Arxiv Insights | 克服稀疏奖励的束缚,让智能体在学习中成长

喜欢机器学习和人工智能,却发现埋头苦练枯燥乏味还杀时间?油管频道 Arxiv Insights 每期精选,从技术视角出发,带你轻松深度学习。
翻译/赵若伽 整理/MY

在强化学习的设置中,为了执行一个我们想学习的任务,智能体会应用一些特征提取方案来从原始数据中提取有用信息,然后会有一个策略网络用于提取特征。
我们常常觉得强化学习很难,而让它变难的原因是我们使用了稀疏奖励。智能体需要从反馈中去学习,然后分辨什么样的动作序列会导致最终的奖励,但事实上我们的反馈信号很稀疏,以至于智能体无法从原始数据中提取有用特征。
当前强化学习中有一个主流的趋势,即放大从游戏环境中得到的稀疏的外部奖励信号,并通过额外的反馈信号帮助智能体学习。我们希望建立一个可监督设置并设计非常密集的额外的反馈信号,一旦智能体在任务中成功,它可能将会得到知识。
本文希望通过对一些文章的阐述和分析来为大家提供一些现有研究通用的、方向性的观点。
一. 设置辅助任务
第一个观点是辅助任务会帮忙训练你的智能体,这些简单目标的叠加可以显著提高我们智能体的学习效率。我们来一起看一篇来自google deepmind的文章,叫做强化学习结合无监督学习辅助任务。

这篇文章建立了一个3D迷宫,智能体在迷宫里行走,它需要找到具体的对象,一旦它遇到这些对象之一就会得到奖励。作者们替换掉了这些很稀疏的奖励,并用三个额外奖励信号来放大整个训练过程。
第一个任务是像素控制。智能体需要学习一个独立策略去最大化改变输入图片的某些地方的像素值,在他们建议的实现方法中输入的帧被分成少量的栅格,每个栅格计算一个视觉变化分数,然后策略被训练成最大化所有栅格的总视觉变化。像素控制任务的加入在三维环境中是很有效的。
第二个辅助任务是奖励预测。智能体被给与在片段序列(episode sequence)中三个最近的帧,他的任务是预测下一步会给出的奖励。
第三个任务是估值函数回放。通过预测,智能体将会得到在这一时刻往前的未来奖励的总和。
二. 好奇驱使探索
第二个观点是好奇驱使探索,通俗的观点是你希望以某种方式奖励你的智能体,在它学习了一件探索环境后发现的新事情之后。
在大多数默认的强化学习的算法里,人们会用ε-贪婪探索的方法,也就是说在大部分的情况下你的智能体会根据他现有的策略选择最好最有可能的方向,在小概率 ε 的情况下智能体将会执行一个随机动作,并且随着训练的进展,这个随机动作会逐渐减少直到完全遵循你的决策。也正是因此,你的智能体可能不会为了寻找更好的策略而完全探索整个环境。
在强化学习中我们会召回一个前向模型,这意味着你的智能体将会看到具体的输入帧,它将会使用某种特征提取器并把输入数据编码为某种隐藏的表示法,然后你就有了一个前向模型。如果是一个全新的位置,智能体的向前模型可能不会那么精确,你可以将这些预测误差作为一个除了稀疏奖励之外的额外反馈信号,来鼓励你的智能体去探索状态空间未知的区域。
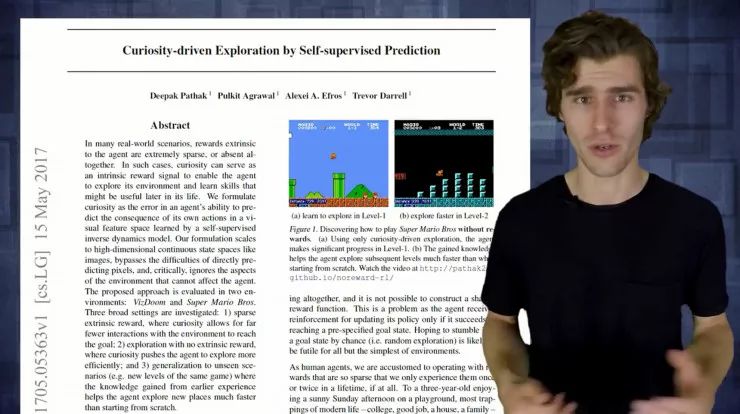
下面我想介绍的一篇文章,作者使用了一个很好的例子来展示intrinsic curiosity module(ICM)。
我们都知道给微风建立模型是很难的,更不用说预测每一片叶子的像素变化。树叶的运动不能被智能体的动作控制,对于特征编码器来说没有激励去引导它为那些树叶建模,这意味着对像素空间的预测误差将会一直很高,智能体将会对叶子一直保持着好奇,这就是论文里 ICM 模型的架构。

原始的环境状态 s 和 s+1 首先被编码进特征空间,接下来是两个模型:一个是前向模型,这个模型为了下一个状态去预测特征通过被策略选择的动作,接下来有一个反转模型来预测应该选择什么动作才能从状态s到下一个特征状态 s+1。最后 s+1 的特征编码和通过前向模型给予的 s+1 的预测特征编码进行比较,比较出来的结果我们可以称它为智能体对发生的事情的惊讶程度,被加到奖励信号里为了训练智能体。
这是一个很好的观点,我们的智能体应该去探索未知区域并对世界保持好奇心。
三. 标准奖励设置
第三个观点的标准奖励设置,让智能体从不成功的片段中学习。我们可以看 open AI最近发的一篇文章,叫作后经验回放,或者缩写 HER。

想象你要训练一个机械手来推动桌子上的一个物体到达位置 A,但是由于策略没有训练的很好,物体结束在 B,按目标来看是不成功的尝试,而HER模型做的不是仅仅说“嘿!你做错了,你得到了一个值为 0 的奖励”,而是告诉智能体“真棒!做的好,这是你如何移动物体到位置 B ”,基本上你已在一个稀疏奖励的问题中建立了非常密集的奖励设置来让智能体学习。
我们以一个普通的离线学习算法和为了采样目标位置的策略为开始,但是接下来我们也采样了一系列被改变的额外的目标。这个算法最好的一点是在训练之后你已经有了一个策略网络,所以如果你希望移动物体到一个新的位置,你不需要重新训练所有策略,只需要改变目标向量,你的策略会做出正确的事情。这篇论文的观点很简单,但是解决了我们学习中一个非常基础的问题,就是我们希望最大化地使用我们有的每一个经验。

我们刚刚分享了一些非常不同的方式去增加稀疏奖励信号,通过密集的反馈我认为在第一步趋向于真正的无监督学习。但是在强化学习中还是有很多挑战性的问题,例如像泛化迁移学习、物理学中的因果关系等,这些问题依旧作为挑战而存在。与此同时,我们也需要更好的平衡人工智能的发展与社会发展之间的关系,创造一个每个人都能从人工智能的发展中获益的事业。
视频链接:
https://www.youtube.com/watch?v=0Ey02HT_1Ho&t=364s

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
呵,我复现一篇深度强化学习论文容易吗
▼▼▼





