必看,10篇定义计算机视觉未来的论文

译者 | Major
编辑 | 赵雪
出品 | AI科技大本营(ID:rgznai100)
导语:如果你没能参加 CVPR 2019 , 别担心。本文列出了会上人们最为关注的 10 篇论文,覆盖了 DeepFakes(人脸转换), Facial Recognition(人脸识别), Reconstruction(视频重建)等等。
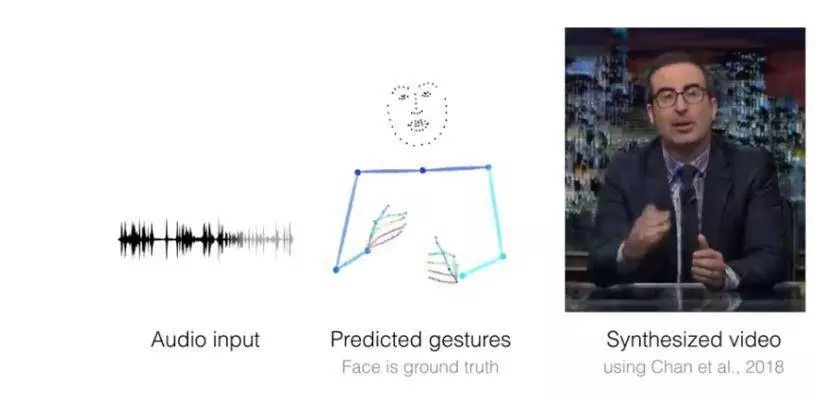
1.Learning Individual Styles of Conversational Gesture (学习对话姿势中的个体风格)
原文链接:
https://www.profillic.com/paper/arxiv:1906.04160
摘要:对于给定的语音音频输入,它们会生成合理的姿势,来配合声音并合成讲者的相应视频。
使用的模型/架构:语音到姿势转换模型(Speech to gesture translation model)。采用一个卷积音频编码器下采样 2D 语谱图并转换为 1D 信号。接着翻译模型 G 预测一个相应的 2D 姿势时序栈。回归到真实姿势的 L1 提供一个训练信号,与此同时,采用一个对抗判别器 D ,确保所预测姿势和讲者风格一致。
模型精确度:研究人员对基准和实际姿势序列的语音和姿势转换结果进行了定量比较(作者们展示的表格表明新模型损耗较低, PCK 较高)。
使用的数据集: 从 Youtube 上查询得到的针对讲者的姿势数据集。总共采用了 144 小时的视频。其中,80% 用于训练,10% 用于验证,10% 用于测试集,这样每段源视频只出现在一个数据集中。
2.Textured Neural Avatars(神经元模型贴图)
原文链接:
https://www.profillic.com/paper/arxiv:1905.08776
摘要:研究人员提出了一个学习全身神经元贴图的系统(即深层网络),通过不同的身体姿势和相机位置产生一个人的全身效果图。这个自由视角渲染的人体神经元模型无需 3D 显式形状建模。
使用的模型/架构:神经元贴图系统概览。输入姿势对应为一个 “骨骼” 光栅堆栈(一个骨骼对应一个通道)。输入一个全卷积网络(生成器)进行处理,产生肢体定位映射堆栈和肢体协调映射堆栈。这些堆栈用来在肢体协调映射堆栈指定的位置采样身体纹理图,从而产生 RGB 图像。此外,最后的身体定位堆栈图也对应了背景可能性。在学习过程中,遮罩和 RGB 图像与真实姿势进行比较,产生的损失通过采样操作后向传播到全卷积网络和纹理上,使它们进行更新。
模型精确度:就 SSIM(自相似度)指标而言,表现得比其他两个模型更好;在 FID( Frechet 感知距离)指标上的表现比 V2V 表现更差。
使用的数据集:
CMU Panoptic 数据集的 2 个子集
我们自己使用 7 台摄像机对 3 个对象采集的多角度序列,其视角范围大约在 30 度。还有另一文章和 Youtube 上的 2 个单眼短序列。

3.DSFD: Dual Shot Face Detector(DSFD: 双向人脸检测器)
原文链接:
https://www.profillic.com/paper/arxiv:1810.10220
摘要:作者提出了一个创新的人脸检测神经网络,有3个全新的贡献,解决了人脸识别的三个关键方面,包括更好的特征学习、渐进的损失设计,以及基于数据增强的主角指定。
使用的模型/架构:DSFD 框架在一个前向 VGG/ResNet 架构的顶层采用了一个特征增强模块,从原有的特征中产生增强特征,该框架还采用了两个损失层,分别是针对原有特征的名为 first shot PAL 的损失层,和针对增强特征的名为 second shot PAL 的损失层。
模型精确度:在流行的 benchmark(WIDER FACE 和 FDDB )上进行的大量实验表明了与现有的检测器如 PyramiBox 和 SRN 相比,DSFD 具有优越性。
使用的数据集:WIDER FACE 和 FDDB

4.GANFIT: Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction (GANFIT:匹配高保真3D人脸重建的对抗生成网络)
原文链接:
https://www.profillic.com/paper/arxiv:1902.05978
摘要:文中提出的深度匹配方法可以从一个图像重建高质量纹理和几何特征,可准确进行身份重现。文中其它地方的重建采用一个 700 浮点数规模的向量表示,并无须采用任何特效进行渲染 ( t 产生的纹理通过模型重建,而没有从图像中直接提取特征 )。
使用的模型/架构:采用一个差分渲染器进行 3D 人脸重建。成本函数主要通过预训练人脸识别网络上的身份特征来确定,并通过梯度下降优化将误差一路返回到潜在参数来优化。端到端可微结构使我们能够使用从计算上来说既廉价又可靠的一阶导数进行优化,因此使用深层网络作为生成器(即统计模型)或作为成本函数具有了可能性。
模型精确度:采用点面距离从 MICC 数据集上获得精确性数据。下表给出的均方差 ( Mean )和标准差( Std. )是该模型最低的。
使用的数据集: MoFA-Test、MICC、Wild ( LFW ) 数据集中带标签的面部、BAM 数据集。

5.DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images (DeepFashion2:服装图像检测、动作评估、分割和重新识别的通用基准)
原文链接:
https://www.profillic.com/paper/arxiv:1901.07973
摘要:Deepfashion 2 提供了一个用于服装图像检测、动作评估、分割和重新识别的通用基准。
使用的模型/架构:Match R-CNN 包含了三个主要的组件:特征提取网络 ( FIN )、感知网络( PN )和匹配网络( MN )。
模型精确度:与真实服装相比,Match R-CNN 达到了前 20 的精确度(低于 0.7 ),说明检索基准很有挑战性。
使用的数据集:DeepFashion2 数据集包含了 491K 各类图像,涵盖商业销售库存服装和消费者中的19 类流行服装。

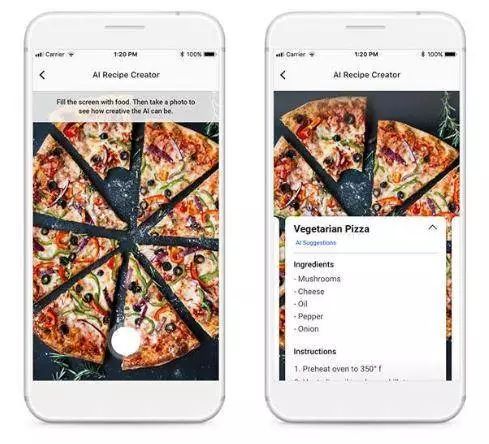
6.Inverse Cooking: Recipe Generation from Food Images(反向烹饪:从食物图像生成配方)
原文链接:
https://www.profillic.com/paper/arxiv:1812.06164
摘要:Facebook 研究人员采用AI从食物图像中生成食谱。
使用的模型/架构:配方生成模型-作者用图像编码器提取图像特征。由成分解码器( Ingredient Decoder)预测成分,并用成分编码器( Ingredient Encoder)编码到成分嵌入中。烹饪指令解码器通过处理图像嵌入、成分嵌入和先前预测的单词,生成食谱标题和烹饪步骤序列。
模型精确度:用户研究结果表明,相对于最先进的图像-配方检索方法,他们的系统具有优势。(优于人工评估和基于检索的系统,获得 49.08% 的 F1 ,良好的 f1 分数意味着错判假阳性和假阴性较低)。
使用的数据集:他们在大规模 Recipe1M 数据集上对整个系统进行评估。
7.ArcFace: Additive Angular Margin Loss for Deep Face Recognition(ArcFace:用于深度人脸识别的附加角度边缘损失)
原文链接:
https://arxiv.org/pdf/1801.07698.pdf
摘要:ArcFace 可以获得更具鉴别力的深度特征,并以可重现的方式在 MegaFace Challenge 中有出色的表现。
使用的模型/架构:为增强类内紧凑性和类间差异性,本文提出附加角度边缘损失(ArcFace),在取样和中心之间加入了一个测地距离边缘。这是出于提高人脸识别模型的识别能力考虑。
模型精确度:综合实验报告表明,ArcFace 始终优于当前最新的模型.
使用的数据集:采用了 CASIA、VGGFace2、MS1MV2 和 DeepGlint-Face (包括 MS1M-DeepGlint 和 Asian-DeepGlint ) 作为训练集,以确保与其他模型进行公平的比较。使用的其它数据集包括:LFW、CFP-FP、AgeDB-30、CPLFW、CALFW、YTF、MegaFace、IJB-B、IJB-C、Trillion-Pairs、iQIYI-VID

8.Fast Online Object Tracking and Segmentation: A Unifying Approach (快速在线对象跟踪和分割:归一化方法)
原文链接:
https://www.profillic.com/paper/arxiv:1812.05050
摘要:通过利用二进制分割任务增强损失,这种名为 SiamMask 的方法改进了用于对象跟踪的流行的全卷积 Siamese 方法的离线训练过程。
使用的模型/架构:SiamMask 的目标是视觉跟踪和视频分割的交叉点,实现更高的实用性。与传统的对象跟踪器相似,它依赖于简单的边界框初始化并在线操作。与 ECO 等最先进的跟踪器不同,SiamMask 能够生成二进制分割遮罩,从而更准确地描述目标对象。SiamMask 有两种变体:三分支结构、两分支结构(有关更多详细信息请参阅论文)。
模型精确度:论文中给出了 SmiaMask 的定量结果,分别针对 VOT(视觉对象跟踪)和DAVIS( Densely 标引视频分割)序列。SiamMask 即使在速度很快或有干扰的情况也能产生精确的分割遮罩。
使用的数据集:VOT2016、VOT-2018、DAVIS-2016、DAVIS-2017和 YouTube-VOS。

9.Revealing Scenes by Inverting Structure from Motion Reconstructions (在动作重建中插入结构再现场景)
原文链接:
https://www.profillic.com/paper/arxiv:1904.03303
摘要:微软的研究团队和合作研究人员从点云中重建了场景的彩色图像。
使用的模型/架构:该方法基于一个作为输入的级联 U-NET,从包含点深度,可选颜色和 SIFT描述符的特定视点渲染点的二维多通道图像,并从该视点输出场景的彩色图像。
他们的网络有3个子网络——VISIBNET、 COARSENET 和 REFINENET。网络输入是一个多维的 ND 阵列。本文探讨了网络变量,输入的是深度、颜色和筛选描述符的不同子集。这 3 个子网络具有相似的架构。它们是具有对称跳跃连接的编码器和解码器层的 U-UNet 。解码器层末端的额外层有助于高维输入。
模型精确度:本文表明,可以从存储的有限信息量和稀疏的三维点云模型体系结构中重建高质量图像(有关更多详细信息,请参阅论文)。
使用的数据集:在700 多个户内和户外 Sfm 重建图像上进行,这些图像是从 NYU2 的MagaDepth 数据集中的 50 多万多角度图像中产生的。

10.Semantic Image Synthesis with Spatially-Adaptive Normalization (空间自适应正则化语义图像合成)
原文链接:
https://www.profillic.com/paper/arxiv:1903.07291
摘要:把涂鸦变成令人惊叹的照片写实的风景!Nvidia Research 利用生成对抗网络创建高度逼真的场景。艺术家可以使用画笔和颜料筒工具设计河流、岩石和云等专属于自己的风景。
使用的模型/架构:
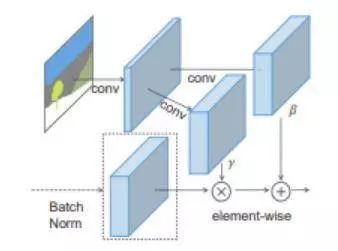
在 SPADE 中,首先将遮罩影射到嵌入空间上,然后进行卷积以产生调制参数 γ 和 β 。与以前的条件归一化方法不同,γ 和 β 不是向量,而是具有空间维度的张量。将产生的 γ 和 β 相乘并按顺序添加到归一化激活元素中。
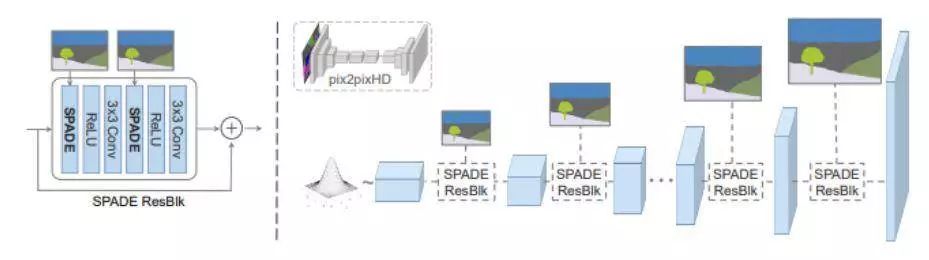
在 SPADE 发生器中,每个正则层采用分割遮罩来对层活动建模,(左侧)是采用 SPADE 的一个残差模块,(右侧)发生器包含了一系列带有上采样层的 SPADE 残差模块。
模型精确度:这个体系结构通过较少的参数移除主图像到图像转换网络的降采样层,以实现更好的性能。我们的方法成功地在动物到体育活动的不同场景中生成了逼真的图像。
使用的数据集:COCO-Stuff、ADE20K、Cityscapes 和 Flickr Landscape

原文链接:
https://hackernoon.com/top-10-papers-you-shouldnt-miss-from-cvpr-2019-deepfake-facial-recognition-reconstruction-and-more-d5ly3q1w
◆
精彩推荐
◆


社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五 更新学习资源、技术福利,还有抽奖活动~

推荐阅读
从ACM班、百度到亚马逊,深度学习大牛李沐的开挂人生
最前沿:堪比E=mc2,Al-GA才是实现AGI的指标性方法论
1万+字原创读书笔记,机器学习的知识点全在这篇文章里
开源之战
别再造假数据了,来试试Faker这个库吧!
国外大神制作的超棒NumPy可视化教程
白话中台战略:中台是个什么鬼?
伟创力回应扣押华为物资;谷歌更新图片界面;Python 3.8.0b3 发布 | 极客头条
沃尔玛也要发币了,Libra忙活半天为他人做了嫁衣?