ECCV2022|腾讯优图开源DisCo:拯救小模型在自监督学习中的效果

极市导读
本文通过解读DisCo,一种基于蒸馏的轻量化模型的自监督学习方法,解释作者如何实现从Teacher到Student更有效的知识迁移,进而显著提升轻量化模型的效果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言

Motivation
-
基于自监督的蒸馏学习,因为最后一层的表征包含了不同样本的在整个表征空间中的全局的绝对位置和局部的相对位置信息,而Teacher中的这类信息比Student更加的好,所以直接拉近Teacher与Student最后一层的表征可能是效果最好。
-
在CompRess [1] 中,Teacher 与 Student 模型共享负样本队列(1q) 与拥有各自负样本队列(2q) 差距在1%内。该方法迁移到下游任务数据集CUB200, Car192,该方法拥有各自的负样本队列甚至可以显著超过共享负样本队列。这说明,Student并没有从Teacher共享的负样本空间学习中获得足够有效的知识。Student不需要依赖来自Teacher的负样本空间。
-
放弃共享队列的好处之一,是整个框架不依赖于MoCo-V2,整个框架更加简洁。Teacher/Student 模型可以与其他比MoCo-V2更加有效的自监督/无监督表征学习方法结合,进一步提升轻量化模型蒸馏完的最终性能。
-
目前的自监督方法中,MLP的隐藏层维度较低可能是蒸馏性能的瓶颈。在自监督学习与蒸馏阶段增加这个结构的隐藏层的维度可以进一步提升蒸馏之后最终轻量化模型的效果,而部署阶段不会有任何额外的开销。将隐藏层维度从512->2048,ResNet-18可以显著提升3.5%。
Method
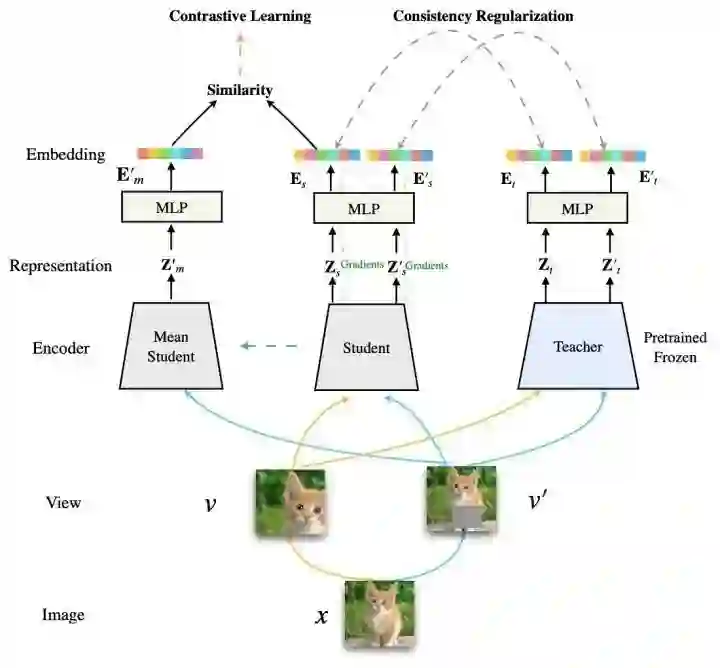
Experiments
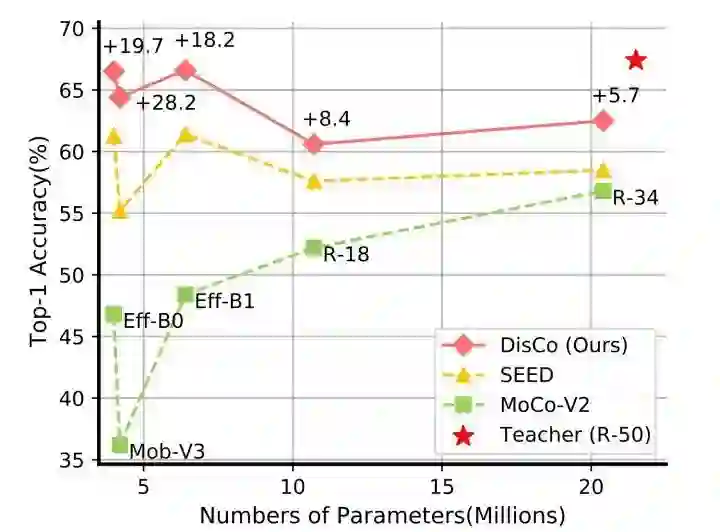
-
表征泛化能力
-
迁移到下游分类任务:Cifar10/100 -
迁移到检测/分割任务:VOC07,COCO2012 -
DisCo相比已有蒸馏方法,能更好的拉近Teacher与Student的表征分布。同时,与已有的蒸馏方法结合,能进一步提升蒸馏效果
-
半监督学习下的表现
-
消融实验:两部分损失函数的影响
-
其他实验:
-
Teacher采用其他的自监督学习方法的影响,包括CNN/Transformer 差异的影响 -
Student/Teacher同时采用其他的自监督学习方法的影响
Visualization
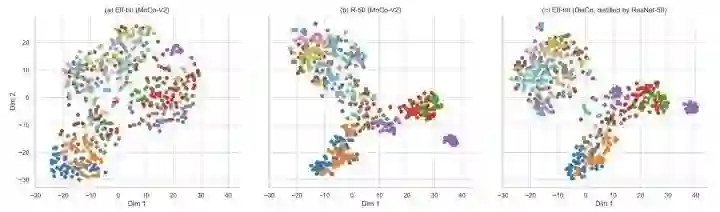
Conclusion
Soroush Abbasi Koohpayegani, Ajinkya Tejankar, and Hamed Pirsiavash. Compress: Self-supervised learning by compressing representations. In NeurIPS, pages 12980– 12992, 2020.
Zhiyuan Fang, Jianfeng Wang, Lijuan Wang, Lei Zhang, Yezhou Yang, and Zicheng Liu. Seed: Self-supervised distillation for visual representation. In ICLR, 2021.
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, pages 9729–9738, 2020.
Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. In CVPR, pages 9729–9738, 2020.
Hao Cheng, Dongze Lian, Shenghua Gao, and Yanlin Geng. Evaluating capability of deep neural networks for image classification via information plane. In ECCV, pages 168–182, 2018.
公众号后台回复“项目实践”获取50+CV项目实践机会~

“
点击阅读原文进入CV社区
收获更多技术干货

