ACL 2022 | 跨语言命名实体识别:无监督多任务多教师蒸馏模型



论文标题:
An Unsupervised Multiple-Task and Multiple-Teacher Model for Cross-lingual Named Entity Recognition
论文链接:

模型架构
2.1 Teacher Model
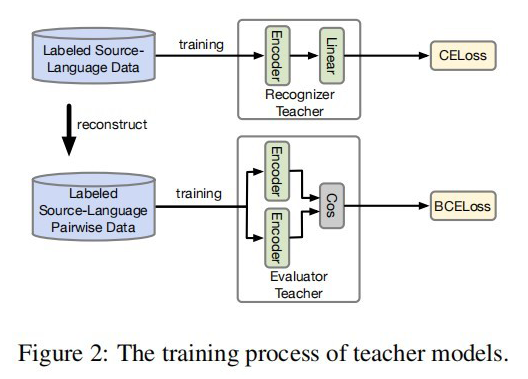
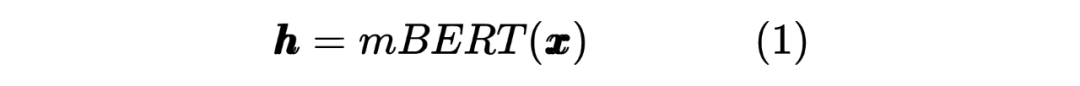
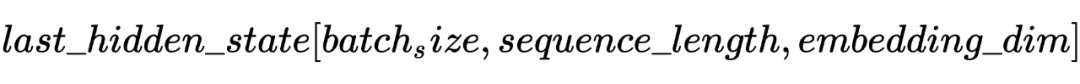
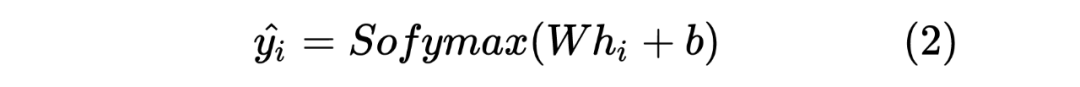
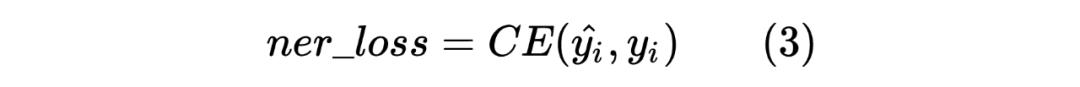
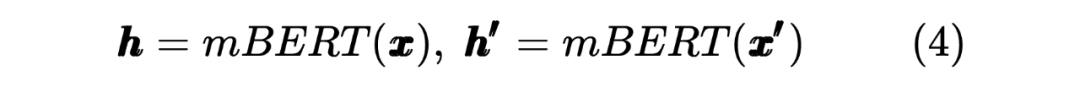
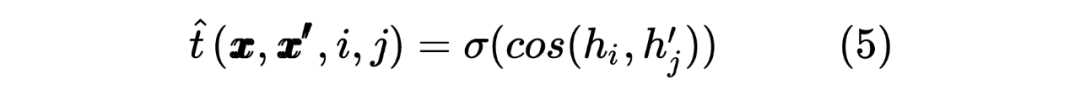
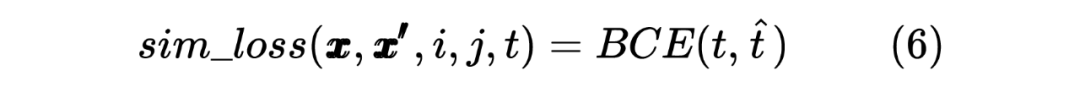
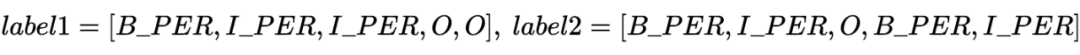
2.2 Student Model Distilled
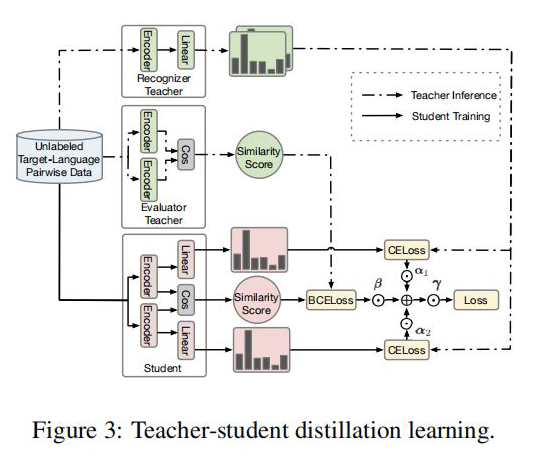
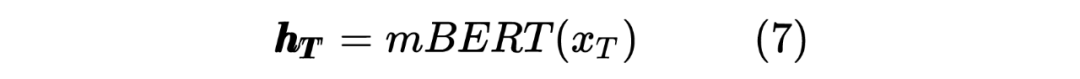
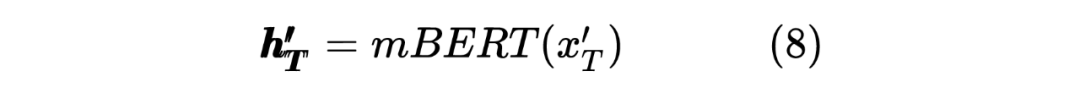
获得两个序列的 hidden_state 后进行一个线性计算,然后利用 softmax 进行归一化,得到每个 Token 预测的标签,计算如下:
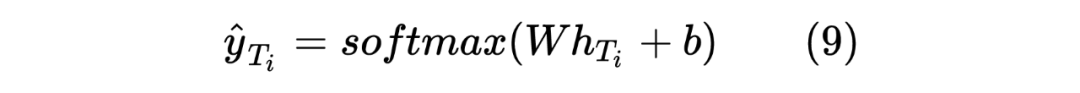
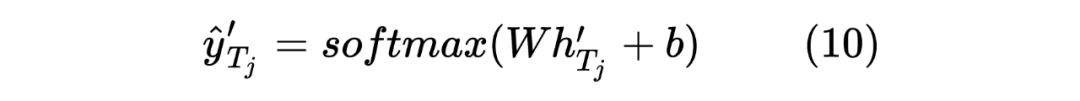
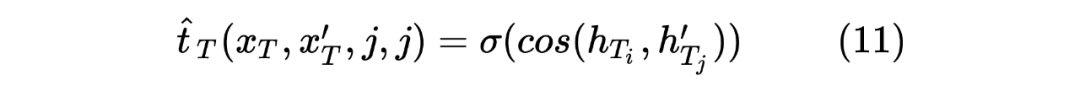
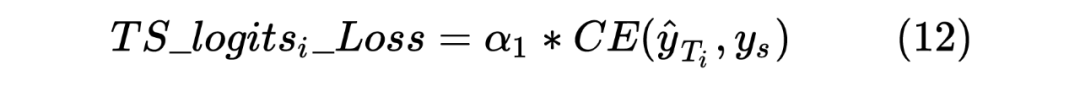
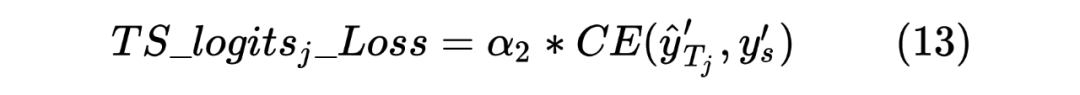
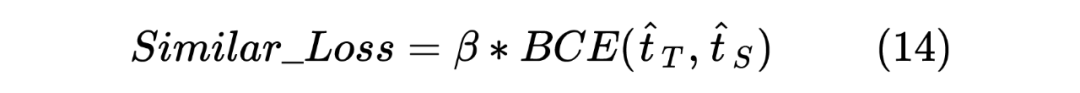
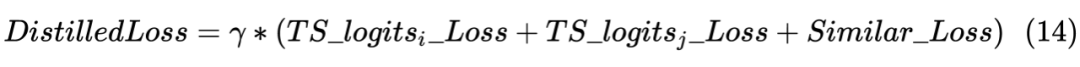
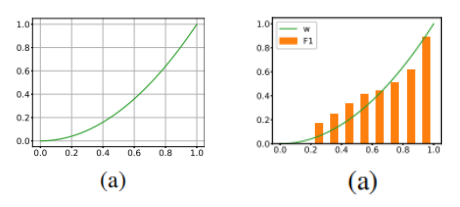
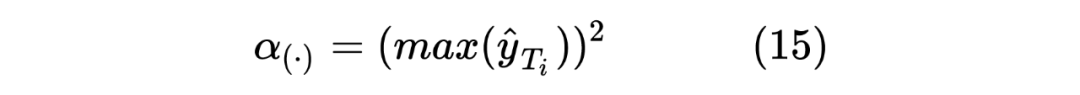
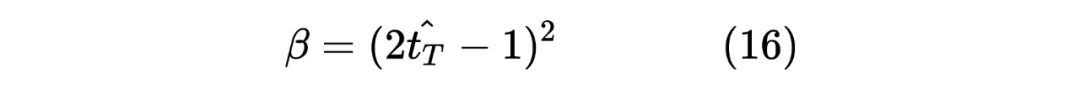
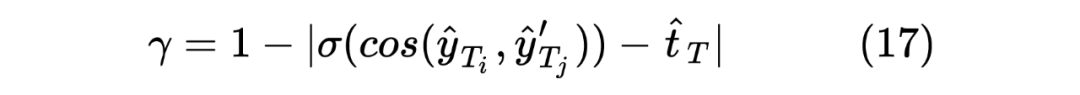

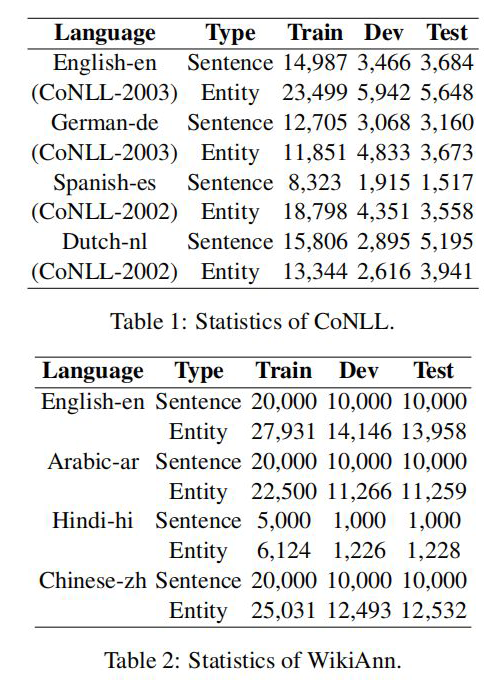
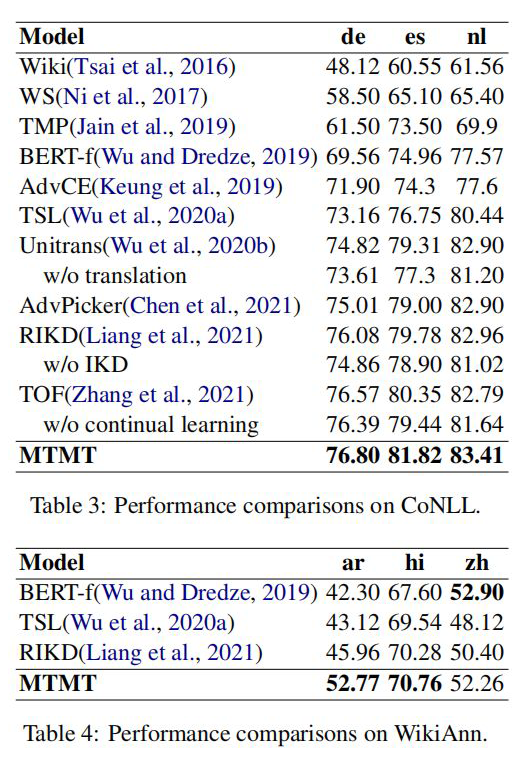
实验结果

简单代码实现
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2022/5/30 13:59
# @Author : SinGaln
"""
An Unsupervised Multiple-Task and Multiple-Teacher Model for Cross-lingual Named Entity Recognition
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import BertModel, BertPreTrainedModel, logging
logging.set_verbosity_error()
class TeacherNER(BertPreTrainedModel):
def __init__(self, config, num_labels):
"""
teacher模型是在标签数据上训练得到的,
主要分为三个encoder.
:param config:
:param num_labels:
"""
super(TeacherNER, self).__init__(config)
self.config = config
self.num_labels = num_labels
self.mbert = BertModel(config=config)
self.fc = nn.Linear(config.hidden_size, num_labels)
def forward(self, batch_token_input_ids, batch_attention_mask, batch_token_type_ids, batch_labels, training=True,
batch_pair_input_ids=None, batch_pair_attention_mask=None, batch_pair_token_type_ids=None,
batch_t=None):
"""
:param batch_token_input_ids: 单句子token序列
:param batch_attention_mask: 单句子attention_mask
:param batch_token_type_ids: 单句子token_type_ids
:param batch_pair_input_ids: 句对token序列
:param batch_pair_attention_mask: 句对attention_mask
:param batch_pair_token_type_ids: 句对token_type_ids
:return:
"""
# Recognizer Teacher
single_output = self.mbert(input_ids=batch_token_input_ids, attention_mask=batch_attention_mask,
token_type_ids=batch_token_type_ids).last_hidden_state
single_output = F.softmax(self.fc(single_output), dim=-1)
# Evaluator Teacher(类似双塔模型)
pair_output1 = self.mbert(input_ids=batch_pair_input_ids[0], attention_mask=batch_pair_attention_mask[0],
token_type_ids=batch_pair_token_type_ids[0]).last_hidden_state
pair_output2 = self.mbert(input_ids=batch_pair_input_ids[1], attention_mask=batch_pair_attention_mask[1],
token_type_ids=batch_pair_token_type_ids[1]).last_hidden_state
pair_output = torch.sigmoid(torch.cosine_similarity(pair_output1, pair_output2, dim=-1)) # 计算两个输出的cosine相似度
if training:
# 计算loss, 训练时采用平均loss作为模型最终的loss
loss1 = F.cross_entropy(single_output.view(-1, self.num_labels), batch_labels.view(-1))
loss2 = F.binary_cross_entropy(pair_output, batch_t.type(torch.float))
loss = loss1 + loss2
return single_output, loss
else:
return single_output, pair_output
class StudentNER(BertPreTrainedModel):
def __init__(self, config, num_labels):
"""
student模型采用的也是一个双塔结构
:param config: mBert的配置文件
:param num_labels: 标签数量
"""
super(StudentNER, self).__init__(config)
self.config = config
self.num_labels = num_labels
self.mbert = BertModel(config=config)
self.fc1 = nn.Linear(config.hidden_size, num_labels)
self.fc2 = nn.Linear(config.hidden_size, num_labels)
def forward(self, batch_pair_input_ids, batch_pair_attention_mask, batch_pair_token_type_ids, batch_pair_labels,
teacher_logits, teacher_similar):
"""
:param batch_pair_input_ids: 句对token序列
:param batch_pair_attention_mask: 句对attention_mask
:param batch_pair_token_type_ids: 句对token_type_ids
:return:
"""
output1 = self.mbert(input_ids=batch_pair_input_ids[0], attention_mask=batch_pair_attention_mask[0],
token_type_ids=batch_pair_token_type_ids[0]).last_hidden_state
output2 = self.mbert(input_ids=batch_pair_input_ids[1], attention_mask=batch_pair_attention_mask[1],
token_type_ids=batch_pair_token_type_ids[1]).last_hidden_state
soft_output1, soft_output2 = self.fc1(output1), self.fc2(output2)
soft_logits1, soft_logits2 = F.softmax(soft_output1, dim=-1), F.softmax(soft_output2, dim=-1)
alpha1, alpha2 = torch.square(torch.max(input=soft_logits1, dim=-1)[0]).mean(), torch.square(
torch.max(soft_logits2, dim=-1)[0]).mean()
output_similar = torch.sigmoid(torch.cosine_similarity(soft_output1, soft_output2, dim=-1))
soft_similar = torch.sigmoid(torch.cosine_similarity(soft_logits1, soft_logits2, dim=-1))
beta = torch.square(2 * output_similar - 1).mean()
gamma = 1 - torch.abs(soft_similar - output_similar).mean()
# 计算蒸馏的loss
# teacher logits与student logits1 的loss
loss1 = alpha1 * (F.cross_entropy(soft_logits1, teacher_logits))
# teacher similar与student similar 的loss
loss2 = beta * (F.binary_cross_entropy(soft_similar, teacher_similar))
# teacher logits与student logits2 的loss
loss3 = alpha2 * (F.cross_entropy(soft_logits2, teacher_logits))
# final loss
loss = gamma * (loss1 + loss2 + loss3).mean()
return loss
if __name__ == "__main__":
from transformers import BertConfig
pretarin_path = "./pytorch_mbert_model"
batch_pair1_input_ids = torch.randint(1, 100, (2, 128))
batch_pair1_attention_mask = torch.ones_like(batch_pair1_input_ids)
batch_pair1_token_type_ids = torch.zeros_like(batch_pair1_input_ids)
batch_labels1 = torch.randint(1, 10, (2, 128))
batch_labels2 = torch.randint(1, 10, (2, 128))
# t(对比两个序列标签,相同为1,不同为0)
batch_t = torch.as_tensor(batch_labels1.numpy() == batch_labels2.numpy()).float()
batch_pair2_input_ids = torch.randint(1, 100, (2, 128))
batch_pair2_attention_mask = torch.ones_like(batch_pair2_input_ids)
batch_pair2_token_type_ids = torch.zeros_like(batch_pair2_input_ids)
batch_all_input_ids, batch_all_attention_mask, batch_all_token_type_ids, batch_all_labels = [], [], [], []
batch_all_labels.append(batch_labels1)
batch_all_labels.append(batch_labels2)
batch_all_input_ids.append(batch_pair1_input_ids)
batch_all_input_ids.append(batch_pair2_input_ids)
batch_all_attention_mask.append(batch_pair1_attention_mask)
batch_all_attention_mask.append(batch_pair2_attention_mask)
batch_all_token_type_ids.append(batch_pair1_token_type_ids)
batch_all_token_type_ids.append(batch_pair2_token_type_ids)
config = BertConfig.from_pretrained(pretarin_path)
# teacher模型训练
teacher_model = TeacherNER.from_pretrained(pretarin_path, config=config, num_labels=10)
outputs, loss = teacher_model(batch_token_input_ids=batch_pair1_input_ids,
batch_attention_mask=batch_pair1_attention_mask,
batch_token_type_ids=batch_pair1_token_type_ids, batch_labels=batch_labels1,
batch_pair_input_ids=batch_all_input_ids,
batch_pair_attention_mask=batch_all_attention_mask,
batch_pair_token_type_ids=batch_all_token_type_ids,
training=True, batch_t=batch_t)
# student 模型蒸馏
teacher_logits, teacher_similar = teacher_model(batch_token_input_ids=batch_pair1_input_ids,
batch_attention_mask=batch_pair1_attention_mask,
batch_token_type_ids=batch_pair1_token_type_ids,
batch_labels=batch_labels1,
batch_pair_input_ids=batch_all_input_ids,
batch_pair_attention_mask=batch_all_attention_mask,
batch_pair_token_type_ids=batch_all_token_type_ids,
training=False)
student_model = StudentNER.from_pretrained(pretarin_path, config=config, num_labels=10)
loss_all = student_model(batch_pair_input_ids=batch_all_input_ids,
batch_pair_attention_mask=batch_all_attention_mask,
batch_pair_token_type_ids=batch_all_token_type_ids,
batch_pair_labels=batch_all_labels, teacher_logits=teacher_logits,
teacher_similar=teacher_similar)
print(loss_all)
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧




