谷歌做了45万次不同类型的文本分类后,总结出一个通用的“模型选择算法”
来源:developers.google.com,新智元

谷歌官方推出“文本分类”指南教程。为了最大限度地简化选择文本分类模型的过程,谷歌在进行大约450K的文本分类实验后,总结出一个通用的“模型选择算法”,并附上一个完整的流程图,非常实用。
文本分类(Text classification)算法是大规模处理文本数据的各种软件系统的核心。比如,电子邮件软件使用文本分类来确定受到的邮件是发送到收件箱还是过滤到垃圾邮件文件夹;讨论论坛使用文本分类来确定用户评论是否应该标记为不当。
下面是两个主题分类( topic classification)的例子,任务是将文本文档归类为预定义的一组主题。多数主题分类问题要基于文本中的关键字。
主题分类被用于标记收到的垃圾邮件,这些邮件被过滤到垃圾邮件文件夹中
另一种常见的文本分类是情感分析(sentiment analysis),其目的是识别文本内容的极性(polarity):它所表达的观点的类型。这可以采用二进制的“喜欢/不喜欢”来评级,或者使用更精细的一组选项,比如从1颗星星到5颗星星的评级。情感分析的例子包括分析Twitter上的帖子,以确定人们是否喜欢黑豹电影,或者从沃尔玛的评论中推断普通大众对耐克新品牌的看法。
这个指南将教你一些解决文本分类问题的关键的机器学习最佳实践。你将学习:
使用机器学习解决文本分类问题的高级、端到端工作流(workflow)
如何为文本分类问题选择合适的模型
如何使用TensorFlow实现你选择的模型
文本分类的workflow
以下是解决机器学习问题的workflow
步骤1:收集数据
步骤2:探索你的数据
步骤2.5:选择一个模型*
步骤3:准备数据
步骤4:构建、训练和评估你的模型
步骤5:调优超参数
步骤6:部署模型

解决机器学习问题的workflow
【注】 “选择模型”并不是传统机器学习workflow的正式步骤;但是,为你的问题选择合适的模型是一项关键的任务,它可以在接下来的步骤中明确并简化工作。
谷歌机器学习速成课程的《文本分类》指南详细解释了每个步骤,以及如何用文本数据实现这些步骤。由于篇幅限制,本文在涵盖重要的最佳实践和经验法则的基础上,重点介绍步骤2.5:如何根据数据集的统计结构选择正确的模型,并提供一个完整的流程图。
收集数据是解决任何有监督的机器学习问题的最重要步骤。构成它的数据集有多好,你的文本分类器就有多好。
如果你没有想要解决的特定问题,只是对探索文本分类感兴趣,那么有大量可用的开源数据集。下面的GitHub repo就足以满足你的需求:
https://github.com/google/eng-edu/blob/master/ml/guides/text_classification/load_data.py
另一方面,如果你正在处理一个特定的问题,则需要收集必要的数据。许多组织提供用于访问其数据的公共API ——例如,Twitter API或NY Times API,你可以利用这些来找到想要的数据。
以下是收集数据时需要记住的一些重要事项:
如果你使用的是公共API,请在使用之前了解API的局限性。例如,一些API对查询速度设置了限制。
训练示例(在本指南的其余部分称为示例)越多越好。这将有助于模型更好地泛化。
确保每个类或主题的样本数量不会过度失衡。也就是说,每个类都应该有相当数量的样本。
确保示例充分覆盖了可能的输入空间,而不仅仅覆盖常见的情况。
在本指南中,我们将使用IMDb的电影评论数据集来说明这个workflow。这个数据集收集了人们在IMDb网站上发布的电影评论,以及相应的标签(“positive”或“negative”),表示评论者是否喜欢这部电影。这是情绪分析问题的一个典型例子。
加载数据集
检查数据
收集关键指标
构建和训练模型只是工作流程的一部分。事先了解数据的特征能够帮助你构建更好的模型。这不仅仅意味着获得更高的准确度,也意味着需要较少的训练数据,或者更少的计算资源。
到这一步,我们已经收集了数据集,并深入了解了数据的关键特性。接下来,根据我们在步骤2中收集的指标,我们应该考虑应该使用哪种分类模型。这意味着提出问题,例如“如何将文本数据呈现给期望输入数字的算法?”(这叫做数据预处理和矢量化),“我们应该使用什么类型的模型?”,“我们的模型应该使用什么配置参数?”,等等。
经过数十年的研究,我们已经能够访问大量的数据预处理和模型配置选项。然而,大量可供选择的可行方案大大增加了手头的特定问题的复杂性和范围。考虑到最好的选择可能并不明显,一个想当然的解决方案是尝试尽每一种可能的选择,通过直觉排除一些选择。但是,这样做成本是非常昂贵的。
在本指南中,我们试图最大限度地简化选择文本分类模型的过程。对于给定的数据集,我们的目标是找到在最小化训练所需的计算时间的同时,实现接近最大精度的算法。我们使用12个数据集针对不同类型的问题(尤其是情感分析和主题分类问题)进行了大量(~450K)实验,将不同的数据预处理技术和不同的模型架构交替用于每个数据集。这有助于我们找到影响最佳选择的数据集参数。
下面的模型选择算法(model selection algorithm)和流程图是我们的大量实验的总结。

数据准备和模型构建算法
1. 计算样本的数量/每个样本中单词的数量这个比率。
2. 如果这个比率小于1500,那么将文本标记为n-grams并使用简单的MLP模型进行分类(下面的流程图的左边分支):
a. 将样本分解成word n-grams;把n-grams转换成向量。
b. 给向量的重要性打分,然后根据分支选择前20K。
c. 构建一个MLP模型。
3. 如果比率大于1500,则将文本标记为序列,并使用sepCNN模型进行分类(流程图右边分支):
a. 将样本分解成单词;根据频率选择前20K的单词。
b. 将样本转换为单词序列向量。
c. 如果原始样本数/每个样本的单词数这个比率小于15K,则使用微调的预训练sepCNN模型,可能得到最优的结果。
4. 用不同的超参数值来测量模型的性能,以找到数据集的最佳模型配置。
在下面的流程图中,黄色框表示数据和模型准备过程。灰色框和绿色框表示我们为每个流程考虑的选项。绿色框表示我们对每个流程的推荐选项。
你可以用这个流程图作为你的第一个实验的起点,因为它可以让你在低计算成本下获得良好的准确度。你可以在后面的迭代中继续改进初始模型。
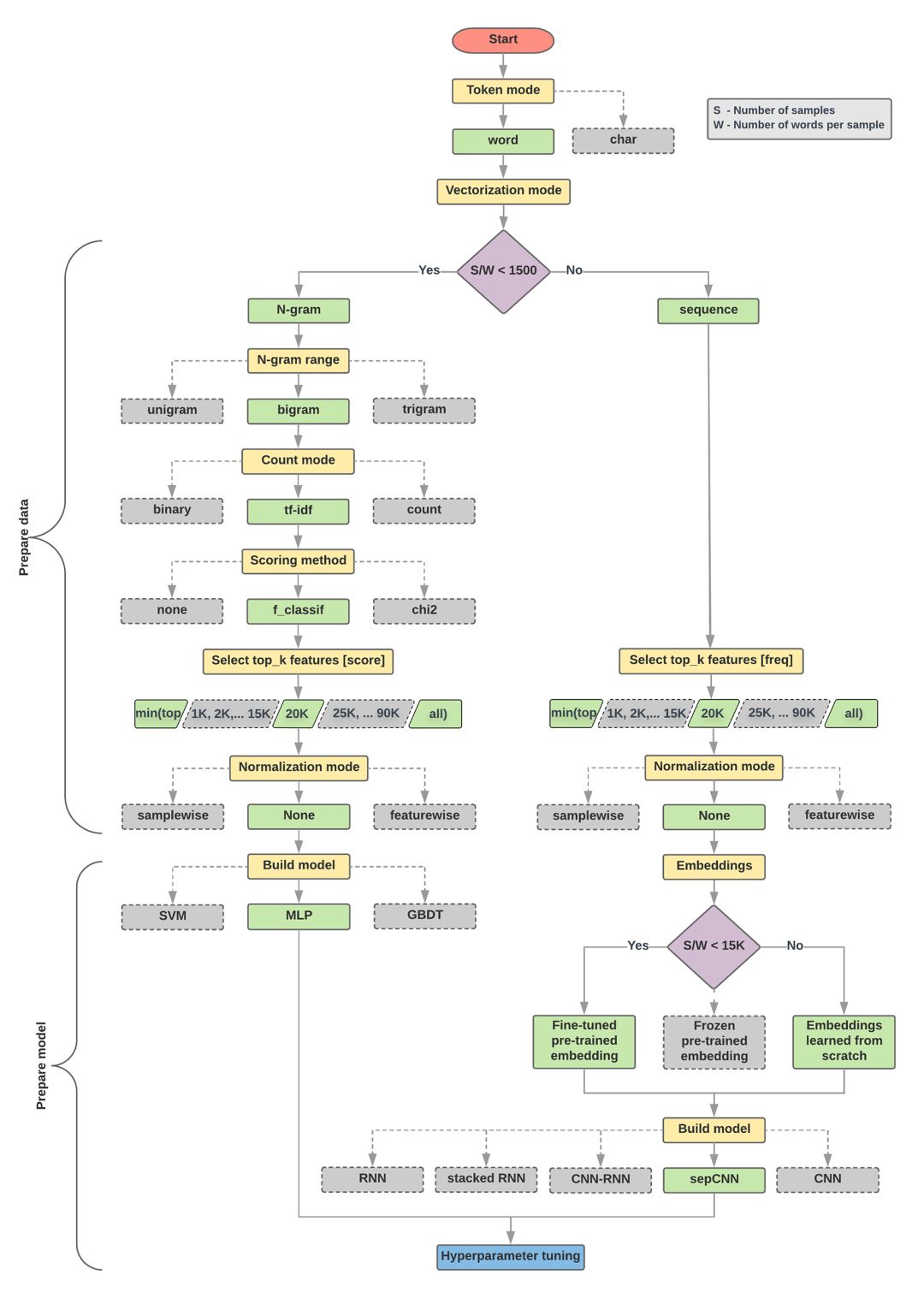
文本分类流程图(点击可放大查看)
此流程图回答了两个关键问题:
我们应该使用哪种学习算法或模型?
我们应该如何准备数据,才能有效地学习文本和标签之间的关系?
第二个问题的答案取决于第一个问题的答案;我们预处理数据的方式将取决于我们选择的模型。模型可以大致分为两类:使用单词排序信息的模型(序列模型),以及仅将文本视为单词的“bags”(sets)的模型(n-gram模型)。
序列模型包括卷积神经网络(CNN),递归神经网络(RNN)及其变体。 n-gram模型包括逻辑回归,简单多层感知机(MLP或全连接神经网络),梯度提升树( gradient boosted trees)和支持向量机(SVM)。
在实验中,我们观察到“样本数”(S)与“每个样本的单词数”(W)的比率与模型的性能具有相关性。
当该比率的值很小(<1500)时,以n-gram作为输入的小型多层感知机(选项A)表现得更好,或者说至少与序列模型一样好。 MLP易于定义和理解,而且比序列模型花费的计算时间更少。
当此比率的值很大(> = 1500)时,我们就使用序列模型(选项B)。在接下来的步骤中,你可以根据这个比率值的大小,直接阅读所选模型的相关章节。
对于我们的IMDb评论数据集,样本数/每个样本的单词数的比值在144以下。这意味着我们将创建一个MLP模型。
步骤3:准备数据
N-gram向量[选项A]
序列向量[选项B]
标签的向量化
步骤4:构建,训练和评估模型
构建最后一层
构建n-gram模型[选项A]
构建序列模型[选项B]
训练模型
步骤5:调优超参数
步骤6:部署模型
文本分类是机器学习中的基本问题,在各种产品应用中均有涉及。在本指南中,我们将文本分类的workflow分解为几个步骤。对于每个步骤,我们都根据特定数据集的特征,建议自定义的实现方法。尤其是,我们根据样本数量与每个样本中的单词数量的比值,来建议你使用哪一种模型,从而能够更快地让模型接近最佳性能。其他的步骤都是基于模型选择这个步骤的。遵循这个指南中的建议,参考附录中的代码和流程图将有助于你的学习和理解,并快速获取文本分类问题的解决方案。
《文本分类》指南地址:
https://developers.google.com/machine-learning/guides/text-classification/
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习




