 训练目标网络 Backbone 部分的权重和分类器的权重。结果如下图10所示:
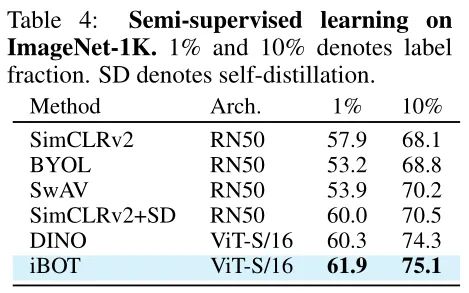
只使用1% 或10%的 label 做 Fine-tuning 以后,可以分别达到61.9% 和 75.1% 的 Top-1 Accuracy。
1.8 MIM 想要学习的模式可视化:
同时作者也进一步探究了 MIM 训练目标所带来的特性,以帮助分析 iBOT 在全局图像任务及密集图像任务出色表现的原因。为了帮助理解 MIM 想要学习的模式,我们将几种模式布局可视化。作者根据 ImageNet 验证集中所有图片 patch 的概率分布,可视化了部分类别中心所代表的模式。作者在大量的可视化结果中发现 iBOT 针对局部语义有非常好的可视化结果,如下图11所示是 Patch 的 tokens 学习到的模式的可视化。上面2张图展示的模式是汽车的灯和狗的耳朵,展现了不同局部类别语义;下面2张图展示的模式是条纹和曲面展现了不同局部纹理语义。


总结
MLM 的一个核心问题是 tokenizer 设计,在视觉里面,tokenizer 应该具备捕捉高层语义的特性。BEiT是最早期做这方面的代表性工作,借助 DALL-E 来做 tokenization。而 iBOT 通过在线自蒸馏的方法,实现了 online tokenizer 的训练。iBOT 其实既有 MIM 的做法,也有 Contrastive Learning 的思想。MIM 的做法体现在学生网络能够 reconstruct image token, 而 Contrastive Learning 的思想体现在使得目标网络和教师网络 (tokenizer) 的输出做蒸馏操作。这是非常重要的,因为通过这个形式,作者就可以用 KD 来建模-实现 online tokenizer。MIM的潜力已经逐步被证实,从 MLM 到 MIM 的过渡已被证明,由此观之比肩 GPT3 的 CV 预训练大模型已不远矣。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选






