浙大提出神经3D重建新工作!收录图形学顶会SIGGRAPH 2022
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CVer 微信技术交流群
梦晨 发自 凹非寺
转载自:量子位(QbitAI)
以NeRF为代表的神经渲染技术高速发展,学界已经不满足合成几个新视角让照片动起来了。
接下来要挑战的是根据照片直接输出3D模型,可以直接导入到电影、游戏和VR等图形生产线里的那种。

所用照片不是出自高质量数据库,就是直接从网上搜集游客拍摄的各大景点,设备、天气、距离角度等都会不一致。
生成的结果远看结构完整,近看细节丰富,如果你有VR设备也可以在Demo中直接预览3D版。
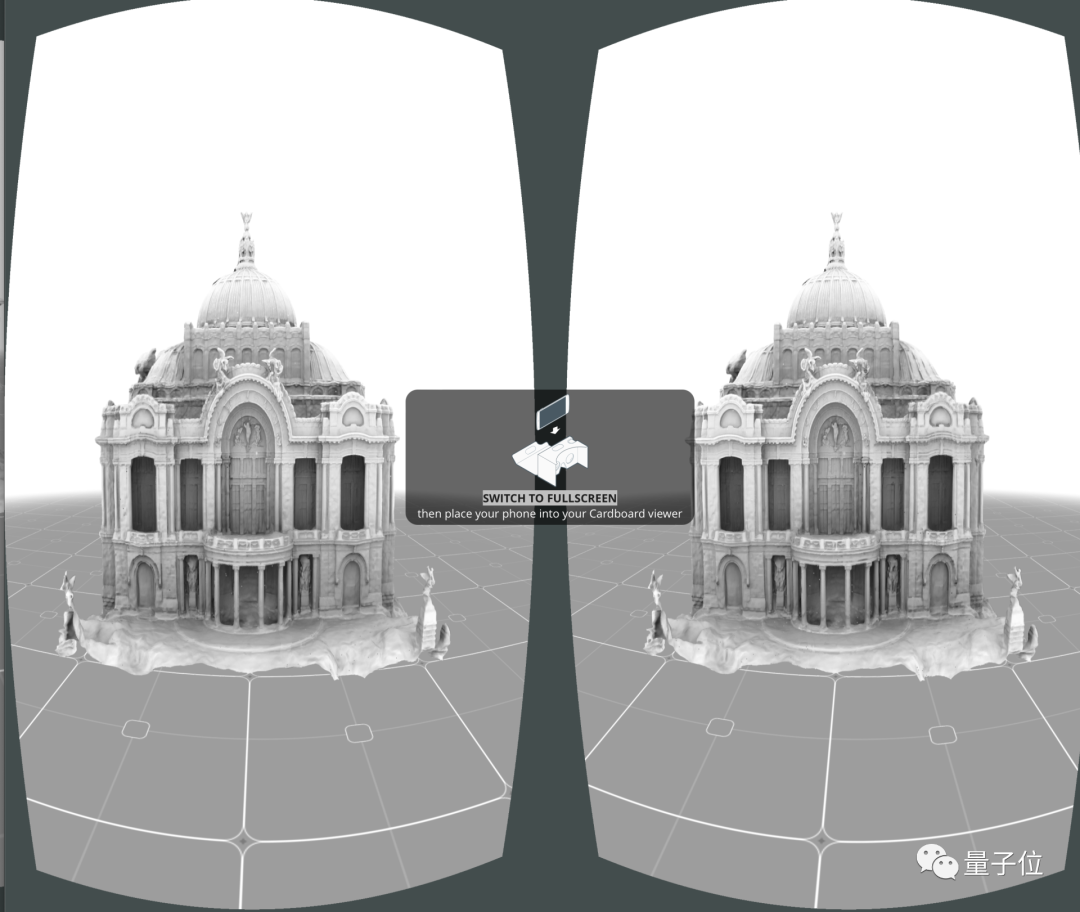
这项最新突破由浙江大学和康奈尔大学团队合作完成,登上图形学顶会SIGGRAPH 2022。

论文地址:
https://arxiv.org/abs/2205.12955
GitHub仓库:
https://zju3dv.github.io/neuralrecon-w/
而在这之前,同类技术生成的3D模型连形状完整都做不到。

看到这里,网友纷纷表示这个领域的进展比人们想象的要快。

“慢点学,等等我”。
那么,这项研究靠什么取得了突破?
融合两种采样方式
具体来说,这项研究的基本框架借鉴了NeurIPS 2021上的NeuS,一种把隐式神经标准和体积渲染结合起来的方法。

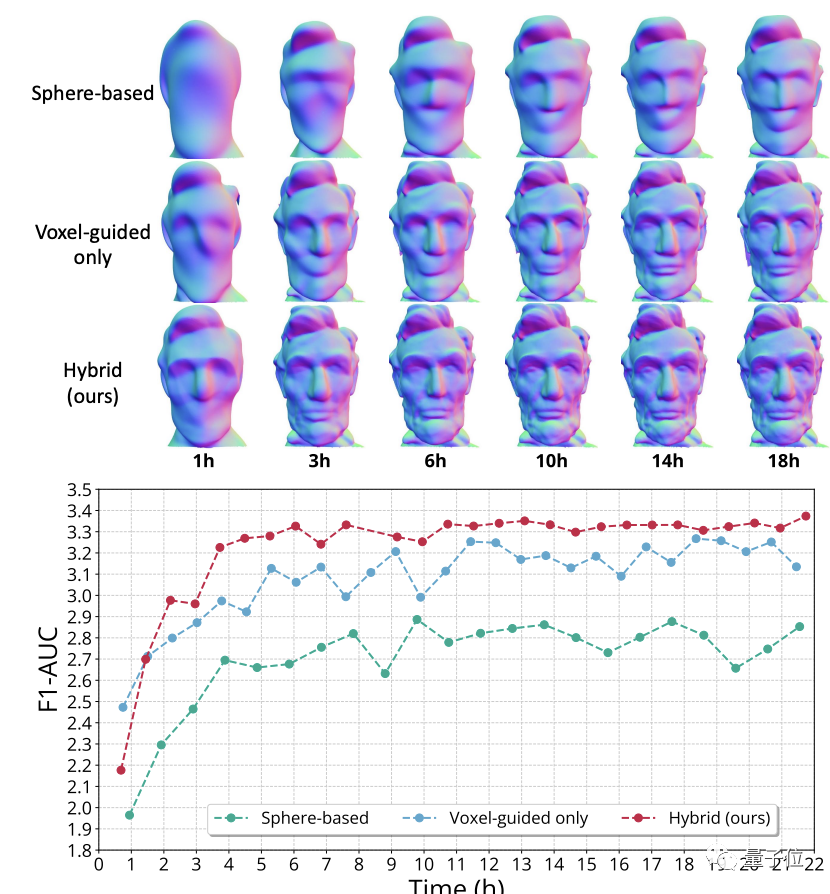
但是NeuS使用基于球体的采样(Sphere-based sampling)方法,对于近景、小物体来说还算适合。
用于结构复杂的大型建筑物的话会有大量采样点采在空白区域,增加大量不必要的计算压力。
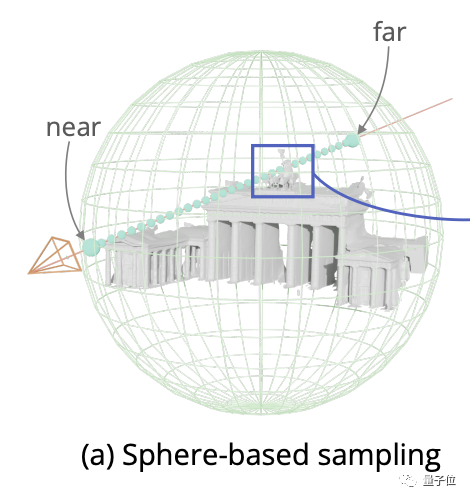
为解决这个问题,研究人员提出体素引导(Voxel-guided)和表面引导(Surface-guided)混合的新采样方法。
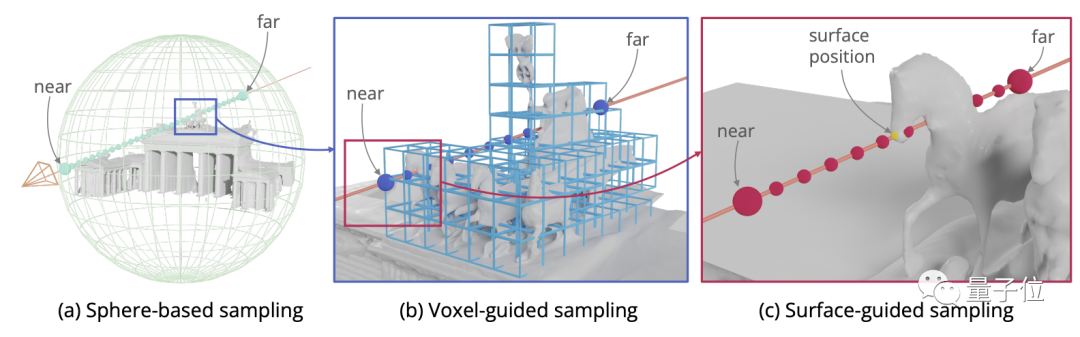
体素引导可以避免不必要的浪费,训练时所需射线(Traning ray)可以减少30%。
再结合表面引导增加真实曲面周围的采样密度,帮助神经网络更好拟合,避免丢失细节。
在消融实验中可以看到,仅使用体素引导方法收敛的比基于球体的方法快,但不如混合方法细节丰富。
与之前同类研究对比,新方法生成模型的完整性和细节方面更出色。

训练速度上也有明显优势,特别是在大型场景墨西哥城美术宫(PBA)。
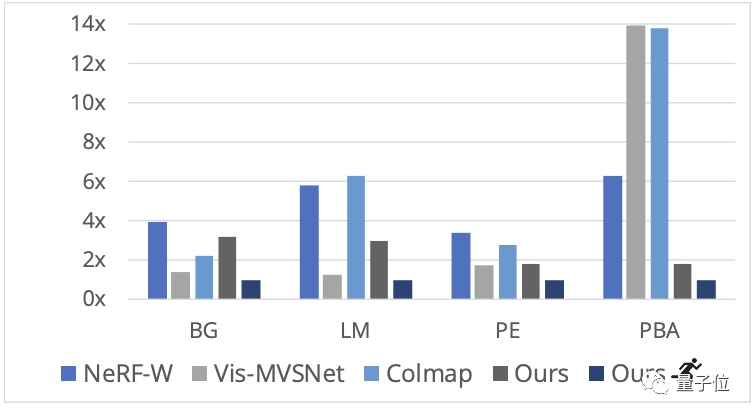
△Ours为完全收敛结果,带小人图标的是训练过程中一个检查点
当然,新方法也不是完全没有缺点。
一个继承自NeRF的局限性是,如果相机位置校准有偏差会影响最终结果。
还有一个难以解决的问题,就是照片拍不到的建筑物背面和内部就无法精确重建了。

One More Thing
最后再补充一点,浙大团队中一些成员,之前还研究了神经3D人体重建。

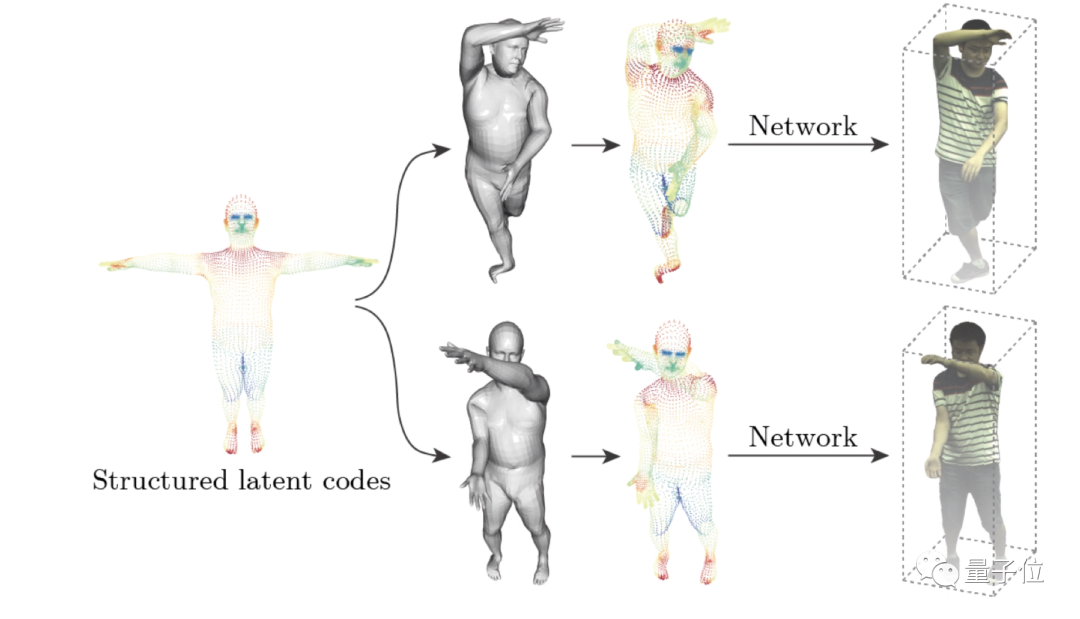
可应用于为体育比赛提供自由视角的视频重放。
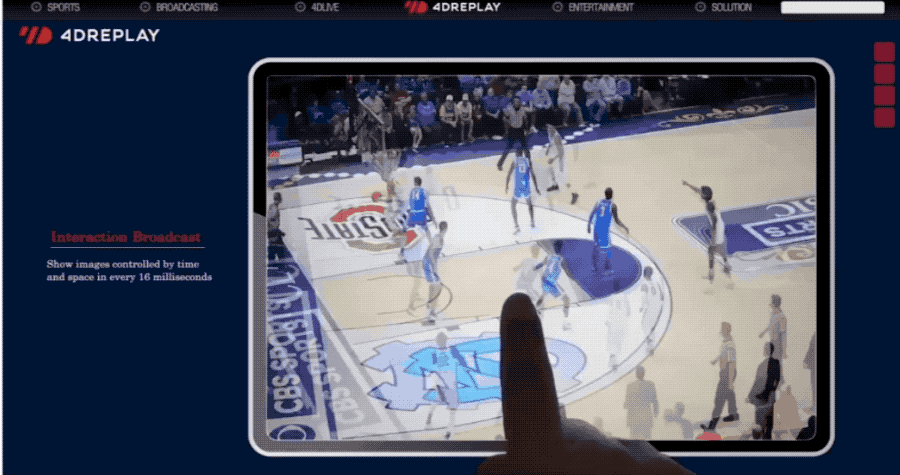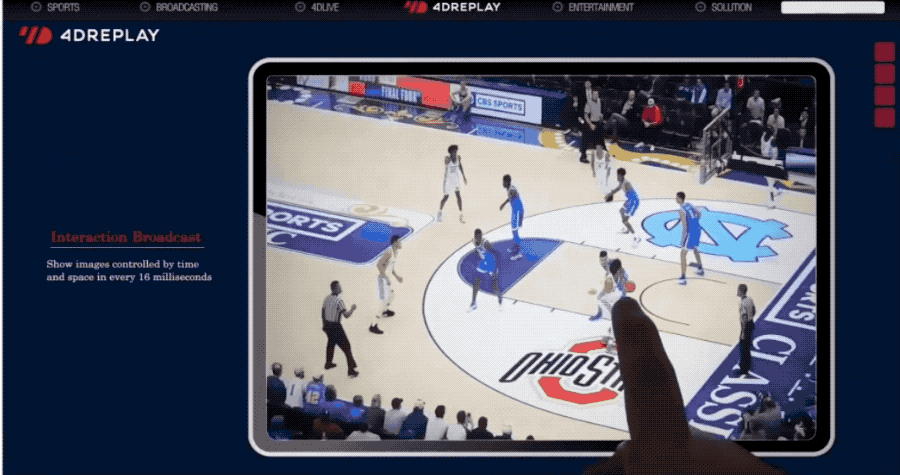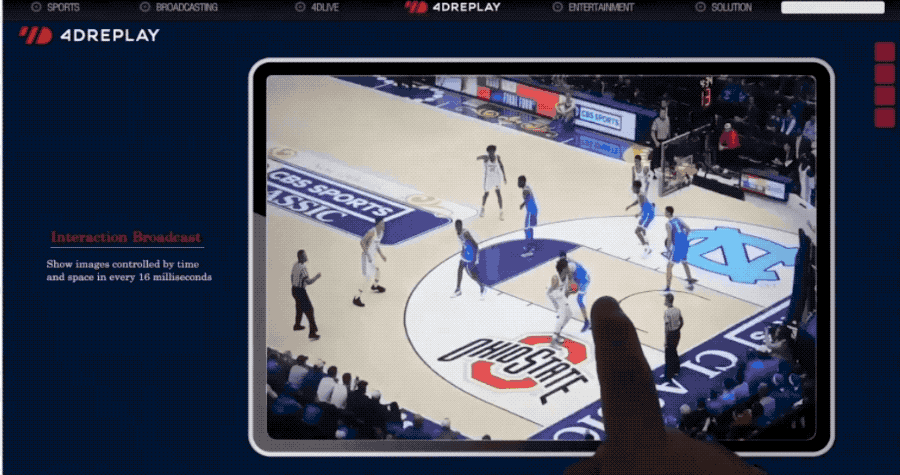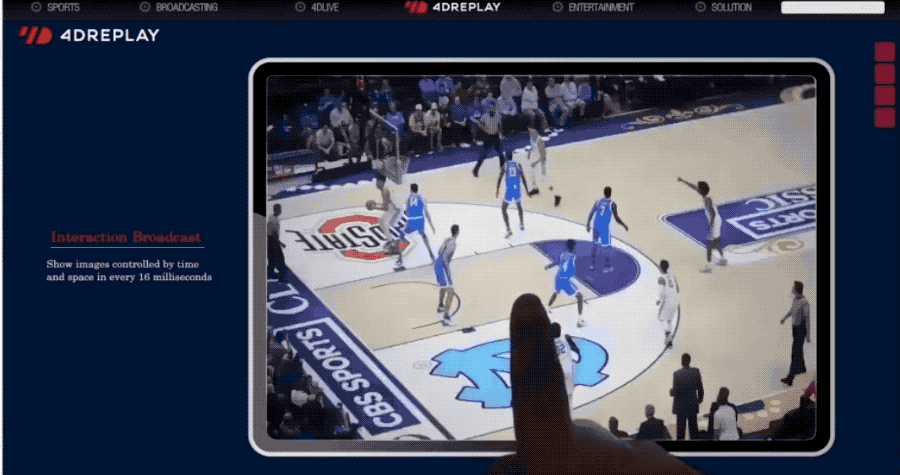
也是666了。
NeRF 交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如NeRF+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看


