Raúl Garreta大神教你5步搭建机器学习文本分类器!

摘要: Raúl Garreta,《Learning scikit-learn: Machine Learning in Python》一书作者,手把手教你5步搭建机器学习文本分类器:1.定义类别树;2.数据收集;3.数据标记;4.训练分类器;5.测试&提升分类器。

用机器学习构建一个好的文本分类器是一项很有挑战性的工作。你需要构造训练集、调参、校正模型及其他事情。本文将会描述如何使用MonkeyLearn训练一个文本分类器,具体分为如下5步:
1. 定义类别树
2. 数据收集
3. 数据标记
4. 训练分类器
5. 测试&提升分类器
1.定义类别树
在训练文本分类器之前,首先要确定你要把你的文本数据分成哪些类或者打上哪些标签。
1.1 选择类别
假如你要把来自不同网站的每日交易分类,那么你的类型就可能会包括:
娱乐
饮食
医药保健&美妆
零售
旅游&度假
其他
如果你对语义分析感兴趣,可能会有如下类别:
积极
消极
中立
相反,要是你对分类电商网站的客服短讯感兴趣,你可能会设计如下分类:
配送问题
支付问题
产品问题
折扣、优惠码和礼品卡
在不清楚要要使用哪些类别时,为了找到适合你模型的类别,探索并理解你的数据很重要。
1.2 构造类别体系
这个过程核心部分就是为你的类别创建一个合适的结构。当你想更加准确并且使用子类时,你需要定义一个层次树结构。在上面的例子中,你可以这样组织你的类别:
1.娱乐:
音乐会
电影
夜总会
2.饮食:
餐馆
酒吧
外卖
3.健康&美容:
头发&皮肤
水疗&按摩
化妆品
4.零售:
服装
电子产品:
电脑
智能手机
平板
电视机&录像机
5.旅游&度假:
酒店
机票
6.其他
1.3 关于类别树的小技巧
1.3.1结构。根据类别的语义关系组织类别结构。例如,“篮球”和“棒球”都应该是“运动”的子类。形成一个结构良好的类别树对分类器做出准确预测有很大帮助。
1.3.2.避免重叠。使用互斥且完备的类,并且避免定义歧义的和重叠的类:一段文本的所属类别应该是明确的,毫无疑问的。类别之间的重叠将会引起混淆,并且影响分类器的正确性。
1.3.3.不要混合分类标准。每个模型使用单一的分类标准。假设你要根据公司的描述对公司进行分类,你的类别可能包括B2B、B2C、企事业单位、金融、新闻传媒、建筑等。这时你可以构建两个模型:a)一个根据公司的客户进行分类(B2C、B2B、企事业单位);b)另一个根据公司经营的行业(金融、新闻传媒、建筑)。每个模型都应该有自己的标准。
1.3.4.由小及大。第一次训练模型时,建议从简单模型开始。复杂模型得付出更多精力才能达到足够好的预测效果。从少量类开始(少于10个类),类别树最多2层。
当简单模型能够取得预期效果时,尝试增加更多的类别并形成第三层类别树来提升模型效果。
2.数据收集
当你定义好类别树时,下一步就是获得用于训练样本的文本数据。建议考虑下面两种数据收集方式:
2.1内部数据
内部数据,如文件,文档、电子表格、邮件、客服短讯、聊天记录等。你的数据库或者每天使用的工具中都会有这些数据。
客服支持类:Zendesk、Intercom、Desk
客户关系管理:Salesforce、Hubspot CRM、Pipedrive
通讯软件:Slack、Hipchat、Messenger、
净推荐值软件:Delighted、Promoter.io、Satismenter
数据库:Postgres、MySQL、MongoDB、Redis
数据分析平台:Segment、Mixpanel
你可以使用CSV文件或者对应的接口API导入这些数据。
2.2 外部数据
数据无处不在,你可以使用网页抓取工具、API、开放数据集自动从网络获取数据。
2.3 爬虫框架
如果你有编程功底,不妨自己写爬虫。下面是一些常用的工具:
Python:Scrapy、Pyspider、Cola、Beautiful Soup
Ruby:Upton、Wombat
Javascript:Node Crawler、Simplecrawler
PHP:Goutte
2.4 可视化网页抓取工具
如果没有编程功底,使用一些可视化工具会方便很多,比如:Portia、ParseHub、Import.io
2.5 API
除了爬虫,你也可以使用API连接一些网站和社交媒体网站,然后获得你需要的训练数据。下面是一些常用的API:AngelList、Ebay、Facebook、Foursquare、GitHub、Instagram、New York Times、The Guardian、Tumblr、Twitter、Wikipedia、Yelp
2.6 开放数据
可以从一些开放数据网站获取如Kaggle, Quandl 和 Data.gov.
2.7 其他工具
如果你没有任何编程经验,Zapier、IFTTT这些协作工具通过API授权,自动帮你将常用工具软件互联,将有助于你获取训练数据。
3.数据标记
拿到训练数据后,你要给这些数据打上对应的标签,才能形成完整的训练集。这可能需要你手动完成,但是对训练模型至关重要。通过打标签这种行为,你告诉机器学习算法对于一个特定的文本输入,你期望输出的类别是什么。分类器的准确度取决于初始标签的正确性。
3.1 数据标记工具
创建和上传数据后,使用MobkeyLearn GUI(下一节会详细解释)
Excel、Libre Office、Google电子表格
Open Refine
你熟悉的任何工具和技术
有时你也可以在众包平台上外包你的数据标记工作,如Mechanical Turk,或者是外包给一些Upwork或者Freelancer上的自由职业者。
3.2 训练样本的数量
训练样本的数量取决于问题的复杂度以及模型中类别的数量。例如,训练一个用于对tweets进行语义分析的模型和训练一个识别商品评论主题的模型就不一样。语义分析问题更难解决,所以需要更多的训练数据。训练数据越多越好。我们建议每个类从最少20个样本开始。根据分类器取得的效果,逐渐增加训练数据。对于话题检测问题,使用200到500个训练样本会得到准确的模型。语义分析通常至少需要3000条训练样本才能得到勉强能接受的结果。
3.3 质量VS.数量
从少量样本开始训练模型更好,不过要百分百确定这些样本能够代表每一个类别,并且最开始手动标记的标签正确,而不是说增加存在大量错误的数据。海量的训练样本对机器学习算法固然重要,但是大量错误标记的样本,不关注数据本身,只会事倍功半。就好像用一本存在大量错误的历史书去教一个小孩,虽然他非常用功,可学到的知识终究还是错误的,又有什么用呢。因此训练开始阶段,使用标记正确的、高质量的训练数据。然后再通过增加更多高质量的数据提升分类器的准确度。
3.4 保存标记数据
为了在MonkeyLearn中能够使用这些训练样本,数据最好保存为2列的CSV或者Excel文件:1列表示输入的文本,1列表示期望输出的类别。最后,把这个CSV/Execl文件上传到MonkeyLearn,就可以开始训练模型了。有编程功底的话可以直接使用MonkeyLearn的API上传数据。
4.训练分类器
收集和标记完数据后,在MonkeyLearn上使用如下3步创建一个分类器:
使用MonkeyLearn创建一个分类器,创建过程中需要完成一些相关信息;
上传CSV、Execl数据文件;
训练分类器,根据类别树的复杂度以及数据量,可能需要几秒到几分钟不等的训练时间。
5.测试和提升分类器
训练好模型后,可以用一系列统计学上的指标来衡量分类器对新数据的预测能力。这些指标对理解模型、提升模型效果至关重要。这里有个例子可以看下。
5.1 正确率
正确率(Accuracy)是类别被正确预测的样本的比例,是对分类器整体上的评价。这个指标用来衡量父类对子类的区分度。在前面的例子中,当根类有6个子类(娱乐、饮食、健康、零售、旅游&度假、其他)时,“根类”准确率为80%。
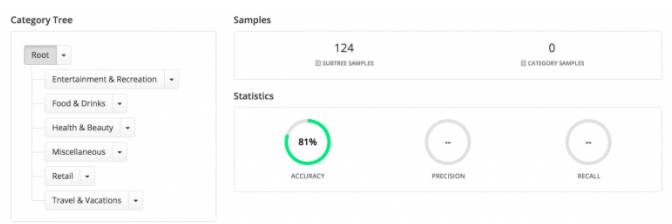
提升准确率的技巧:
增加更多子类的训练数据;
对可能标记错误的样本重新标记(如下面混淆矩阵小节所示);
有时一些兄弟类存在歧义,尽可能合并这些类;
正确率本身不是一个好指标,你还需要关注其他指标,如准确率和召回率。有时分类器的正确率很高,但是有些类的准确率(Precision)和召回率(Recall)很糟糕。
5.2 准确率和召回率
准确率和召回率用来检测某个类别上的正确率,下图是饮食类的准确率和召回率:
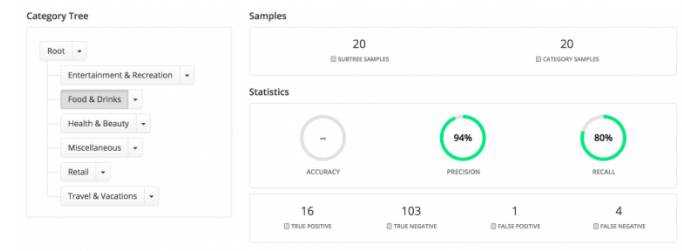
如果一个子类的准确率很低,这意味着来自其他兄弟类的样本被预测为这个子类,即假正。如果一个子类的召回率很低,这意味着来自这个类的样本被预测为其他兄弟类,也就是假负。通常在特定的类中,准确率和召回率存在权衡。也就是说增加准确率会导致降低召回率,反之亦然。
5.3 提升准确率和召回率:
使用混肴矩阵,查看模型的假正和假负;
如果一个样本初始被标记为类X,但却正确地预测为类Y(真正类别就是Y),将这个样本移到类Y下;
如果这个样本被错误预测为类Y,尝试让分类器更关注这种分类错误错误,增加更多X类和Y类的样本;
检查类X和类Y的关键词是否正确(见关键字云小节)。
5.4 混淆矩阵
混淆矩阵展示了实际类别和预测类别之间的不同。在前面的例子中,有4个标记为旅游&度假类的样本被错误预测为娱乐类(下图左下角红色的4)。如果混淆矩阵仅对角线非零,就代表你得到了最完美的结果。
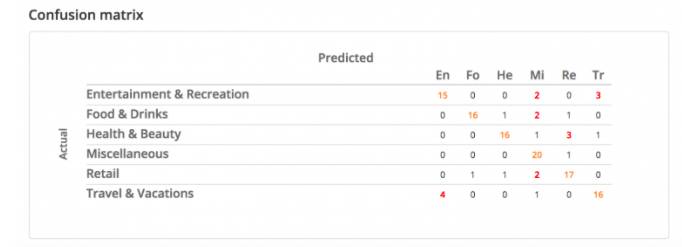
5.5 关键词云
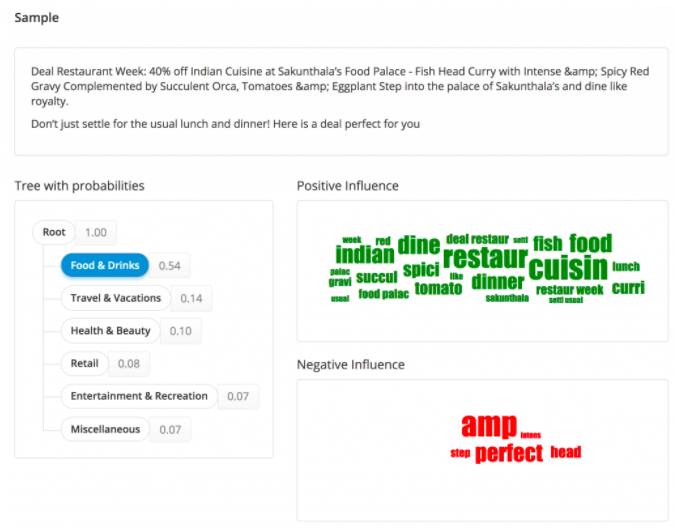
你可以看见类别树中每个类相关的关键词,比如饮食类的关键词:

提升关键字的注意事项:
检查用来代表每个类别样本的关键字是否有意义;
找到那些字典里没有的或与类无关的关键字;
你会看见一个详细的关键词列表,点击关键词云下面的Keyword List 链接查看他们之间的关系;
点击某个关键词过滤与之匹配的样本;
在停止词列表添加特定字符串,过滤掉不需要的关键词;
如果你的关键词列表中缺少某个表示类别的关键词,尝试增加更多那个类别的数据;
使用朴素贝叶斯分类器时,你可以看看那些对预测有正面或负面影响的特征,对调试每个类相关的特征很有用。
5.6 参数
调参可以极大地提升分类器效果,注意事项如下:
1. 如果你想避免分类器使用某些关键词,将他们加到停止词列表里;
2. 开发分类器时使用多项式朴素贝叶斯,它会使你对预测和调试理解更透彻。如果要得到更加准确的分类器,使用支持向量机;
3. 对特例使用词干提取;
4. 尝试增加最大特征参数,最大达到20000;
5. 如果在做语义分析,不要过滤默认停止词;
6. 处理社交媒体文本比如tweets或Facebook评论时,先进行预处理。
结束语
机器学习是一项很强大的技术,为了获得准确的模型,就需要一直迭代,直到达到期望的结果:
1. 提炼类别树
2. 收集数据
3. 给数据打标签
4. 上传数据,训练模型
5. 测试和提升:
指标(正确率,准确率和召回率)
假正和假负
混淆矩阵
关键词云和关键词列表
参数
有两种方式可以完成上述过程:
1.手动给数据加标签;
2.自助法,使用当前训练的模型去分类未标记样本,然后验证预测是否正确。通常,验证过程比从头开始手工标记更简单,更快。
除了增加数据,你也可以通过一下方式提升模型效果:
1.修正模型中的混淆之处;
2.提升类别的关键词;
3.寻找最佳参数
最后要强调的是,训练数据在整个过程中至关重要。使用糟糕的训练样本训练模型,最终会导致大量错误;如果使用高质量的数据集,你的模型会变的准确,能使文本分析的过程自动化。
浙大90后女黑客在GeekPwn2017上秒破人脸识别系统!




