一种基于序列标注的MOOC知识点抽取方法
DASFAA 2017 Workshop
原文连接:https://link.springer.com/chapter/10.1007/978-3-319-55705-2_24
作者:Zhuoxuan Jiang, Yan Zhang, and Xiaoming Li (Peking University)
一、研究背景
思路和研究意义:MOOC上的文本数据不完全是结构化的(例如视频字幕是有老师切分得到的,因此是结构化的,但论坛帖子是学生自发的,因此不是结构化的),所以需要用基于知识点的方式进行组织管理,进一步可以做concept map,跨领域知识分析以及个性化学习等工作。
研究内容:根据文本内容抽取知识点
难点挑战:1)需要一个普适的方法,不依赖于课程设计和老师授课方式;2)获取有label的训练集比较困难
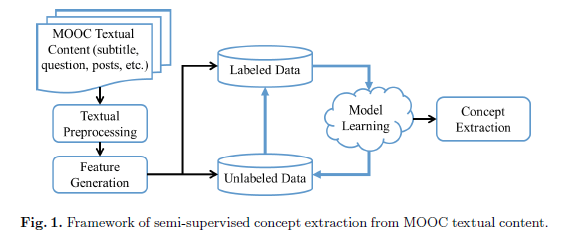
解决方案:看成是一个NLP的序列标注问题,改进原来的CRF模型,变成一个半监督模型框架,减少标注任务量
二、相关工作
信息抽取方面:key phrase extraction, terminology extraction, and named entity recognition,MOOC知识点特别之处在于不仅仅是垂直领域下的,而且还是跨领域的
序列标注方面:有用规则的,有用机器学习方法的,区别是MOOC上不仅仅是要抽取领域相关的信息,而且要找普遍的knowledge concept
MOOC数据挖掘:介绍了一下MOOC上(尤其是论坛上)的Machine Learning研究
三、算法模型
主要算法就是用条件随机场CRF,根据给定的单词序列,去标注每个单词是否是一个知识点的组成部分(感觉比标注词性容易的task)
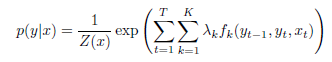
word的特征工程:5类
1)Text Style:是不是英文,周围的词是不是英文,第一个词,最后一个词,在引号中的词
2)Structure:(这个词/前一个词/后一个词)Part-of-Speech tag
3)Context:TF-IDF,BM25(以及bi-gram和前后词的variant)
4)Semantic:Word2Vec(与前后词的语义相似度)
5)Dictionary:是否在通用词典中出现
推断过程:极大似然+正则化,L-BFGS训练参数,维特比算法求解最优序列
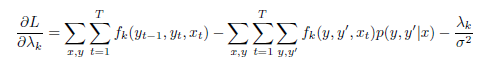
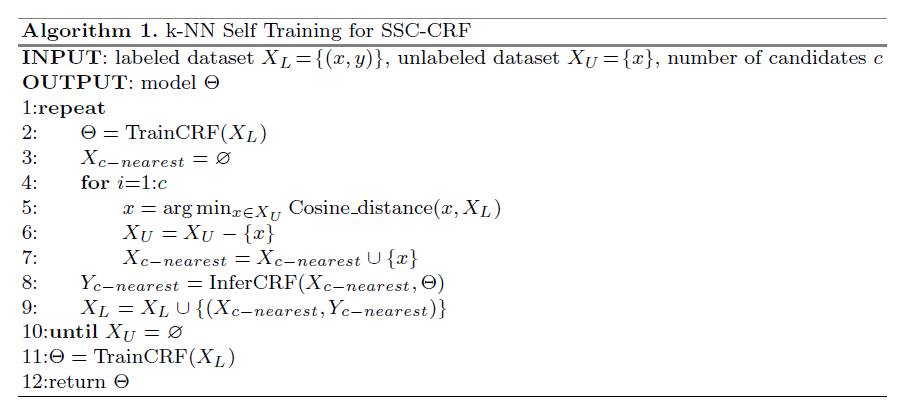
半监督学习算法框架:借鉴了KNN和self learning的思路,先有一部分标注,可以训练得到一个CRF,每次选出未标注中与现有集合最相似的序列进行标注,重新训练CRF,循环标注所有其他的序列
四、实验
label set = {not a concept, the beginning word of a concept, the middle word of a concept}
Baselines:Term Frequency,Bootstraping,Stanford Chinese NER,Terminology Extraction,Supervised Concept-CRF,Semi-supervised Concept-CRF
实验:
1)模型对比,尤其是全监督和半监督;
2)语料内标注:subtitle训练,subtitle测试;
3)语料间标注:subtitle训练,PPT测试;
4)Feature Contribution。
五、可以借鉴的地方
1)抽取知识点的一种方式,转化成序列标注问题
2)从全监督到半监督学习框架的转换




