学界 | OpenAI 发布稀疏计算内核,更宽更深的网络,一样的计算开销

作者:杨晓凡
概要:OpenAI 的研究人员们近日发布了一个高度优化的 GPU 计算内核,它可以支持一种几乎没被人们探索过的神经网络架构:带有稀疏块权重的网络。
OpenAI 的研究人员们近日发布了一个高度优化的 GPU 计算内核,它可以支持一种几乎没被人们探索过的神经网络架构:带有稀疏块权重的网络。取决于不同的稀疏程度,这些内核的运行速度可以比 cuBLAS 或者 cuSPARSE 快一个数量级。OpenAI 的研究人员们已经通过这些内核在文本情感分析和文本图像的生成中得到了顶尖的成果。
在深度学习领域,模型架构和算法的开发很大程度上受制于 GPU 对基础计算操作的支持到什么程度。具体来说,其中有一个问题就是通过 GPU 实现稀疏线性操作时计算效率太低。OpenAI 这次发布的计算内核就是为了支持这个的,同时也包含一些实现的多种稀疏模式的初期成果。这些成果已经展示出了一些潜力,不过还算不上是决定性的证据。OpenAI 的研究人员们也邀请更多深度学习领域的研究人员一起参与,携手继续改进这个计算内核,让更多的计算架构变得可能。
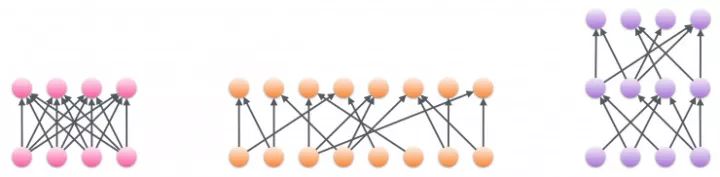
密集连接的层(左侧)可以用稀疏的、更宽的层(中间)或者稀疏的、更深的层(右侧)替代,而计算时间几乎不变
稀疏权重矩阵与密集权重矩阵有明显的不同,就是其中的很多值都是零。稀疏权重矩阵是许多模型所向往的基础部件,因为有稀疏的块参与的矩阵乘法和卷积操作的计算成本只是和块中非零数字的数目成比例而已。稀疏性的一个明显的好处,就是在给定的参数数目和计算资源限制下可以训练比别的方法宽得多、深得多的神经网络,比如实现带有上万个隐层神经元的LSTM网络(当下能训练的LSTM只有上千个隐层神经元而已)。
计算内核

密集权重矩阵(左)、稀疏块权重矩阵(中)的示意图。白色的区域意味着权重矩阵中对应的位置是0
这个计算内核可以让全连接和卷积层高效地利用稀疏块权重。对于卷积层来说,这个内核的输入和输出特征维度都可以是稀疏的;而空间维度中的连接性不受到任何影响。稀疏性的定义是在块的级别上定义的(如上右图),而且为大小为 8x8、16x16、32x32 的块做了优化(在这里展示的就是 8x8 的块)。在块的级别上,稀疏模式是完全可以自己配置的。由于这个内核在计算时会直接跳过值为 0 的块,所以消耗的计算资源就只和非零的权重的数目成正比,而不是像以往一样和输出/输出特征的数目成正比。存储这些参数的开销同样和非零的权重的数目成正比。
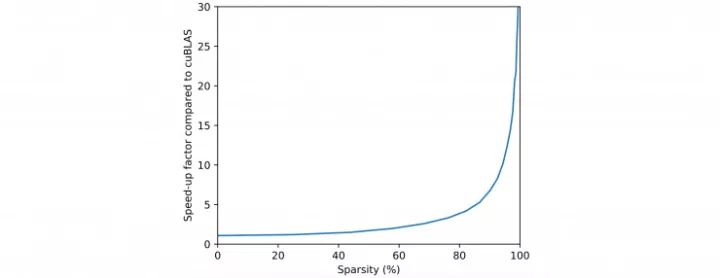
与 cuBLAS 相比,这个内核在不同稀疏比例下的加速倍数。测试条件:很宽的神经网络(12288 个隐层神经元),块大小为 32x32,mini-batch 大小为 32;测试硬件为 NVIDIA Titan X Pascal GPU,CUDA 版本为 8.0。在测试的这些稀疏比例下,相比 cuSPARSE 的速度提升比例还要高一些。
应用这个计算内核
OpenAI 的研究人员们也展示了一些在TensorFlow中进行稀疏矩阵乘法的示例代码
from blocksparse.matmul import BlocksparseMatMul
import tensorflow as tf
import numpy as np
hidden_size = 4096
block_size = 32
minibatch_size = 64
# Create a (random) sparsity pattern
sparsity = np.random.randint(2, size=(hidden_size//block_size,hidden_size//block_size))
# Initialize the sparse matrix multiplication object
bsmm = BlocksparseMatMul(sparsity, block_size=block_size)
# Input to graph
x = tf.placeholder(tf.float32, shape=[None, hidden_size])
# Initialize block-sparse weights
w = tf.get_variable("w", bsmm.w_shape, dtype=tf.float32)
# Block-sparse matrix multiplication
y = bsmm(x, w)
# Run
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
result = sess.run([y], feed_dict = {x: np.ones((minibatch_size,hidden_size), dtype='float32')})
print(result)
微缩 LSTM
稀疏块内核有一种非常有意思的用途,就是用来创建微缩神经网络。微缩图之间可以进行连接,图中的任意两个节点都只需要很少的几个步骤就可以连接起来,即便整张图有数十亿个节点也可以。OpenAI的研究人员们想要实现这样的微缩连接性的原因是,即便网络是高度稀疏的,他们仍然希望信息可以在整张图中快速传播。人类大脑就显示出了微缩连接模式,从而也带来了「如果LSTM有同样的特性,它的表现能否有所提高」的问题。通过微缩稀疏连接性的应用,OpenAI 的研究人员们高效地训练了带有大约 2 万个隐层神经元的 LSTM 模型,同时网络的宽度也要比参数总数目类似的网络宽 5 倍。训练后的网络在文本生成建模、半监督情感分类上都有更好的表现。

在微缩图中,即便稀疏程度很高的情况下节点之间也只需要很少的步数就可以互相连接。上面动图里显示的是从二维 Watts-Strogatz 微缩图中,中央的节点(像素)向外激活的情况;另外为了更好的观感做了随机的平滑。在这张图中,不同节点之间路径长度的平均值小于5,和 OpenAI 研究员们的 LSTM 实验中 Barabasi-Albert 图的状况类似。
情感表征学习
OpenAI 的研究人员们训练了参数数目差不多的稀疏块权重网络和密集权重矩阵网络,对比它们的表现。稀疏模型在所有的情感数据集上都取得了更好的表现。在 IMDB 数据集上,OpenAI 的这个稀疏模型把此前最好的 5.91% 错误率大幅降低到了 5.01%。相比 OpenAI 此前一些实验中只在短句上有好的表现,这次在长句中也显示出了有潜力的结果。
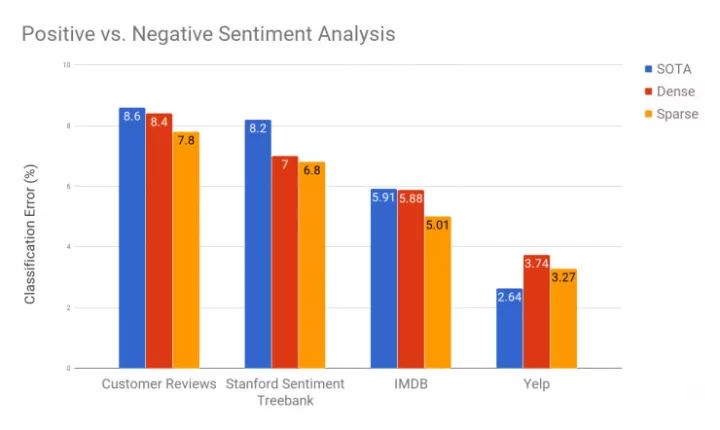
基于生成式密集和稀疏模型提取的特征训练的线性模型的情感分类结果。这里的密集和稀疏模型有几乎相等的参数数目。
压缩任务的表现
借助稀疏的、更宽的 LSTM 模型,比特数每字符的压缩结果在实验中从 1.059 进步到了 1.048,同样是在具有差不多的参数数目的模型上达到的。带有稀疏块的线性层架构如果换成密集连接的线性层,这个结果也可以得到进一步的提高。OpenAI 的研究人员们在用于 CIFAR-10 的 PixelCNN++ 模型上做了一个简单的修改,把正常的 2D 卷积核换成了稀疏核,同时把网络变得更深的同时保持其它的超参数不变。修改之后的网络也把比特数每维度的数值从 2.92 降低到了 2.90,达到了这个数据集上的最好结果。
未来研究方向
神经网络中的多数权重在训练结束后都可以剪枝。如果让剪枝动作配合此次的稀疏内核使用,那推理时能节省多少计算时间、提高多少计算速度呢?
在生物大脑中,网络的稀疏结构有一部分是在成长时确定的(成长的另一个作用是改变连接强度)。人造神经网络中是否也能有类似的做法呢,就是不仅通过梯度学习连接权重,同时还学习最优的稀疏结构?近期有一篇论文就提出了一种学习稀疏块 RNN 的方法,OpenAI 最近也提出了一个算法用来在神经网络中做 L0 规范化,两者都可以在这个方向上起到作用。
OpenAI 的研究人员们这次训练了带有上万个隐层神经元的 LSTM 模型,带来了更好的文本建模表现。那么更广泛地说,带有很大的权重矩阵的模型如果用了稀疏层,就可以保持与更小的模型一样的参数数目和计算开销。相信一定有一些领域能让这种方法发挥很大的作用。
未来智能实验室致力于研究互联网与人工智能未来发展趋势,观察评估人工智能发展水平,由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎支持和加入我们。扫描以下二维码或点击本文左下角“阅读原文”





