【机器学习】支持向量机

本文介绍了支持向量机模型,首先介绍了硬间隔分类思想(最大化最小间隔),即在感知机的基础上提出了线性可分情况下最大化所有样本到超平面距离中的最小值。然后,在线性不可分的情况下,提出一种软间隔线性可分方式,定义了一种hinge损失,通过拉格朗日函数和对偶函数求解参数。其次,介绍线性模型中的一种强大操作—核函数,核函数不仅提供了支持向量机的非线性表示能力, 使其在高维空间寻找超平面,同时天然的适配于支持向量机。再次,介绍SMO优化方法加速求解支持向量机,SMO建立于坐标梯度上升算法之上,其思想与EM一致。最后,介绍支持向量机在回归问题上的应用方式,对比了几种常用损失的区别。
作者 | 文杰
编辑 | yuquanle
支持向量机
在线性模型中,Fisher线性判别和线性感知机可以说是以上所有模型的分类依据,前者是映射到一维执其两端进行分类,后者是在高维空间找一个线性超平面将两类分开(两类可扩展到多类)。支持向量机属于后者,但主要有以下几点改进:
1)提出硬间隔线性可分,在感知机的基础上提出了线性可分假设(无损失),最大化最小间隔。
2)提出软间隔线性可分,得到了hinge损失代替感知机的线性损失(后面补充一个线性模型损失对比图)。
3)结合核函数将数据映射到高维空间,使得模型具有非线性能力。
4)具有感知机的一切解释性,同时目标函数的对偶形式是凸二次规划问题。
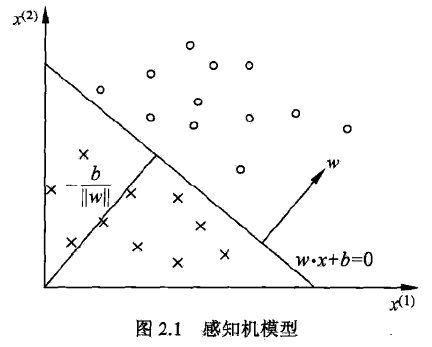
A、硬间隔(最大化最小间隔分类器)
线性感知机中由于没有线性可分假设,所以其目标函数定义为最小化错分样本的损失,而硬间隔SVM则提出了一个线性可分假设,即样本在高维空间中线性可分,那么使得两类分开的超平面一定有无限个。硬间隔SVM则在这些超平面中找出最优的(即所有样本到超平面距离加和最小化),所以有如下目标函数:
其中
为点到平面的几何间隔,去掉系数为函数间隔。最大化最小间隔分类器则采用等价形式—使得最难分的样本离超平面距离尽可能的大—最大化最小间隔分类器:
令
有:
到此,上式为硬间隔分类器的原问题最终形式。上述问题可使用拉格朗日乘子法和对偶问题进行求解。
拉格朗日函数:
其中
由Fritz John条件得出,
为互补松弛条件,互补松弛条件与支持向量有密切关系。由上述约束条件有:
将上式带入到拉格朗日函数,得到关于
表示的函数:
最大化关于
的函数即为原问题的对偶问题,如下:
解出上式目标函数
后,有
:
其中可以看出,w和b有样本点与
內积确定。
但是回过头来想,线性可分假设是不现实,所以SVM在硬间隔线性可分的基础上提出软间隔线性可分。即允许线性不可分,但是需要进行一定的惩罚。如下图为软间隔线性可分,其中在支持向量里面的点和错分的样本为线性不可分的点,虚线上的点为支持向量。
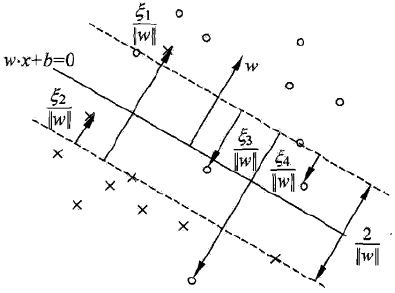
线性不可分意味着某些样本不满足函数间隔大于
同时对于线性不可分的样本进行惩罚,因此目标函数变为:
因此最终的线性不可分SVM的目标函数如下:
拉格朗日函数:
由上述约束条件有:
将上式带入到拉格朗日函数,得到目标函数关于
最大化关于
解出上式目标函数
可以看出,w和b由样本点与
对比硬间隔和软间隔SVM发现两者的对偶问题非常相似,唯一不同的在于
下面根据
当
当
当
当
当
核函数的应用主要是解决线性不可分问题,通过选择合适的核函数将样本从低维线性不可分映射到高维之后容易线性可分,本质上是一次空间上的非线性变换(特征映射),核函数可以嫁接到很多线性模型上,使其具有非线性能力,只是核函数的选择是一件难定的事。
而SVM与核函数有着天然的契合度,因为在SVM的对偶问题中,需要计算样本之间的內积,而核函数的引入则可以使得內积操作直接在核函数中隐式完成。
在上式中有
直接定义
一般常采用的核函数有:
线性核
多项式核
高斯核
拉普拉斯核
sigmoid核
然而核技巧中,最盲目的是如何选择合适核函数,或者多核。
这里需要解释的是,SVM对核函数有一个自身的要求,核的大小一定是
SVM优化问题是一个典型的带约束凸二次规划,传统的梯度方法不能直接应用于带约束优化问题,下面先介绍一种坐标上升优化算法,算法的思想是对于多个参数的优化求解问题,可以每次只考虑一个变量,而固定其他所有变量,对一个变量进行目标优化,内循环每一个变量进行优化,外循环直到迭代到收敛。其收敛性类似于EM算法。
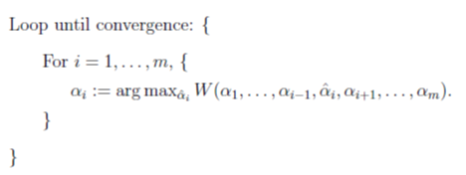
因为内层循环每次只改变一个变量,所以坐标上升算法的搜索路径与坐标轴平行。
然而,如果每次只改变一个变量来优化SVM,那么必然不满足
1)为了满足
2)在选择两个变量进行优化时,采用启发式搜索策略,主动变量选择违反KKT条件最严重的一个变量
现在来看SMO算法,固定m-2个变量不变,将目标函数转化为关于
其中
为了求解两个变量的二次规划问题,首先我们分析约束条件,可以看出
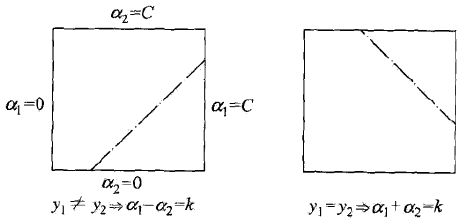
至于对角线的位置取决于当前
当
当
其中L是为了保证
同样,由于我们首先优化的是
求导后得到:
记
所以:
回到上下剪辑,最终
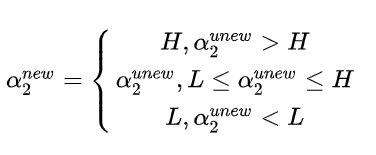
再由
最后更新b,由KKT条件当
当
同样,当
如果两者同时满足条件时,那么两者确定的
下面来看SMO的启发式搜索策略:
1)主动变量选择违反KKT条件最严重的点,即优先判断支持向量上的点是否满足KKT条件,其次检验整个训练样本是否满足KKT条件
由上面对
由上面关系,可以知道哪些点在支持向量上,哪些点在支持向量外,哪些点在支持向量内,优先选择支持向量上的点来判断是否违反KKT条件,因为这些点是违反KKT条件最严重的点,也是对超平面最有价值的点。
2)被动变量选择在给定主动变量后,被动变量随之变化范围最大的点,由于前面导出
3)值得注意的是,每次迭代更新
支持向量机回归:
支持向量机回归利用的就是Hinge损失来定义目标函数,同样是线性模型
其中:
可以看出支持向量机回归其实就是借用Hinge损失,而其理论解释值得思考。
损失函数加正则项的一般理解:
机器学习模型中,绝大多数的模型可以理解损失函数加正则项的形式,本文从线性到非线模型中提到的所有模型都可以理解为损失函数加正则项:
其中正则项主要包括 0范数 1范数 2范数,损失函数主要包括以下:
平方损失:
线性损失:
对数损失:
Hinge损失:
指数损失:
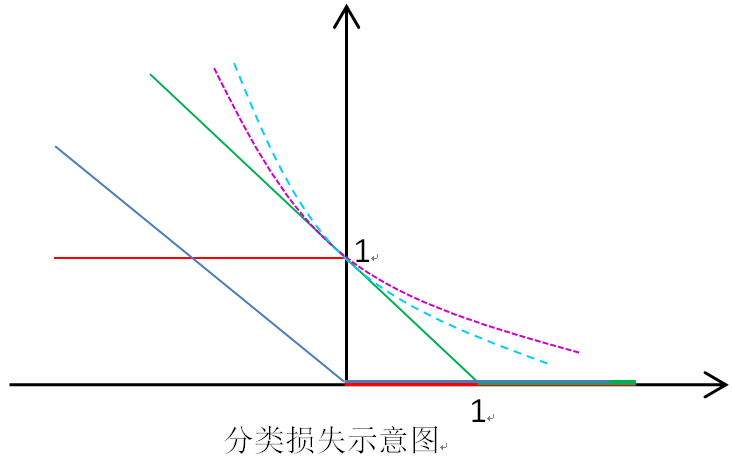
红:0-1损失,蓝:线性损失,绿:Hinge损失,紫虚:对数损失,青虚:指数损失
如何选择合适的损失函数加正则项是模型选择的一个依据,损失函数的选择依赖于数据的分布,而且不同的模型都有各自的特点,在选择模型时很难说那个模型优于其他模型,需要综合各方面因素选择。
F、拉格让日乘子法与对偶问题补充
拉格朗日乘子法通过引入松弛变量得到目标函数局部最优解的必要条件:
拉格朗日乘子法的一般形式:
引入松弛变量
如果
其中
一般来讲,到拉格朗日乘子法之后我们还不能解出目标函数的局部最优解,因为目标函数还是一个引入松弛变量的带约束优化问题。不过我们可以通过分析拉格朗日函数的局部最优解来得到其对偶问题。
在给定
所以,所有约束条件的等价条件是
定义一个对偶问题,即定义一个用
最大化
又因为:
所以对偶问题为原问题提供下界。
代码实战
A、支持向量机
int SVM()
{
///加载数据文件保存到对象dtm的矩阵元素中
///通过矩阵对象中的load函数初始化样本的特征和类别矩阵x,y
//char file[20]="data\\svm.txt";
Matrix x;
//x.LoadData(file);
char file[20]="data\\svm.txt";
x.LoadData(file);
//x = x.transposeMatrix();
Matrix y;
y=x.getOneCol(x.col-1);
x.deleteOneCol(x.col-1);
for(int i=x.row-1;i>100;i--)
//x.deleteOneCol(x.col-1);
x.deleteOneRow(i);
cout<<x.row<<"*"<<x.col<<endl;
cout<<y.row<<"*"<<y.col<<endl;
///调用SMO函数求解SVM模型
cout<<"SVM"<<endl;
SMOP smop;
kTup ktup;//核函数的定义,其中type元素为0表示不适用核函数,非0分别对应不同的核函数
ktup.type=1;
ktup.arg=1.0;
smop.smoP(x,y,0.6,0.001,40,ktup);//
return 0;
}/**
SMO算法的入口函数,其主要功能是初始化SMO所有的参数到结构体OS
确定迭代结束标志,并在所有样本和支持向量上循环的选择合适alpha1,调用inner确定alpha1,
外层循环每一次是迭代优化一对alpha,内层循环才是正真实现迭代优化一对alpha
最后,对smo算法的实现进行检查,通过alpha求解出w,b,并在训练样本上比较其预测值与实际值的差异。
该办法只能检查SMO算法实现的正确性,不能检查SVM的性能。
*/
int smoP(Matrix x,Matrix y,double C,double soft,int maxIter,kTup ktup)
{
int iter=0;
int i;
initOs(x,y,C,soft,ktup);///初始化OS结构体,OS结构体中定义了SMOP算法需要的大部分参数
bool entireSet=true;//标志用于判断当前迭代是针对所有alpha,还是针对0-C之间的部分alpha,这里其实第一个alpha的启发式选择,即选择落在支持向量上的点
int alphaPairsChanged=0;//该参数判断在确定第一个参数之后,是否能选择出符合要求的第二alpha,返回值为1表示能,0为不能
for(iter=0; iter<maxIter&&(alphaPairsChanged>0||entireSet); iter++)
{
//循环结束标志为迭代次数已到预设值,或者是不能再继续优化(对于所有的支持向量上的点都找不到第二个alpha对第一个alpha进行优化后,重新再遍历所有的点寻找可优化的参数对)
//还是找不到则再次遍历支持向量上的点,这次必然也是找不到,才结束迭代
alphaPairsChanged=0;
if(entireSet)
{
for(i=0; i<os.m; i++)
{
alphaPairsChanged+=innerL(i);
cout<<"iter="<<iter<<" i="<<i<<" alphachanged="<<alphaPairsChanged<<" entireSet="<<entireSet<<endl;
}
iter++;
}
else
{
for(i=0; i<os.m; i++)
{
if(os.alphas.data[i][0]>0&&os.alphas.data[i][0]<os.C)//只选择支持向量上的点
continue;
alphaPairsChanged+=innerL(i);
cout<<"iter="<<iter<<" i="<<i<<" alphachanged="<<alphaPairsChanged<<alphaPairsChanged<<" entireSet="<<entireSet<<endl;
}
iter++;
}
if(entireSet)
entireSet=false;
else if(alphaPairsChanged==0)
entireSet=true;
}
///对SMO算法实现的正确性进行验证,输出预测值与实际值的差别,全为0表示在训练样本上预测全对
Matrix ay(os.x.row,1,0,"ss");
for(i=0; i<os.m; i++)
{
ay.data[i][0]=os.alphas.data[i][0]*os.y.data[i][0];
}
Matrix xT = x.transposeMatrix();
Matrix w = w.multsMatrix(xT,ay);
Matrix label = label.multsMatrix(os.x,w);
cout<<os.b<<" ";
for(i=0; i<os.x.col; i++)
{
cout<<w.data[i][0]<<" ";
}
cout<<endl;
cout<<"-----------"<<endl;
///验证训练样本数据,验证SVM实现的正确性
for(i=0; i<os.m; i++)
{
if((label.data[i][0]+os.b)>0)
cout<<1-os.y.data[i][0]<<" ";
else
cout<<0-os.y.data[i][0]<<" ";
}
return 0;
}详细代码:
https://github.com/myazi/myLearn/blob/master/include/SVM.h
本文转载自公众号: AI小白入门,作者文杰
推荐阅读
ELECTRA: 超越BERT, 19年最佳NLP预训练模型
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。



