基于多特征多核哈希学习的大规模图像检索丨重邮王国胤团队

基于多特征多核哈希学习的大规模图像检索
曾宪华1,2* ,袁知洪1,2 ,王国胤1,2 ,杨洁1,2
1. 重庆邮电大学计算机科学与技术学院, 重庆 400065
2. 重庆邮电大学计算智能重庆市重点实验室, 重庆 400065
* 通信作者. E-mail: zengxh@cqupt.edu.cn
摘要:哈希学习方法解决了图像大数据的检索效率低,存储代价高的问题。目前已有的核哈希方法中,要么仅使用一种特征对应单个核函数,要么是多特征对应单个核函数,它们忽视了综合考虑不同的核函数具有的不同作用和不同的特征包含不同的信息的事实。本文提出了一种自适应的多特征多核的哈希学习算法(MFMKH),该算法能够自适应学习多特征融合的权重系数和多核融合的权重系数,将多特征和多核的优点进行了双重融合。本算法中的特征融合解决了单特征所包含的信息量单一不足的问题,采用多种不同的核函数能够弥补单核学习能力上的不足,具有多特征自适应融合和多核学习的双重优点。在标准的IRMA,Ultrasound和Cifar10数据集上的实验表明,本文算法检索性能明显优于同类基于核的哈希学习方法,且与监督的深度哈希相比训练时间显著少的情况下检索性能在Cifar10数据集上是可竞争的。
关键词:维度约减,多特征融合,多核学习,哈希学习,自适应学习,图像检索
引用格式 : 曾宪华 , 袁知洪 , 王国胤 , 等 . 基于多特征多核哈希学习的大规模图像检索 . 中国科学 : 信息科学 , 2017, 47: 1109–1126,
doi: 10.1360/N112016-00307
Large-scale image retrieval based on multi-feature and multi-kernel hashing learning
Xianhua ZENG1,2* , Zhihong YUAN1,2 , Guoyin WANG1,2 & Jie YANG1,2
1. College of Computer Science and Technology, Chongqing University of Posts and Telecommunications, Chongqing 400065, China;
2. Chongqing Key Laboratory of Computational Intelligence, Chongqing University of Posts and Telecommunications, Chongqing 400065, China
* Corresponding author. E-mail: zengxh@cqupt.edu.cn
Abstract:Hashing methods can overcome the problems of low retrieval efficiency and high storage cost. Existing hashing methods use either only one feature or multiple features as the input of one kernel function. The fact that different kernel functions have different roles and different characteristics and contain different information is ignored. In this paper, an adaptive multi-feature and multi-kernel hashing learning (MFMKH) algorithm is proposed, which can adaptively combine the feature weight coefficient and the kernel weight coefficient and double combine the multi-feature and multi-kernel advantages. The fusion of these features in the algorithm solves the disadvantage of single feature containing insufficient information. In addition, the use of a variety of different kernel functions can compensate for the lack of a single-kernel learning ability and has the dual advantages of multi-feature fusion and multi-kernel learning. Experiments on the standard datasets IRMA, Ultrasound, and Cifar10 have shown that the retrieval performance of the proposed method clearly outperforms other similar kernel-based hashing learning methods. In addition, compared to the supervised deep hashing, the retrieval performance of the proposed method is competitive on the Cifar10 dataset in the case of the reduced training time.
Keywords:dimension reduction, multi-feature fusion, multi-kernel learning, hashing learning, adaptive learning, image retrieval
1
引言
在大数据时代,大数据的应用所涉及的领域越来越广。由于大数据的重要性,它已经成为国家重要的战略资源,对大数据的存储、管理和分析也已经成为学术界和工业界高度关注的热点[1,2]。而图像作为大数据信息来源的主要成分,它已成为视觉领域研究的热点。而机器学习技术[3]对于解决大规模图像检索中数据量大、维度高等问题起着关键的作用。
传统的图像检索分为基于文本的图像检索(TBIR)[4]和基于内容的图像检索(CBIR)[5]。如今CBIR是当前图像检索的研究重点,对于CBIR而言,建立低层次图像特征和高层次的语义特征之间的联系是很困难的,检索精度也相对较低。为此,Shao等[4]在2004年提出了一种基于文本和内容的医学图像检索方法,该方法能够将高层次的语义特征和低层次的图像特征结合起来,使得检索效果比仅仅基于内容的图像检索方法要好。He等[6]在2006年提出一种基于广义的流形排序的图像检索方法,通过人工反馈的方法进一步提高了图像检索的精度。Wang等[7]在2008年提出一种基于内容的非对等的流形排序图像检索方法,通过增加可靠数据点的权重,避免噪声的影响从而使得算法更具鲁棒性。然而上述提到的图像检索方法中都不能很好地应用于大规模的图像检索中,当图像数据规模足够大时,它们都面临着存储空间大,检索速度慢等缺点,因此哈希学习方法应运而生。其中一个最著名的哈希方法就是局部感知哈希(LSH)[8],该方法由于采用的是随机映射的方式,因此不能很好地解决线性不可分问题以及“维度灾难”问题。为了解决这个问题,Kulis等[9]在2009提出了基于核的局部敏感哈希(KLSH),将其扩展为能够处理高维空间中的数据;紧接着Raginsky等[10]提出了平移不变性核局部敏感哈希(SKLSH);以及Liu等[11]在2012年提出一种有监督的核哈希方法(KSH),该方法能够巧妙处理哈希码的内积,从而可以更有效地优化汉明距离;考虑到多特征融合的优势,Liu等[12]在2014年提出一种多特征核哈希方法(MFKH)。Li等[13]在2015年提出一种基于标签对的深度监督哈希(DPSH),使用标签对信息使得该深度哈希方法能够同时进行特征学习和哈希编码学习。Liu等[14]在2016年提出一种深度监督哈希方法(DSH),该方法使用卷积神经网络模型,使得最终学到紧凑的相似性保留的哈希码。Shi等[15]在2016年提出一种基于核的离散监督哈希(KSDH),使用非对称松弛策略,使得哈希函数学习和线性函数松弛能够同步进行,从而减少累计的量化误差。在大规模图像检索中,大多数方法的计算时间主要是映射过程,为了能够尽可能地减少存储空间和降低计算代价,Xu等[16]在2017年提出一种监督稀疏哈希(SSH),使用稀疏正则化方法减少映射矩阵的参数数量,避免过拟合问题。Gui等[17]在2017年提出一种快速监督离散哈希(FSDH),采用将训练样本的类别标签回归到相应的哈希码的策略来加速算法,使得FSDH不仅速度快,而且具有很好的检索性能。
哈希学习作为近年来大数据学习的一个研究热点[18],它能够将数据表示成二进制码的形式,不仅能显著减少数据的存储和通信开销,还能降低数据维度,从而显著提高大数据学习系统的效率[19]。近几年,哈希方法在许多计算机视觉[20,21]任务中受到广泛的重视的主要原因在于哈希学习能够降低数据维度,减少存储空间,加快检索速度。
尽管前面提到的这些基于核哈希的方法[9∼12]在视觉检索中取得了很大的进展,但是已有的基于核的哈希方法由于在学习哈希函数的过程中只是利用了某个单一的核函数以及某种特征而使其学习能力受到限制。而现有的多特征哈希方法[22,23]通过融合多种特征虽然已经取得了很好的效果,但是在处理这些多特征的过程中,多特征串联成一种特征一方面会导致特征维度非常高,增加计算量;另一方面无法发现不同特征之间的内在联系。它们都没有综合考虑不同的特征包含着不同的图像信息以及不同的核函数有不同的作用与适用领域1)。
对于上述存在的问题,本文提出一种自适应的多特征多核的哈希学习方法,该方法先将每一种特征映射到不同的核空间中,然后将这些高维核空间的特征进行融合构造出一种多特征多核的哈希学习方法。在该方法中,不同特征和不同核都有不同的权重,这种方法的思想结合了多视图局部线性嵌入方法[24]和多核学习方法[25,26],该方法具有多特征和多核的双重优点。本文的主要创新点在于:
(1)使用基于学习的方法来学习线性组合的核函数中的每一个核函数的比重系数,而非人为设定,从而使该方法中每个核函数的选择具有更高的可信度。
(2)使用基于学习的方法来学习线性组合中的每一种特征的比重系数,从而能够更好地学习到特征之间的关联性以及每种特征的重要程度。
(3)采用的是自适应的学习方法,从而能够自动选择性能较优的核以及效果较好的特征。
2
相关工作
目前,由于医院里每天会产生大量的医学图像,这使得医学图像诊断的相关工作人员的工作压力非常大。虽然现有的CBIR系统在一定程度上缓解了工作人员的压力[24,27],但是该系统无法应用于大规模的医学图像的检索中,而且其精度也有待提高。随着基于哈希学习的图像检索技术的出现,该问题逐渐得到解决。然而这些基于哈希的方法[9∼11]也受到了一些限制,使得哈希函数的学习仅仅是通过单一特征或单一的核函数得到。而多特征的哈希学习方法[22,23]通过融合不同的特征虽然取得了很好的效果,但是这些方法是将这些特征预先串联在一起作为一种特征向量或者是通过简单的线性组合构成一种特征向量。一方面无法充分利用不同的特征之间的作用,另一方面这种将多特征连在一起的方法使得特征维度增大,从而在训练和检索时,计算代价增大。因此将这些方法应用于大规模的维度很高的视觉图像中是不可行的[12]。
谱哈希SH[28]方法的基本思想是将原始数据编码成紧凑的二进制哈希码的同时并在汉明空间中保证原始数据的相似性,该方法可以看作是谱聚类[29]方法的一种扩展。它的目标函数如下:
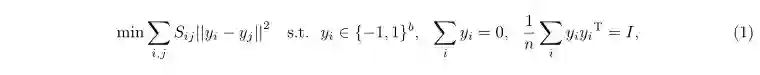
其中Sij表示样本i和j的相似度,yi表示第i个样本的哈希码,b代表哈希码的Bit数。由于式(1)中问题的求解是一个NP难题,通过谱松弛后将离散限制条件转化为连续的就可以通过图的Laplace矩阵特征值分解方法求得最终的解。
另一个相关工作就是多特征核哈希[12],它的基本思想是不同特征对应同一种核,然后再将这些映射后的特征线性组合起来构成一种融合的特征。它的目标函数如下:
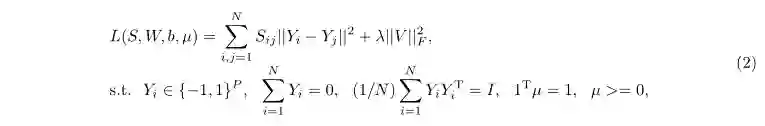
其中Sij表示样本i和j的相似度,N和P分别表示训练样本数与每个样本的哈希码数,Yi表示二进制哈希码矩阵Y中的第i列即第i个样本的哈希码。
从上述论述中可以发现,多特征核哈希[12]只利用核方法将不同特征融合在一起,并没有考虑到同一种特征被映射到不同的核空间后再融合的效果。考虑到不同核函数的不同作用,不同特征包含不同的信息,本文将不同特征,不同核函数进行线性组合,构造一种双重的多特征多核方法,使得它能够融合任意特征以及任意核函数之间的双重组合。接下来将主要介绍本文多特征多核哈希学习方法。
3
自适应多特征多核哈希学习
在已有的基于核的哈希学习方法中,要么仅使用一特征对应一核如KLSH[9],SKLSH[10]和KSH[11],要么就是多特征中的每一特征对应同一个核函数如MFKH[12]。这些方法中并没有充分考虑到不同特征所含有的不同信息以及不同核函数所具有的不同作用。
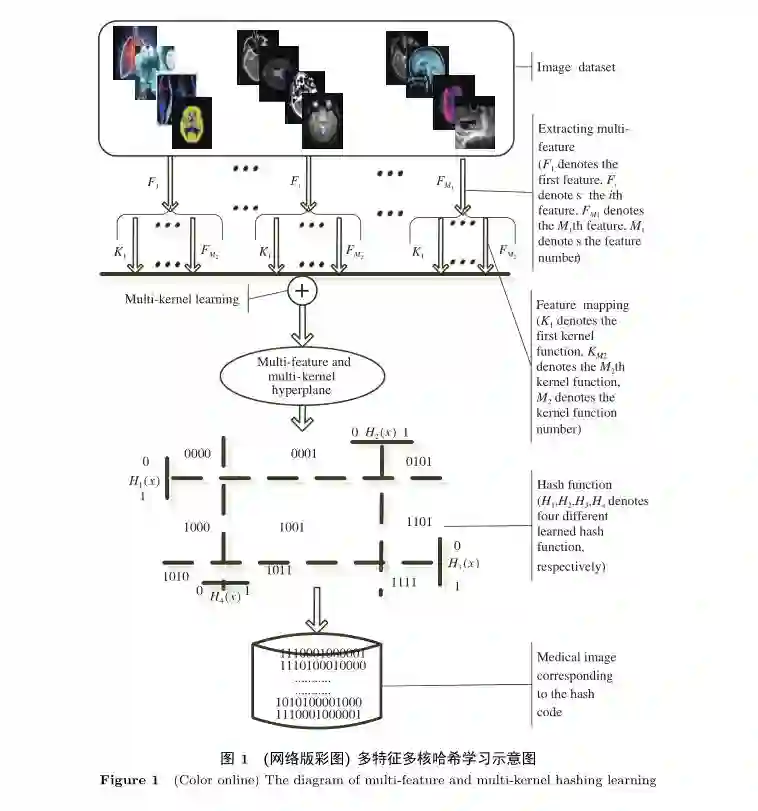
结合多特征核哈希[12]以及多核学习[25,26]的两种思想,本文提出一种自适应的多特征多核哈希学习方法,其哈希学习示意图如图1所示。图1主要阐述了多特征多核哈希学习方法的流程:首先,对于图像库中的每一幅图像,提取M1种不同的特征,然后将提取的每一种特征映射到M2个不同的核空间中,接着将映射到核空间的特征进行组合构造出多特征多核空间,然后进行哈希学习,最后将学习到的哈希码保存起来。本文提出一种自适应的多特征多核哈希学习方法,其多特征多核双重组合结构图如图2所示,图2表明将每一种特征分别映射到不同的核空间中,然后将这些映射到核空间中的特征进行组合,构造一种双重组合的多特征多核空间,最后在组合后的核空间中学习哈希函数。本文提出的自适应的多特征多核哈希学习方法不仅能够解决单个特征包含的信息量不足问题,而且能够将不同的核函数具有不同功能考虑进来,又因为核函数的特性,并不会因为特征的维度增加而导致“维度灾难”问题。其中特征的权重系数和核函数的权重系数是能够自学习的而不是人为指定的,因此具有更高的可信度。

3.1 目标函数的构造
本文令训练集的样本数为N,特征图的个数为M1,核函数的个数为M2。训练集的第n个样本的第m种特征可以表示为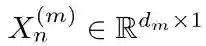
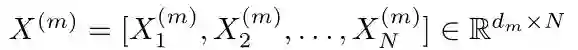
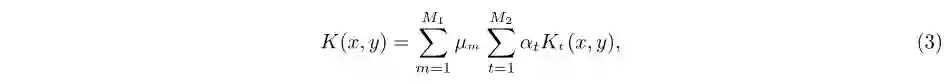
其中αt表示第t个核函数的权重,µm表示第m种特征的权重系数,Kt(x,y)表示图像x和y的第t个核函数的函数值.由式(3)可知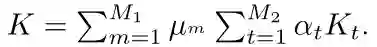
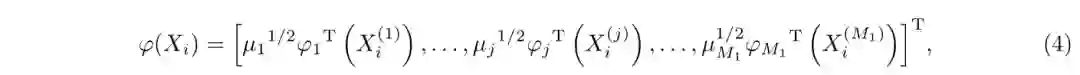
该式中
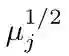
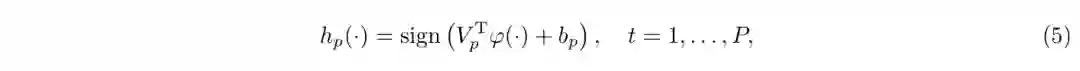
其中第i个样本的第p个哈希码为Ypi = hp(Xi)。
定义超平面向量Vq可由R个映射到对应的核空间中的Zr基点表示而成,即
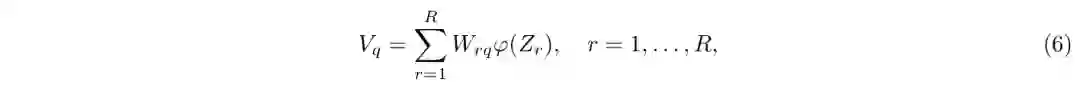
其中W是一个R×B的权重矩阵,B为哈希码长度,基点或锚点可以通过随机样本[30]或者聚类[31]的方法获得。由上述式子可知所有训练样本的哈希码Y可以写成如下核形式,即
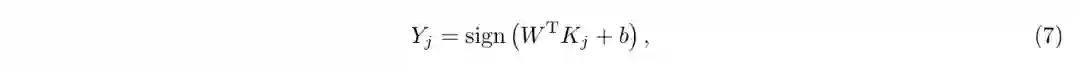
其中 Kj为 R个基点与N个样本点构成的大小为R×N的核矩阵KR×N的第 j列,偏置b=[b1, b2, . . . , bB],B为哈希码长度。
对于所有训练样本,令需要学习的哈希函数的个数为B,哈希函数表示为{h1 ,...,hB},学习到的哈希码为Y(B×N的矩阵)并且哈希码能够保持图像之间的某种相似性S(稀疏矩阵),令Sij表示任意两个样本点i和j之间的相似度,对于多特征多核中的监督方法而言,相似度矩阵S定义如下:

在谱哈希[28]和多特征核哈希[12]的基础上,基于上述所列的式子,本文构造出如下的一种自适应的多特征多核哈希学习的目标函数:
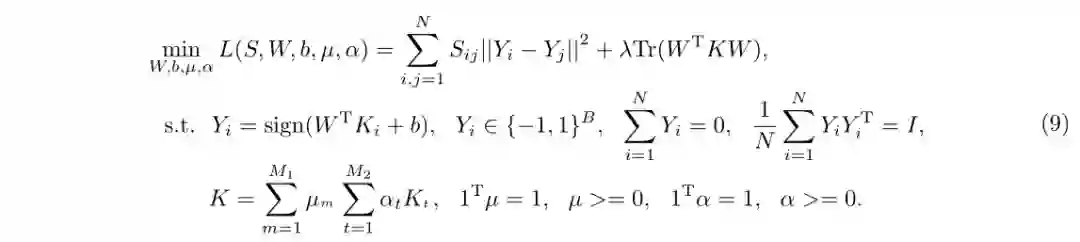
使用Laplace矩阵L=D−S(其中D为对角矩阵,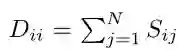
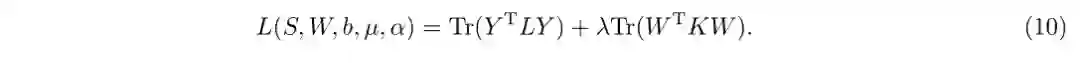
对于目标函数(10),通过优化权重矩阵W,权重系数µ以及权重系数α,使得学习到的哈希函数能够保留原始图像的相似性。虽然将不同的特征映射到不同的核空间后再将它们连接起来会导致特征维度非常高,但是使用核技巧后最终的特征维度只有R维,而且
3.2 目标函数的求解方法
由于目标函数具有离散性和非凸性约束条件,使得它的求解过程非常困难。使用类似谱哈希[28] 的思想,将离散约束条件
3.2.1 求解权重矩阵和偏置W,b
固定µ和α,由限制条件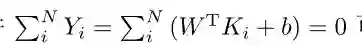

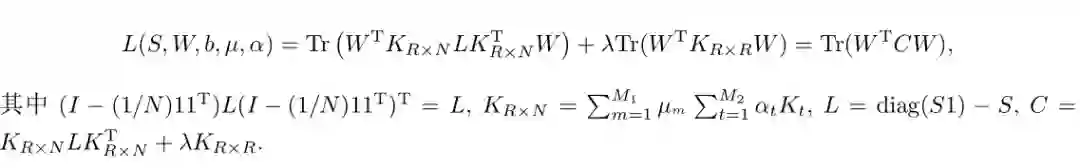
因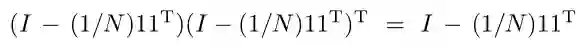

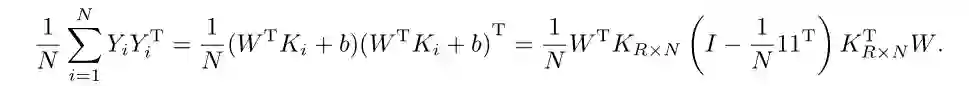
令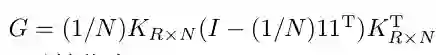
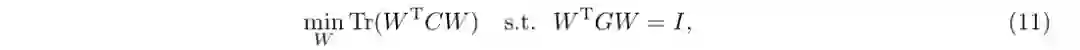
式(11)的求解过程可通过特征值分解方法[29]求得。
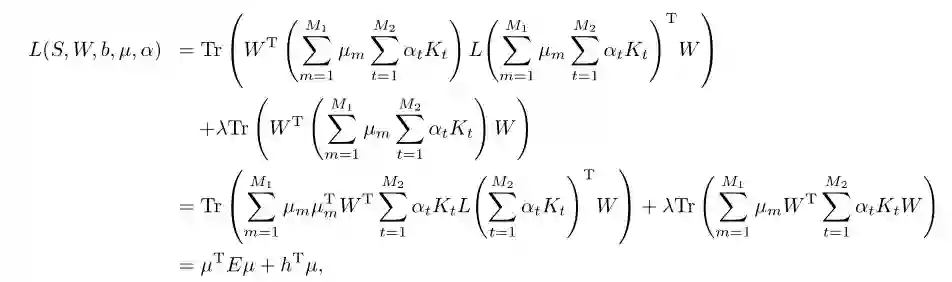
其中,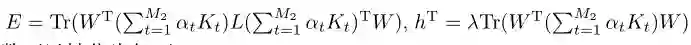

因此求 µ 的过程可以看作是二次规划问题的求解过程。
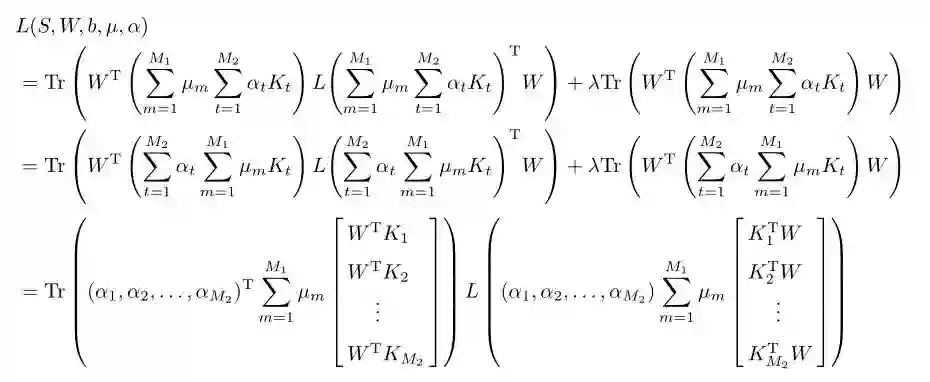

于是通过目标函数(10)求解系数α可以简化如下:

式(13)的求解过程同样可通过二次规划方法求出α。
3.2.4 哈希编码过程
对于新的待检索样本x, 它的哈希码表达形式为
其中Zi表示 R个基点中的第i个基点样本。使用汉明距离排序或者哈希查找表的方法,求出待检索的样本与数据库中的样本的距离,可以在次线性时间内检索出相似图像。
综上分析,本文的MFMKH算法步骤描述如算法1:

4
算法分析
本节主要对提出的多特征多核哈希学习算法(MFMKH)进行算法复杂度分析和空间复杂度分析。本算法通过随机样本法选取基点后能够降低时间复杂度,不会因为特征融合后的维度增加而导致计算量增大,其复杂度只与选择的基点数和样本的规模有关。
4.1 时间复杂度分析
本文提出的多特征多核哈希学习算法的时间复杂度由多特征多核哈希编码训练过程的时间复杂度决定,训练时每次迭代的时间复杂度由3部分构成,分别是固定µ和α时,求解W,b的时间复杂度;固定W,b,α时,求解µ的时间复杂度以及固定W,b,µ时,求解α的时间复杂度共同决定。其中求解权重矩阵W和偏置b的时间复杂度主要是3个矩阵的乘积即计算

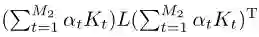
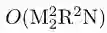

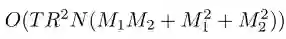
4.2 空间复杂度分析
哈希学习将数据映射成二进制串的形式,能显著减少数据的存储和通信开销,从而有效提高学习系统的效率和训练过程,不考虑输入的训练集存储空间,只考虑新引入的参数存储空间,则需保存的参数有权重矩阵W,偏置b,特征权重系数µ,核权重系数α以及输出训练样本的哈希码Y,整个训练过程中的空间复杂度由这5个部分组成.W的空间复杂度为O(R B);b的空间复杂度为O(N B);µ的空间复杂度为O(M1),α的空间复杂度为O(M2),Y的空间复杂度为O(B N)。其中R为选择的基点数,B为训练样本的哈希码长度,N为训练样本数,M1为特征个数,M2为核函数个数.因此整个训练过程的空间复杂度为O(RB+NB+M1+M2)。存储过程,每个数据点会被一个紧凑的二进制串编码,在原空间中相似的2个点应当被映射到哈希码空间中相似的2个点.对于总样本数为N,总特征维度为M,每一个维度所需的存储空间为δbyte,所需总的存储空间为δ×N×Mbyte,而如果把每个数据映射成哈希码,则所需的存储空间为(N×B)/8byte,其中B为每个样本的哈希码长度(B≪M),因此存储空间复杂度为O(N B)。
4.3 算法收敛性分析
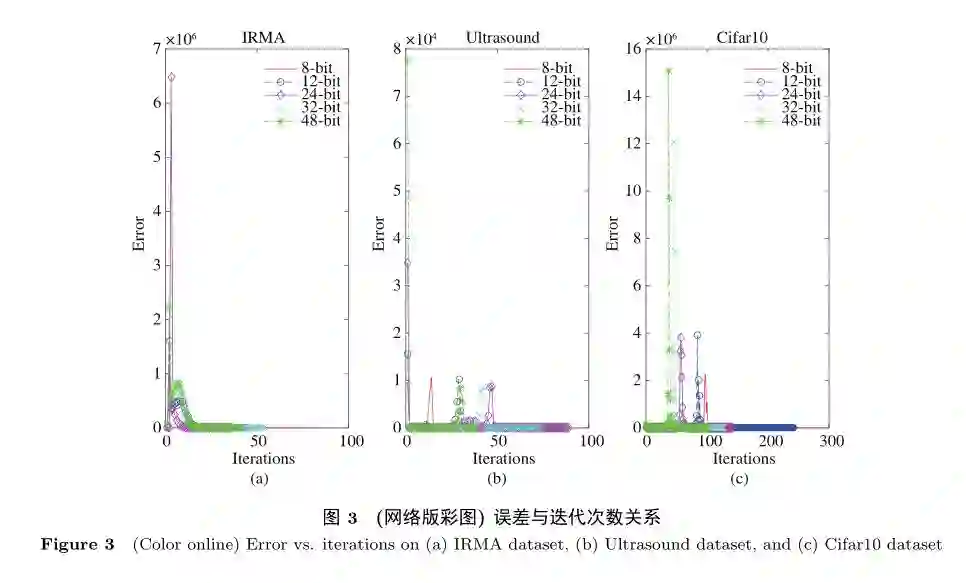
在本文的3个实验中,通过交替迭代的方式优化目标函数(10),对于每一次交替迭代进行3步更新,第1步先固定α和µ更新W和b,第2步固定W,b和µ更新α,第3步固定W,b和α更新µ,交替更新直到目标函数(10)的函数值稳定时。实验过程中,设目标函数(10)前后两次迭代的误差为error,当error小于1E−4时,算法收敛。在IRMA,Ultrasound,Cifar10数据集上的实验结果表明当哈希码长度分别为8,12,32,24,48bits时,目标函数在IRMA数据集上分别迭代82,45,37,55,42次后算法收敛;目标函数在Ultrasound数据集上分别迭代28,85,89,74,38次后算法收敛;目标函数在Cifar10数据集上分别迭代291,243,142,128,102次后算法收敛。图3(a)∼(c)分别表示目标函数收敛时在3个不同数据集上误差与迭代次数的关系。
5
实验结果
本节将本文提出的方法与相关方法进行实验比对,从而验证本文提出方法的有效性。主要比对的方法有核局部感知哈希[9]、平移不变性核局部感知哈希[10]、多特征核哈希[12]、谱哈希[28]以及基于标签对的深度监督哈希[13]。此外,本文还进行了自我对比的实验即多特征多核实验中将任意单特征单核的组合形式和多特征多核方法进行对比。实验过程中,为了减少随机性的影响,所有的方法进行了10次实验。
本文实验中使用GIST特征、HOG特征、线性核、Laplace核及Gauss核的组合包括理论分析和多次实验验证。
(1)本文从特征和核函数的物理特性进行分析说明选择该组合的合理性,由于特征的选择多种多样,本文主要从全局特征和局部特征进行考虑。全局特征主要考虑的是图像的宏观特征而忽略图像的局部特征(如GIST特征);而局部特征是图像特征的局部表达,它只能反应图像上具有的局部特殊性(如HOG特征)。核函数主要分为全局核函数和局部核函数,全局核函数(如线性核函数)具有全局特性,其允许相距很远的数据点对核函数的值有影响,而局部核函数具有局部性,只允许相距很近的数据点对核函数的值有影响。Laplace核作为一种局部核只保证数据在原始空间中是近邻关系的点通过映射后依然保持近邻关系,而没有保证非近邻的点通过映射后尽可能的保持远,这就导致非近邻的点通过映射后可能变成了近邻点。Gauss核表示两个样本点的距离,它能够保证非近邻点通过映射后还是非近邻关系,弥补了Laplace核函数的不足。因此从特征的全局性和特征的局部性,以及核函数的局特性和局部特性考虑,本文选择了这两种特征3种核函数的结合方法。
(2)通过实验表明,将HOG特征和GIST特征与线性核、Gauss核和Laplace核进行组合时效果比仅仅将HOG特征或者GIST特征单独与3种核函数组合时效果要好。
(3)未来将其他手工特征和深度特征结合探索更有利于实际应用场景的特征融合,并探索更多的核函数,总体上应该没有适合一切应用问题的某一个或几个特征,也没有适合一切应用问题的一种或几种核函数度量,都需要根据实验场景进行具体分析与测试。
本文主要用两种常用的检索方法来评估哈希学习的性能:汉明排序和哈希查找表。用哈希算法进行检索主要就是利用了汉明空间离散的特点,在汉明空间中可以用机器指令或查表来计算距离(减法),相比于欧氏距离计算其速度相当快,有几十甚至上百倍的差距。汉明排序是将待检索样本同数据库中所有的样本点的汉明距离按升序排序,而哈希查找表使用的是二进制哈希码查找方法,将所有的查询结果中汉明距离小于2的样本返回作为查询结果。
5.1 数据集
本文在IRMA数据集3)、Ultrasound数据集4)以及Cifar105)数据集上进行了实验验证,实验过程中本文主要采用两种特征和3种核的组合方式。其中特征为HOG特征和GIST特征,核函数为线性核、Laplace核和Gauss核。IRMA数据集包含了193个类共12677张有注释的灰度射线图。其中有57个类别共10902张图具有标签信息,由于IRMA数据集中只有2005年的数据集是有标签的数据,其他为无标签的数据,而本文中采用的是有监督的方法,所以选取了IRMA数据集中2005年的数据。该数据集共57类10000张,由于该数据集中每个类别的数量参差不齐,大部分类别中数量低于50张,而为了能够更好地训练模型,本文选取的每种数据样本集在150张以上,而满足要求的只有15种,从这15种中随机选取10类共2673张,对于每个类别大约按3:1的比例随机分训练样本和测试样本,具体分布情况如表1。
Ultrasound数据集总量为2682分10个类别,每个类大约按3:1的比例随机选取样本作为训练集和测试集,具体分布情况如表1。对于Cifar10数据集,本文随机选取1000张(每类100张)作为测试集,从剩余的图像中随机选择5000张(每类500张)作为训练集。
5.2 实验分析
在IRMA,Ultrasound和Cifar10数据集上验证了本文提出的自适应多特征多核哈希方法(MFMKH)。本文在IRMA数据集上验证了核哈希方法之间的准确率、召回率与返回检索样本数和哈希码长度之间的关系。另外,本文又将核哈希和深度哈希在MAP(mean average precision)指标和训练时间做了对比实验。
核哈希对比方法中本文采用随机样本法从训练集中选择了300个样本作为基点,实验过程中采用了GIST[32]特征和HOG[33]特征,其中GIST特征维度为384维,HOG特征维度为324维;核函数采用了Gauss核、Laplace核和线性核。在核哈希和深度哈希的对比实验中,本文采用随机样本法从训练集中选择了300个样本作为基点。实验过程中采用了GIST特征和HOG特征,其中GIST特征维度为512维,HOG特征维度为324维;核函数采用了Gauss核、Laplace核和线性核。本文在上述3个数据集中从MAP指标上对它们进行了比较分析。在这3个对比实验中,SH[28],SKLSH[10],KLSH[9]对应的特征为512维的GIST特征,MFKH[12],M2FM3K对应的特征为512维的GIST特征和324维的HOG特征的组合,DPSH[13]输入的为原始图像。在IRMA,Ultrasound和Cifar10数据集上,Gauss核、Laplace核和线性核的参数分别为5,1,10;0.5,5,1;25,0.1,10。
本文主要对比的方法有多特征核哈希(MFKH)[12]、谱哈希(SH)[28]、平移不变核局部感知哈希(SKLSH)[10]、核局部感知哈希(KLSH)[9]以及基于标签对的深度监督哈希(DPSH)[13]。
5.2.1 核哈希方法的实验对比分析
本小节主要对核哈希方法在IRMA数据集上进行实验对比分析,主要对比的方法有多特征核哈希(MFKH)、谱哈希(SH)、平移不变核局部感知哈希(SKLSH)、核局部感知哈希(KLSH)。
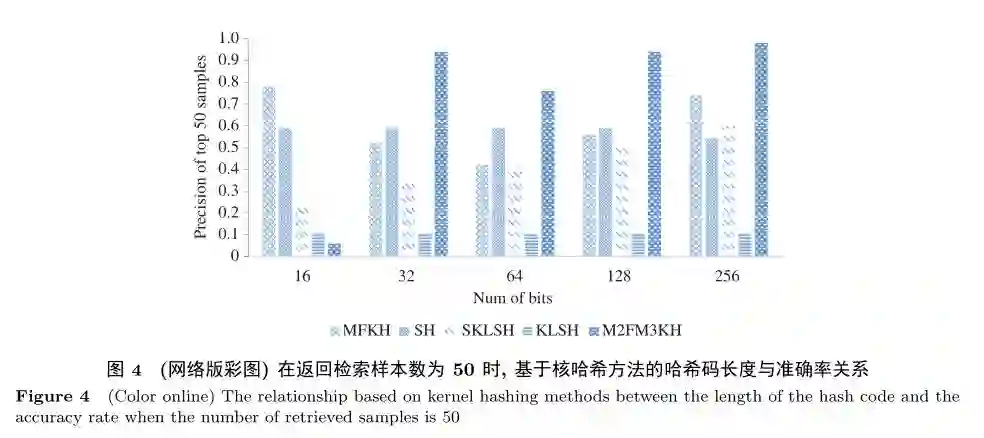
图4和5是在IRMA数据集上进行的实验,主要比较本文方法中的多特征多核方法(M2FM3KH中特征为GIST和HOG)与其他对比方法在返回检索样本数为50时,不同长度的哈希码下准确率与召回率的关系。当返回检索样本数为50,哈希码长度大于等于32时,M2FM3KH准确率超过了其他对比方法,而召回率仅次于谱哈希方法,其中M2FM3KH中特征为HOG和GIST,核函数为线性核、Laplace核以及Gauss核,核参数σ分别为0。5,100,1(此外,本文还将单个HOG特征或GIST特征同上述3种不同的核函数进行了组合(M1FM3KH)并与其他核哈希方法进行了实验对比,从实验中可看出M2FM3KH实验结果比M1FM3KH实验结果好,进一步验证了融合后的特征包含的图像信息量更大,能够进一步提高图像检索的准确率6))。
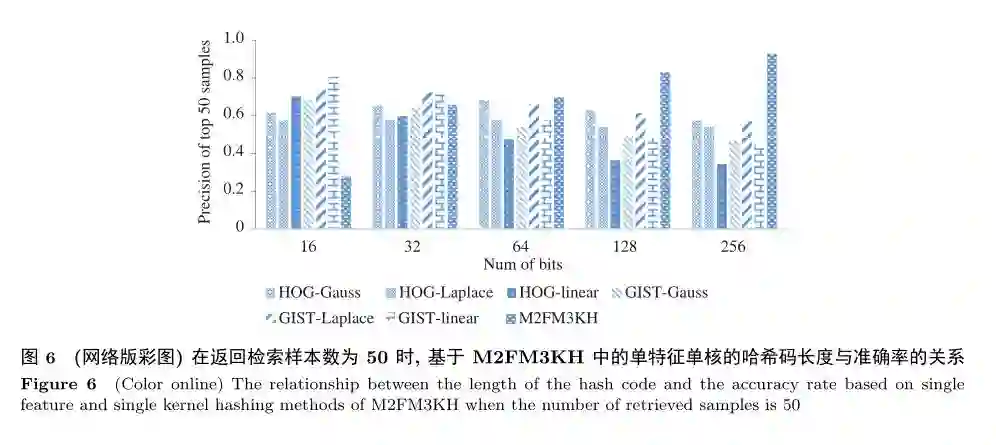
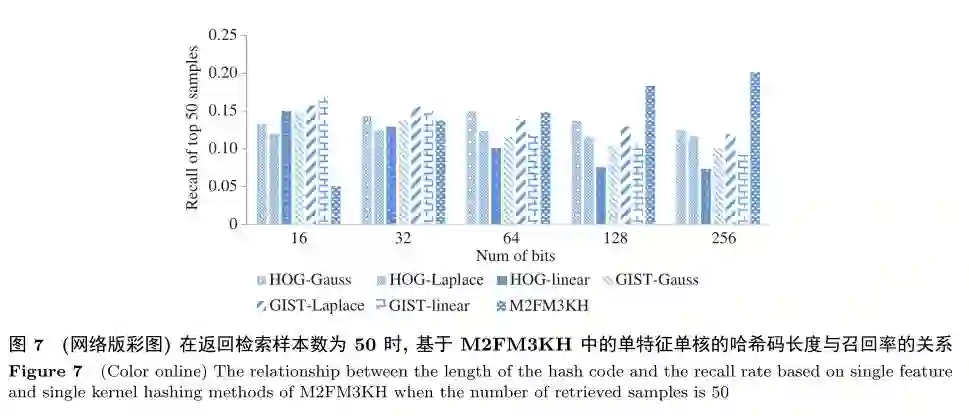
图6和7是在IRMA数据集上进行的实验,主要比较本文方法中的多特征多核方法(M2FM3KH)与该方法中的单特征单核组合方法(共6种)在返回样本数为50时准确率和召回率上的关系。图6和7中的对比实验能够进一步验证本文提出的方法的可行性和优点。从图6和7可以看出当哈希码长度大于等于128时,M2FM3KH的准确率和召回率超过了单特征单核的组合方法(其中M2FM3KH中特征为HOG和GIST,核函数为线性核、Laplace核以及Gauss核,核参数σ分别为0.5,20,2;其他种对比方法为2种特征3种核函数的任意一种组合)。


5.2.2 核哈希方法与深度哈希方法的实验对比分析
本小节主要对核哈希方法与深度哈希方法(DSPH)在3个不同数据集上的实验对比分析,主要对比的方法有多特征核哈希(MFKH)、谱哈希(SH)、平移不变核局部感知哈希(SKLSH)、核局部感知哈希(KLSH)以及基于标签对的深度监督哈希(DPSH)。

表2是在IRMA和Ultrasound数据集上进行的实验,主要验证本文方法(M2FM3KH)与其他对比方法包括深度哈希方法在不同哈希码长度下的MAP。从IRMA数据集上的实验结果中可以看出虽然本文的方法整体的MAP要高于其他核方法,但是同DPSH的MAP相比,仍有所差距。从Ultrasound数据集上的实验结果可以看出右边的MAP同左边的MAP相比要低很多,进一步验证了超声图像数据识别的难度。表3是在Cifar10数据集上进行的实验,从中可以看出MFKH和本文的MFMKH方法的MAP整体上比其他核方法高一点,体现了多特征核方法和多特征多核方法比单特征单核方法要好,但依然低于DPSH的MAP。从这3个实验数据中可以看出本文方法虽然整体上比其他核方法要好,但是同DPSH相比,仍有所差距,体现了深度学习在图像检索方面的优势。
5.3 实验总结
表2和3的实验结果表明本文算法检索性能虽然低于DPSH方法,但是明显优于同类基于核的哈希学习方法。从表2和3可以看出DPSH的MAP整体上比核哈希方法要高出许多,但是DPSH的高MAP需要极大的时间代价。虽然本文的方法在MAP上比DPSH方法低,但本文方法充分利用了多特征多核双重组合的优点,通过多特征融合的方法来提高图像的信息量,通过核方法来解决线性不可分问题,通过选择基点的方法使得其训练过程不受总特征维度的影响,只与选择的基点个数和样本规模有关。与DPSH方法相比在训练时间显著减少的情况下检索性能在一定长度的哈希码上是可竞争的。
6
结束语
本文提出了自适应多特征多核哈希学习(MFMKH)算法,该方法兼容基本的数据类型和各种相似性度量方法,能够适用于多种形式的特征和多种核函数的双重组合方式,不存在数据需要具有某个分布的提前假设,也不需要知道特征空间的映射形式。这种自适应的多特征多核的哈希学习算法架构能够自适应学习特征权重系数和多核权重系数,将多特征和多核的优点进行了双重融合。多特征的融合解决了单特征所包含的信息量单一不足的问题;多核的组合方式能够弥补单核学习能力上的不足且解决了“维度灾难”问题。实验结果表明本文的方法具有多特征融合[24]和多核学习[25,26]的双重优点。实验过程中,发现核函数的参数对实验结果有一定的影响,而且所提供的特征基本上是基于手工特征。在后期的工作中,我们将MFMKH方法用于其他图像数据集上进行测试,进一步研究核参数的问题以及深度特征与手工特征结合的效果。虽然本文方法在MAP上与DPSH相比有差距,但是本文方法充分利用了多特征多核双重组合的优点,通过多特征融合的方法来提高图像的信息量,通过核方法来解决线性不可分问题,通过选择基点的方法使得其训练过程不受总特征维度的影响,只与选择的基点个数和样本规模有关。鉴于深度哈希学习的效果较好但所需的训练时间极长,在后期的工作中,我们将会在本文的基础上进一步研究深度学习方法与本文的方法结合的可能性,使得训练时间能够进一步减少。
论文下载地址:
http://engine.scichina.com/publisher/scp/journal/SSI/47/8/10.1360/N112016-00307?slug=full%20text
参考文献:
1 Naimi A I, Westreich D J. Big data: a revolution that will transform how we live, work, and think. Am J Epidemiol,2014, 17: 181–183
2 Tu Z P. The Big Data Revolution. Guilin: Guangxi Normal University Press, 2013. 312–315 [ 涂子沛 . 大数据 . 桂林 :广西师范大学出版社 , 2013. 312–315]
3 Zhou Z H. Machine learning and data mining. Commun China Compute Fed, 2007, 3: 35–44 [ 周志华 . 机器学习与数据挖掘 . 中国计算机学会通讯 , 2007, 3: 35–44]
4 Shao H, Cui W, Zhao H. Medical image retrieval based on visual contents and text information. In: Proceedings of International Conference on Systems, Man and Cybernetics, Hague, 2004. 1098–1103
5 Rui Y, Huang T S, Chang S. Image retrieval: past, present, and future. J Vis Commun Image Represent, 1999, 10:1–23
6 He J, Li M, Zhang H J, et al. Generalized manifold-ranking-based image retrieval. IEEE Trans Image Process, 2006,15: 3170–3177
7 Wang F, Er G, Dai Q. Inequivalent manifold ranking for content-based image retrieval. In: Proceedings of International Conference on Image Processing, California, 2008. 173–176
8 Har-Peled S, Indyk P, Motwani R. Approximate nearest neighbor: towards removing the curse of dimensionality. Symp Theory Comput, 2012, 52: 604–613
9 Kulis B, Grauman K. Kernelized locality-sensitive hashing for scalable image search. In: Proceedings of International Conference on Computer Vision, Kyoto, 2009. 2130–2137
10 Raginsky M, Lazebnik S. Locality-sensitive binary codes from shift-invariant kernels. In: Proceedings of Advances in Neural Information Processing Systems, Vancouver, 2009. 1509–1517
11 Liu W, Wang J, Ji R, et al. Supervised hashing with kernels. In: Proceedings of Conference on Computer Vision and Pattern Recognition, Providence, 2012. 2074–2081
12 Liu X, He J, Lang B. Multiple feature kernel hashing for large-scale visual search. Pattern Recog, 2014, 47: 748–757
13 Li W J, Wang S, Kang W C. Feature learning based deep supervised hashing with pairwise labels. Comput Sci, 2015,2: 1711–1717
14 Liu H, Wang R, Shan S, et al. Deep supervised hashing for fast image retrieval. In: Proceedings of Conference on Computer Vision and Pattern Recognition, Las Vegas, 2016. 2064–2072
15 Shi X S, Xing F Y, Cai J Z, et al. Kernel-based supervised discrete hashing for image retrieval. In: Proceedings of European Conference on Computer Vision, Amsterdam, 2016. 419–433
16 Xu Y, Shen F, Xu X, et al. Large-scale image retrieval with supervised sparse hashing. Neurocomputing, 2017, 229:45–53
17 Gui J, Liu T L, Sun Z N, et al. Fast supervised discrete hashing. IEEE Trans Pattern Anal Mach Intel, 2017. doi:10.1109/TPAMI.2017.2678475
18 Li W J, Zhou Z H. Learning to hash for big data: current status and future trends. Sci Bull, 2015, 60: 485–490 [ 李武军 , 周志华 . 大数据哈希学习 : 现状与趋势 . 科学通报 , 2015, 60: 485–490]
19 Liu X L, Huang L, Deng C, et al. Multi-view complementary hash tables for nearest neighbor search. In: Proceedings of International Conference on Computer Vision, Santiago, 2015. 1107–1115
20 Xu H, Wang J, Li Z, et al. Complementary hashing for approximate nearest neighbor search. In: Proceedings of International Conference on Computer Vision, Barcelona, 2011. 1631–1638
21 Kan M, Xu D, Shan S, et al. Semisupervised hashing via kernel hyperplane learning for scalable image search. IEEE Trans Circ Syst Video Technol, 2014, 24: 704–713
22 Zhang D, Wang F, Si L. Composite hashing with multiple information sources. In Proceeding of International Conference on Research and Development in Information Retrieval, Beijing, 2011. 225–234
23 Song J, Yang Y, Huang Z, et al. Multiple feature hashing for real-time large scale near-duplicate video retrieval. In: Proceedings of International Conference on Multimedea, Scottsdale, 2011. 423–432
24 Shen H, Tao D, Ma D. Multiview locally linear embedding for effective medical image retrieval. Plos One, 2013, 8:e82409
25 Gonen M, Alpaydin E. Multiple kernel learning algorithms. J Mach Learn Res, 2011, 12: 2211–2268
26 Tzortzis G, Likas A. Greedy unsupervised multiple kernel learning. In: Proceedings of Hellenic Conference on Artificial Intelligence, Berlin, 2012. 73–80
27 Akgül C B, Rubin D L, Napel S, et al. Content-based image retrieval in radiology: current status and future directions. J Digit Imag, 2011, 24: 208–22228 Weiss Y, Torralba A, Fergus R. Spectral Hashing. In: Proceedings of Conference on Neural Information Processing Systems, Auckland, 2008. 1753–1760
29 Zelnik-Manor L, Perona P. Self-tuning spectral clustering. In: Proceedings of Advances in Neural Information Processing Systems, Vancouver, 2004. 17: 1601–1608
30 He J, Liu W, Chang S F. Scalable similarity search with optimized kernel hashing. In: Proceedings of International Conference on Knowledge Discovery and Data Mining, Washington, 2010. 1129–1138
31 Liu W, Wang J, Kumar S, et al. Hashing with graphs. In: Proceedings of International Conference on Machine Learning, Bellevue, 2011. 1–8
32 Oliva A, Torralba A. Modeling the shape of the scene: a holistic representation of the spatial envelope. Int J Comput Vision, 2001, 42: 145–175
33 Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of Conference on Computer Vision and Pattern Recognition, San Diego, 2005. 886–893

📚往期文章推荐

🔗两会速递丨杨善林院士:建议深化改革“杰青”“长江学者”管理
🔗她是Sci-Hub背后的“盗版女王”,被出版机构视为死敌的“侠盗”

德先生公众号 | 往期精选
在公众号会话位置回复以下关键词,查看德先生往期文章!
人工智能|机器崛起|区块链|名人堂
虚拟现实|无人驾驶|智能制造|无人机
科研创新|网络安全|数据时代|人机大战
……
更多精彩文章正在赶来,敬请期待!


点击“阅读原文”,移步求知书店,可查阅选购德先生推荐书籍。





