ML通用指南:文本分类详细教程(上)
编者按:文本分类是各类应用中的一种基础机器学习问题,近日,一篇关于文本分类的文章成功引起学界大牛和竞赛机构注意,让他们在twitter上争相转载。那么,它到底讲述了什么内容呢?考虑到原文过长,本文是其中的(上)篇。
文本分类是一种应用广泛的算法,它是各种用于大规模处理文本数据的软件系统的核心,常被用于垃圾邮件识别及帮助论坛机器人标记不当评论。
当然,以上只是文本分类的两种常规应用,它们处理的是预定义的二元分类问题。在多元分类任务中,算法分类主要基于本文中的关键词
分类器标记垃圾邮件,并把它们过滤到垃圾邮件文件夹中
另一种常见的文本分类是情感分析,它的目标是识别文本内容积极与否:文字所表达的思想类型。同样的,这也是多元分类问题,我们可以采用二元的喜欢/不喜欢评级形式,也可以进一步细化,如设成1星到5星的星级评级。情感分析的常见应用包括分析影评,判断消费者是否喜欢这部电影,或者是分析大型商场的评论,推测普通大众对某个品牌新产品的看法。
本指南将介绍一些解决文本分类问题的机器学习最佳实践,你可以从中学到:
用机器学习解决文本分类问题
如何为文本分类问题挑选正确的模型
如何用TensorFlow实现你选择的模型
文本分类流程
第一步:收集数据
第二步:探索数据
第2.5步:选择一个模型
第三步:准备数据
第四步:构建、训练、评估模型
第五步:调整超参数
第六步:部署模型

文本分类流程
第一步:收集数据
收集数据是解决任何监督学习问题的最重要一步,数据的质量和数量直接决定着文本分类器的性能上限。
如果你没有想要解决的的特定问题,或者只是对一般的文本分类感兴趣,你可以直接用已经开源的大量数据集。这个GitHub repo里可能包含不少你可以用到的链接:github.com/google/eng-edu/blob/master/ml/guides/textclassification/loaddata.py。
但是,如果你有一个待解决的特定问题,你就得先收集必要数据。当然,有些数据是现成的,一些组织会提供访问其数据的公共API,比如Twitter API或NY Times API,如果有用,你可以直接通过它们来解决自己的问题。
以下是收集数据过程中的一些注意事项:
如果使用公共API,请在使用前先阅读它们的使用限制,比如某些API会对你的访问速度设限。
收集训练样本的量永远是越多越好,这有助于模型更好地概括。
如果涉及分类,确保每个类的样本数量不会过度失衡,换句话说,每个类中都应该有相当数量的样本。
确保你的样本可以覆盖所有可能的输入空间,而不仅仅是最常见的几种情况。
在本指南中,我们将以斯坦福大学开源的大型电影评论数据集(IMDb)为例,说明整个本文分类流程。该数据集包含人们在IMDb网站上发布的电影评论,以及评论者是否喜欢电影的相应标签(“positive”或“negative”)。这是用于情绪分析问题的一个经典数据集。
第二步:探索数据
构建、训练模型只是整个流程的一部分,如果事先能了解数据特征,这会对之后的模型构建大有裨益,比如更高的准确率,或是更少的数据和更少的计算资源。
加载数据集
首先,让我们将数据集加载到Python中:
def load_imdb_sentiment_analysis_dataset(data_path, seed=123):
"""Loads the IMDb movie reviews sentiment analysis dataset.
# Arguments
data_path: string, path to the data directory.
seed: int, seed for randomizer.
# Returns
A tuple of training and validation data.
Number of training samples: 25000
Number of test samples: 25000
Number of categories: 2 (0 - negative, 1 - positive)
# References
Mass et al., http://www.aclweb.org/anthology/P11-1015
Download and uncompress archive from:
http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
"""
imdb_data_path = os.path.join(data_path, 'aclImdb')
# Load the training data
train_texts = []
train_labels = []
for category in ['pos', 'neg']:
train_path = os.path.join(imdb_data_path, 'train', category)
for fname in sorted(os.listdir(train_path)):
if fname.endswith('.txt'):
with open(os.path.join(train_path, fname)) as f:
train_texts.append(f.read())
train_labels.append(0 if category == 'neg' else 1)
# Load the validation data.
test_texts = []
test_labels = []
for category in ['pos', 'neg']:
test_path = os.path.join(imdb_data_path, 'test', category)
for fname in sorted(os.listdir(test_path)):
if fname.endswith('.txt'):
with open(os.path.join(test_path, fname)) as f:
test_texts.append(f.read())
test_labels.append(0 if category == 'neg' else 1)
# Shuffle the training data and labels.
random.seed(seed)
random.shuffle(train_texts)
random.seed(seed)
random.shuffle(train_labels)
return ((train_texts, np.array(train_labels)),
(test_texts, np.array(test_labels)))
检查数据
加载完数据后,最好对其一一检查:选择一些样本,手动检查它们是否符合你的预期。比如示例用的电影评论数据集,我们可以输出一些随机样本,检查情绪标签和评论包含的情绪是否一致。
“十分钟的故事非要讲两小时,要不是没什么大事,我早就中途起身走人了。”
这是数据集中被标记为“negative”的评论,很显然,评论者觉得电影非常拖沓、无聊,这和标签是匹配的。
收集关键指标
完成检查后,你需要收集以下重要指标,它们有助于表征文本分类任务:
样本数:数据集中的样本总数。
类别数:数据集中的主题或分类数。
每个类的样本数:如果是均衡的数据集,所有类应该包含数量相近的样本;如果是不均衡的数据集,每个类所包含的样本数会有巨大差异。
每个样本中的单词数:这是文本分类问题,所以要统计样本所包含单词数的中位数。
单词词频分布:数据集中每个单词的出现频率(出现次数)。
样本长度分布:数据集中每个样本的
第2.5步:选择一个模型
到目前为止,我们已经汇总了数据,也深入了解了数据中的关键特征。接下来,根据第二步中收集的各个指标,我们就要开始考虑应该使用哪种分类模型了。这也意味着我们会提出以下这些问题:“我们该怎么把文本数据转成算法输入?”(数据预处理和向量化),“我们应该使用什么类型的模型?”,“我们的模型应该实用什么参数配置?”……
得益于数十年的研究,现在数据预处理和模型配置的选择非常多元化,但这么多的选择其实也带来了不少麻烦,我们手头只有一个特定问题,它的范围也很宽泛,那么怎么选才是最好的呢?最老实的方法是一个个试过去,去掉不好的,留下最好的,但这种做法并不现实。
在本文中,我们尝试着简化选择文本分类模型的过程。对于给定数据集,我们的目标只有两个:准确率接近最高,训练时间尽可能最低。我们针对不同类型的问题(特别是情感分析和主题分类问题)进行了大量(~450K)实验,共计使用12个数据集,交替测试了不同数据预处理技术和不同模型架构的情况。这个过程有助于我们获得影响优化的各个参数。
下面的模型选择和流程图是以上实验的总结。
数据准备与模型算法构建
计算比率:样本数/单个样本平均单词数
如果以上比率小于1500,对文本进行分词,然后用简单的多层感知器(MLP)模型对它们进行分类(下图左侧分支)
a.用n元模型对句子分词,并把词转换成词向量
b.根据向量的重要程度评分,从中抽出排名前2万的词
c.构建MLP模型
如果以上比率大于1500,则将文本标记成序列,用sepCNN模型对它们进行分类(下图右侧分支)
a.对样本进行分词,根据单词词频选择其中的前2万个
b.将样本转换为单词序列向量
c.如果比率小于1500,用预训练的sepCNN模型进行词嵌入,效果可能会很好
调整超参数,寻找模型的最佳参数配置
在下面的流程图中,黄色框表示数据和模型的准备阶段,灰色框和绿色框表示过程中的每个选择,其中绿色表示“推荐选择”。你可以把这张图作为构建第一个实验模型的起点,因为它能以较低的计算成本提供较良好的性能。之后如果有需要,你可以再在这基础上继续改进迭代。
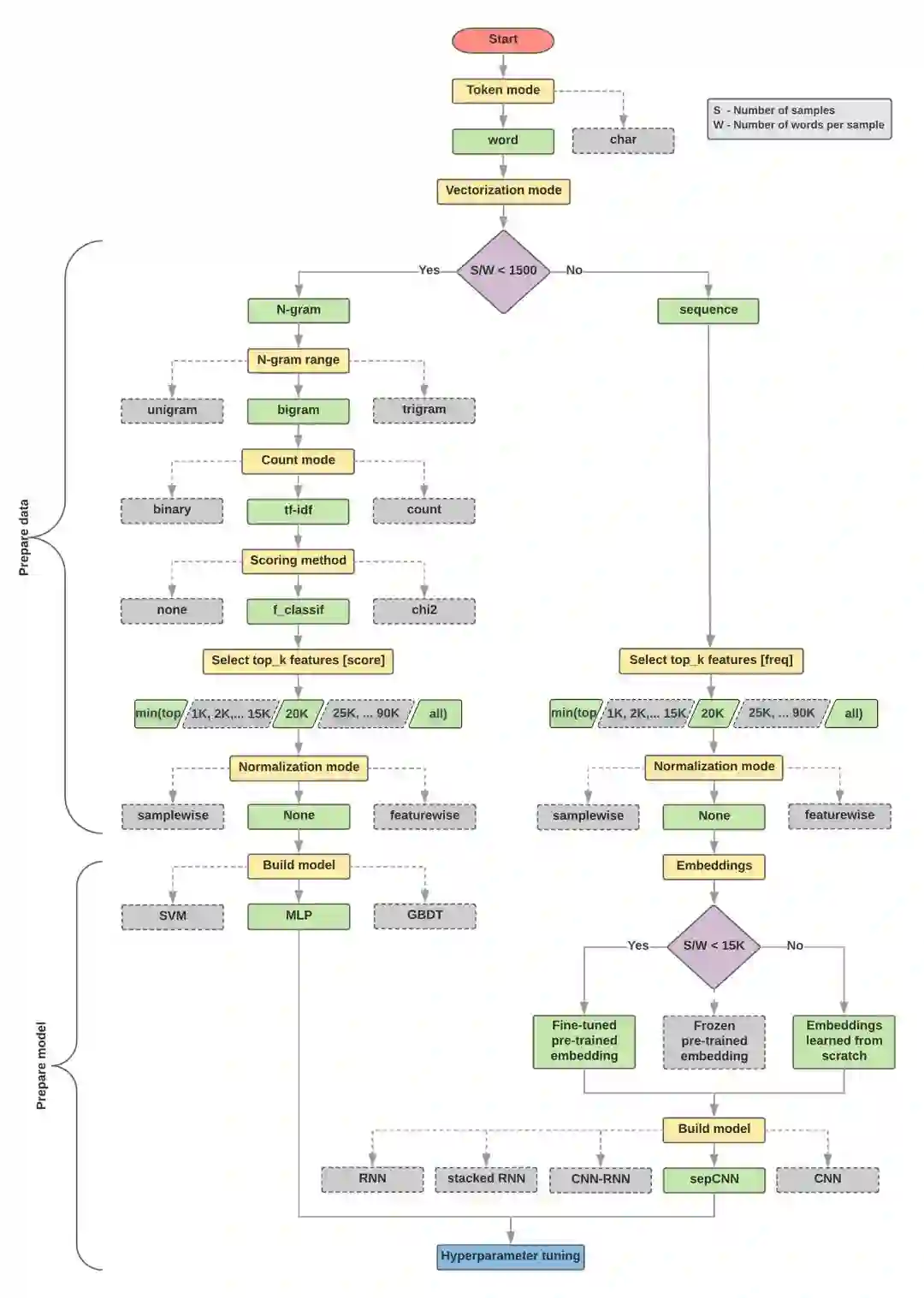
文本分类流程图
这个流程图回答了两个关键问题:
我们应该使用哪种学习算法或模型?
我们应该如何准备数据以有效地学习文本和标签之间的关系?
其中,第二个问题取决于第一个问题的答案,我们预处理数据的方式取决于选择的具体模型。文本分类模型大致可分为两类:使用单词排序信息的序列模型和把文本视为一组单词的n-gram模型。其中序列模型的类型包括卷积神经网络(CNN)、递归神经网络(RNN)及其变体。n-gram模型的类型包括逻辑回归、MLP、DBDT和SVM。
对于电影评论数据集,样本数/单个样本平均单词数约为144,所以我们会构建一个MLP模型。






