训练自动驾驶系统需要高精地图,海量的数据和虚拟环境,每家致力于此方向的科技公司都有自己的方法,Waymo 有自己的自动驾驶出租车队,英伟达创建了用于大规模训练的虚拟环境 NVIDIA DRIVE Sim 平台。近日,来自 Google AI 和谷歌自家自动驾驶公司 Waymo 的研究人员实践了一个新思路,他们尝试用 280 万张街景照片重建出整片旧金山市区的 3D 环境。
![]()
通过大量街景图片,谷歌的研究人员们构建了一个 Block-NeRF 网格,完成了迄今为止最大的神经网络场景表征,渲染了旧金山的街景。
该研究提交到 arXiv 上之后,Jeff Dean 立即转推介绍:
![]()
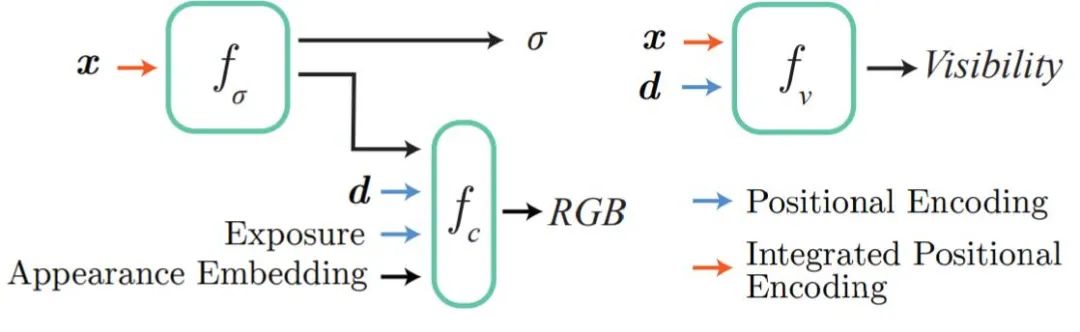
Block-NeRF 是一种神经辐射场的变体,可以表征大规模环境。具体来说,该研究表明,当扩展 NeRF 以渲染跨越多个街区的城市场景时,将场景分解为多个单独训练的 NeRF 至关重要。这种分解将渲染时间与场景大小分离,使渲染能够扩展到任意大的环境,并允许对环境进行逐块更新。
该研究采用几项架构更改,使得 NeRF 对数月内不同环境条件下捕获的数据具有鲁棒性,为每个单独的 NeRF 添加了外观嵌入、学习姿态细化和可控曝光,并提出了一种用于对齐相邻 NeRF 之间外观的程序,以便无缝组合。
《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》是 UC Berkeley 研究人员在 ECCV 2020 上的一篇论文,获得了最佳论文提名。其提出一种隐式 3D 场景表征,不同于显示场景表征(如点云、网格 mesh),其原理是求解穿过场景的任何光线的颜色,从而渲染合成新视角的 2D 场景图片。
NeRF 在给定一组姿态相机图像的情况下,实现了照片般逼真的重建和新型视图合成。NeRF 早期的工作往往侧重于小规模和以对象为中心的重建。尽管现在有些方法可以重建单个房间或建筑物大小的场景,但这些方法仍然范围有限,不能扩展到城市规模的环境。由于模型容量有限,将这些方法应用于大型环境通常会导致明显的伪影和低视觉保真度。
重建大规模环境在自动驾驶、航空测量等领域具有广泛应用前景。例如创建大范围的高保真地图,为机器人定位、导航等应用提供先验知识。此外,自动驾驶系统通常通过重新模拟以前遇到的场景来进行评估,然而任何与记录存在的偏差都可能改变车辆的轨迹,因此需要沿着路径进行高保真的视图渲染。除了基本的视图合成,以场景为条件的 NeRF 还能够改变环境照明条件,例如相机曝光、天气或一天中不同的时间,这可用于进一步增强模拟场景。
![]()
如上图所示,谷歌此次提出的 Block-NeRF 是一种通过使用多个紧凑的 NeRF 表征环境来实现大规模场景重建的方法。在推理时,Block-NeRF 无缝结合给定区域的相关 NeRF 的渲染。上图的示例使用 3 个月内收集的数据重建了旧金山的阿拉莫广场社区。Block-NeRF 可以更新环境的各个块,而无需对整个场景进行重新训练。
重建如此大规模的环境会带来额外的挑战,包括瞬态物体(汽车和行人)的存在、模型容量的限制以及内存和计算限制。此外,在一致的条件下,极不可能在一次捕获中收集如此大环境的训练数据。相反,环境不同部分的数据可能需要来自不同的数据收集工作,这会在场景几何(例如,建筑工作和停放的汽车)以及外观(例如,天气条件和一天中不同的时间)中引入差异。
该研究通过外观嵌入和学习姿态细化来扩展 NeRF,以应对收集到的数据中的环境变化和姿态错误,同时还为 NeRF 添加了曝光条件,以提供在推理过程中修改曝光的能力。添加这些变化之后的模型被研究者称为 Block-NeRF。扩大 Block-NeRF 的网络容量将能够表征越来越大的场景。然而,这种方法本身有许多限制:渲染时间随着网络的大小而变化,网络不再适合单个计算设备,更新或扩展环境需要重新训练整个网络。
为了应对这些挑战,研究者提出将大型环境划分为多个单独训练的 Block-NeRF,然后在推理时动态渲染和组合。单独建模这些 Block-NeRF 可以实现最大的灵活性,扩展到任意大的环境,并提供以分段方式更新或引入新区域的能力,而无需重新训练整个环境。要计算目标视图,只需渲染 Block-NeRF 的子集,然后根据它们相对于相机的地理位置进行合成。为了实现更无缝的合成,谷歌提出了一种外观匹配技术,通过优化它们的外观嵌入,将不同的 Block-NeRF 进行视觉对齐。
![]()
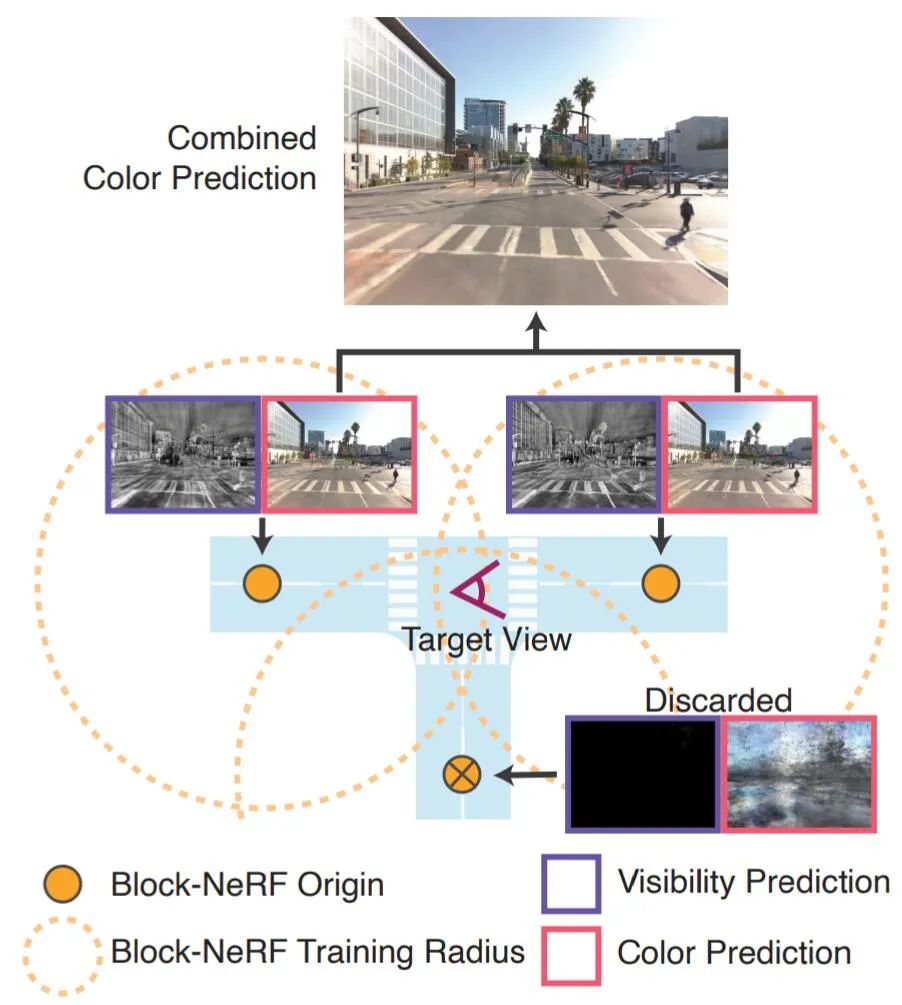
图 2:重建场景被分成了多个 Block-NeRF,每个 Block-NeRF 都在特定 Block-NeRF 原点坐标(橙色点)的某个原型区域(橙色虚线)内的数据上进行训练。
该研究在 mipNeRF 的基础上构建了 Block-NeRF 实现,改善了因输入图像从许多不同距离观察场景造成的损害 NeRF 性能的混叠问题。研究人员结合了来自 NeRF in the Wild (NeRF-W) 的技术,该技术在将 NeRF 应用于 Photo Tourism 数据集中的地标时,为每个训练图像添加一个潜在代码以处理不一致的场景外观。NeRF-W 从数千张图像中为每个地标创建一个单独的 NeRF,而谷歌的新方法结合了许多 NeRF,从数百万张图像中重建一个连贯的大环境,并结合了学习相机姿态细化。
![]()
图 3. 新模型是 mip-NeRF 中提出的模型的扩展。
一些基于 NeRF 的方法使用分割数据来隔离和重建视频序列中的静态和动态对象(如人或汽车)。由于该研究主要关注重建环境本身,所以在训练期间简单地选择屏蔽掉动态对象。
为了动态选择相关的 Block-NeRF 进行渲染,并在遍历场景时以平滑的方式进行合成,谷歌优化了外观代码以匹配光照条件,并使用基于每个 Block-NeRF 到新视图的距离计算的插值权重。
鉴于数据的不同部分可能在不同的环境条件下被捕获,算法遵循 NeRF-W 并使用生成式潜在优化(Generative Latent Optimization,GLO)来优化 perimage 外观嵌入向量。这使得 NeRF 可以解释几个外观变化的条件,例如变化的天气和照明。同时还可以操纵这些外观嵌入,以在训练数据中观察到的不同条件之间进行插值(例如多云与晴朗的天空,或白天和黑夜)。
![]()
图 4. 外观代码允许模型展示出不同的照明和天气条件。
整个环境可以由任意数量的 Block-NeRF 组成。为了提高效率,研究人员利用两种过滤机制仅渲染给定目标视点的相关区块,这里只考虑目标视点设定半径内的 Block-NeRF。此外,系统对于每个候选者都会计算相关的可见性。如果平均可见度低于阈值,则丢弃 Block-NeRF。图 2 提供了一个可见性过滤的示例。可见性可以快速计算,因为它的网络独立于颜色网络,并且不需要以目标图像分辨率进行渲染。过滤后,通常有 1 到 3 个 Block-NeRF 需要合并。
![]()
图 5. 谷歌的模型包含曝光条件,这有助于解释训练数据中存在的曝光量变化,允许用户在推理过程中以人类可解释的方式更改输出图像的外观。
为了重建整个城市场景,研究人员在录制街景时捕获长期序列数据(超过 100 秒),并在几个月内在特定目标区域重复捕获不同序列。谷歌使用从 12 个摄像头捕获的图像数据,这些摄像头共同提供 360° 视图。其中 8 个摄像头从车顶提供完整的环视图,另外 4 个摄像头位于车辆前部,指向前方和侧面。每个相机以 10 Hz 的频率捕获图像并存储一个标量曝光值。车辆姿态是已知的,并且所有摄像机都经过校准。
借助这些信息,该研究在一个共同的坐标系中计算相应的相机光线原点和方向,同时将相机的滚动快门考虑在内。
![]()
图 6. 当渲染基于多个 Block-NeRF 的场景时,该算法使用外观匹配来获得整个场景的一致样貌。给定一个 Block-NeRF(图左)的固定目标外观,算法会优化相邻 Block-NeRF 的外观以匹配。在此示例中,外观匹配了在 Block-NeRF 中产生一致的夜间外观。
![]()
图 7. 多段数据的模型消融结果。外观嵌入有助于神经网络避免添加云雾几何体来解释天气和光照等环境变化。移除曝光会略微降低了准确度。姿态优化有助于锐化结果并消除重复对象的重影,如在第一行的电线杆上观察到的那样。
谷歌研究人员表示,新方法仍然有一些问题有待解决,比如部分车辆和阴影没有被正确移除,植被因为外观随季节变化而在虚拟环境中变得模糊。同时,训练数据中的时间不一致(例如施工工作)无法被 AI 自动处理,需要手动重新训练受影响的区域。
此外,目前无法渲染包含动态对象的场景限制了 Block-NeRF 对机器人闭环模拟任务的适用性。将来,这些问题或许可以通过在优化过程中学习瞬态对象来解决,或者直接对动态对象进行建模。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com