机器学习自动文本分类

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
文本分类是对文本进行智能分类。使用机器学习来实现这些任务的自动化,使整个过程更加快速高效。人工智能和机器学习可以说是近来最受益的技术。它们的应用无处不在。正如 Jeff Bezos 在给股东的年度公开信中所说:
在过去的几十年中,计算机已将程序员可以用清晰的规则和算法来描述的任务自动化。而对于精确描述规则困难得多的任务,现代机器学习技术同样可以自动化。说到自动化文本分类,我们写过文章介绍它背后的技术及其应用。在这里,我们改进一下文本分类器。在这篇文章中,我们将讨论与自动化文本分类 API 相关的技术、应用、定制和细分。
文本数据的意图、情绪和情感分析是文本分类的极其重要的部分。这些用例在机器智能爱好者中引起了极大的轰动。我们为每个类别的分析单独开发了分类器,因为研究每种分析本身就是一个巨大的话题。文本分类器可以处理各种文本数据集。分类器可以使用带标记的数据来训练,也可以对原始的非结构化文本进行操作。这两种分类器都有很多应用。
定义完分类类别时,有监督的文本分类也就完成了。它基于训练和测试原理。我们将标记的数据提供给机器学习算法进行处理。算法在标记的数据集上进行训练,并给出所需的输出(预定义的类别)。在测试阶段,算法被馈入不可观测的数据,并将它们分类成训练阶段使用的不同的类别。
垃圾邮件过滤是有监督分类的一个例子。收到的电子邮件会根据其内容自动分类。语言检测、意图、情绪和情感分析都是基于有监督系统的。它可以用于特殊用途,例如通过分析数以百万计的在线信息来识别紧急情况。这是大海捞针的问题。我们提出了一个智能的公共交通系统来识别这种情况。为了识别数百万在线对话中的紧急情况,训练的分类器必须较准确。这需要特殊的损失函数,在训练的时候采样,还需要一些方法,如建立一个多分类器栈,每个分类器都细化了前一个的结果从而解决这个问题。
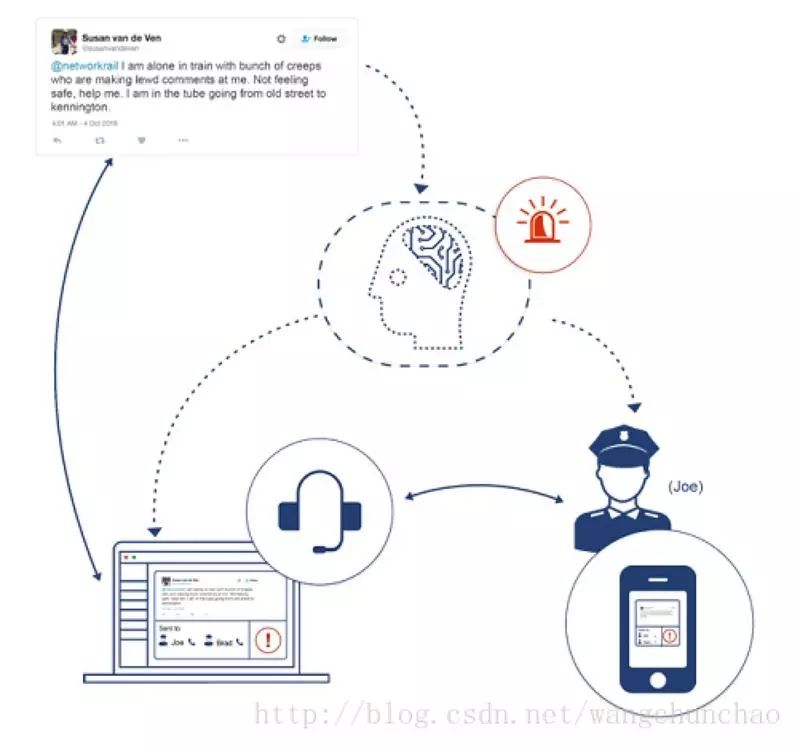
有监督分类基本上是要求电脑模仿人类。这些算法被赋予一组分类的文本(也称为训练集),基于它们生成 AI 模型,当进一步给新的未标记文本时,这些模型可以自动对它们进行分类。我们的一些 API 是基于监督系统的。文本分类器目前使用 150 个类别训练。
无监督分类是在没有提供外部信息的情况下完成的。算法试图发现数据中的自然的结构。请注意,自然的结构可能不是人们所想象的逻辑划分。算法在数据点中查找相似的模式和结构,并将它们分组成簇。簇形成之后,数据的分类就完成了。以网络搜索为例,算法根据搜索词生成簇,并将其作为结果呈现给用户。
每个数据点都嵌入到超空间中,你可以在 TensorBoard 上对其进行可视化。下面的图片是基于我们在印度电信公司 Reliance Jio 做的 twitter 研究。

数据探索是基于文本相似性来找到相似的数据点。这些类似的数据点为一个近邻簇。下面的图片显示了推文“reliance jio prime membership at rs 99 : here’s how to get rs 100 cashback...“的近邻。

正如你所看到的,随附的推文与带标签的推文相似。这个簇是一类相似的推文。无监督分类能方便地从文本数据中产生洞察。它是高度可定制的,因为不需要标记。它可以在任何文本数据上运行,而无需训练和标记。因此,无监督分类是语言不能描述的。
很多时候,使用机器学习的最大障碍是没有数据。很多人想用 AI 来分类数据,但那需要数据集,产生了类似于“先有鸡还是先有蛋”问题。自定义文本分类是在没有任何数据集的情况下构建自己的文本分类器的最佳方法之一。
在 ParallelDots 的最新研究工作中,我们提出了一种对文本进行零次学习(zero-shot learning)的方法,在这种方法中,训练学习在大型噪声数据集上学习句子及其类别之间关系的算法可以推广到新的类别,甚至是新的数据集。我们称之为“训练一次,随处测试”。我们还提出了多种神经网络算法,可以利用这种训练方法,并在不同的数据集上获得好的结果。最好的方法是使用 LSTM 模型来学习关系。这个想法是,如果人们可以在句子和分类之间建立“归属”的概念,这个知识对于看不见的分类甚至看不见的数据集都是有用的。
要创建自定义文本分类器,需要先注册一个 ParallelDots 账户并登录到仪表板。
点击仪表板中的“+”图标来创建你的第一个分类器。接下来,定义对数据进行分类的一些类别。请注意,为了获得最佳结果,类别要互斥。
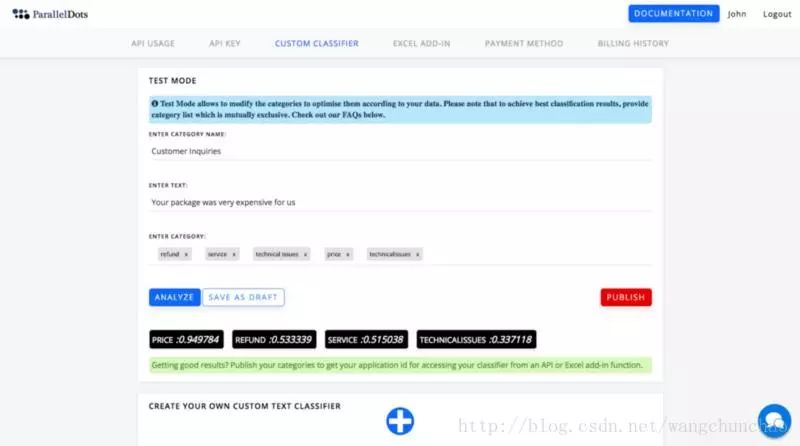
你可以分析文本样本来检查分类的准确性,并在发布之前尽可能多地调整分类列表。一旦类别发布,你将获得一个用以使用自定义分类 API 的应用程序 ID。
考虑到数据加标签和准备可能是一个限制,自定义分类器是一个很好的不需要太多投入的建立文本分类器的工具。我们也相信,这将降低构建实用的机器学习模型的门槛,这种机器学习模型可以跨行业应用于各种使用场景。
作为一个人工智能研究小组,我们不断开发尖端技术,使过程更简单、更快捷。文本分类就是这样一个技术,未来有巨大的潜力。随着互联网上的信息越来越多,轻松分析和呈现这些信息有赖于智能机器算法。机器智能的未来肯定是令人兴奋的,请订阅我们的通讯,以获得更多这样的信息。
ParallelDots AI API 是由 ParallelDots Inc 提供的深度学习支持的 Web 服务,可以理解大量的非结构化文本和可视化内容,从而助力你的产品。可以查看我们的一些文本分析 API,也可以填写此表或通过 apis@paralleldots.com 联系我们。
查看英文原文:
https://towardsdatascience.com/automated-text-classification-using-machine-learning-3df4f4f9570b





