深度 | 级联MobileNet-V2实现人脸关键点检测(附训练源码)
机器之心投稿
作者:余霆嵩
为了能在移动端进行实时的人脸关键点检测,本实验采用最新的轻量化模型——MobileNet-V2 作为基础模型,在 CelebA 数据上,进行两级的级联 MobileNet-V2 实现人脸关键点检测。首先,将 CelebA 数据作为第一级 MobileNet-V2 的输入,经第一级 MobileNet-V2 得到粗略的关键点位置;然后,依据第一级 MobileNet-V2 的输出,采取一定的裁剪策略,将人脸区域从原始数据上裁剪出来作为第二级 MobileNet-V2 的输入;最后,经第二级 MobileNet-V2 输出最终人脸关键点定位信息。经初步训练,最终网络单模型不到 1M,仅 956KB,单张图片 inference 耗时 6ms(采用 GTX1080 在未优化的 Caffe)。实验结果表明,MobileNet-V2 是一个性能极佳的轻量化模型,可以采用较少的参数获得较好的性能;同时,级联的操作可达到从粗到精的关键点定位。
一、引言
人脸关键点检测也称为人脸关键点检测、定位或者人脸对齐,是指给定人脸图像,定位出人脸面部的关键区域位置,包括眉毛、眼睛、鼻子、嘴巴、脸部轮廓等和人脸检测类似,由于受到姿态和遮挡等因素的影响,人脸关键点检测是一个富有挑战性的任务。
人脸关键点检测方法大致分为三种,分别是基 ASM(Active Shape Model)[1] 和 AAM (Active Appearnce Model)[2,3] 的传统方法;基于级联形状回归的方法 [4];基于深度学习的方法 [5-10]。在深度学习大行其道的环境下,本实验将借鉴深度学习以及级联思想进行人脸关键点检测。
随着手机的智能化及万物物联的兴起,在移动端上部署深度学习模型的需求日益增大。然而,为获得更佳的性能,卷积神经网络的设计,从 7 层 AlexNet[11] 到上千层的 ResNet[12] 和 DenseNet[13],网络模型越来越大,严重阻碍了深度学习在移动端的使用。因此,一种轻量的,高效率的模型——MobileNet-V1[14] 应运而生。MobileNet-V1 最早由 Google 团队于 2017 年 4 月公布在 arXiv 上,而本实验采用的是 MobileNet-V2[15],是在 MobileNet-V1 基础上结合当下流行的残差思想而设计的一种面向移动端的卷积神经网络模型。MobileNet-V2 不仅达到满意的性能(ImageNet2012 上 top-1:74.7%),而且运行速度以及模型大小完全可达到移动端实时的指标。因此,本实验将 MobileNet-V2 作为基础模型进行级联。
二、两级级联 MobileNet-V2
2.1 整体框架及思路
本实验采用两级级联 MobileNet-V2,分别称之为 level_1 和 level_2,由于个人精力有限,level_1 和 level_2 采用完全相同的网络结构。level_1 进行粗略的关键点定位;依据 level_1 输出的关键点进行人脸区域裁剪,获得人脸区域图像作为 level_2 的输入,最终关键点定位信息由 level_2 进行输出。流程如下图所示:
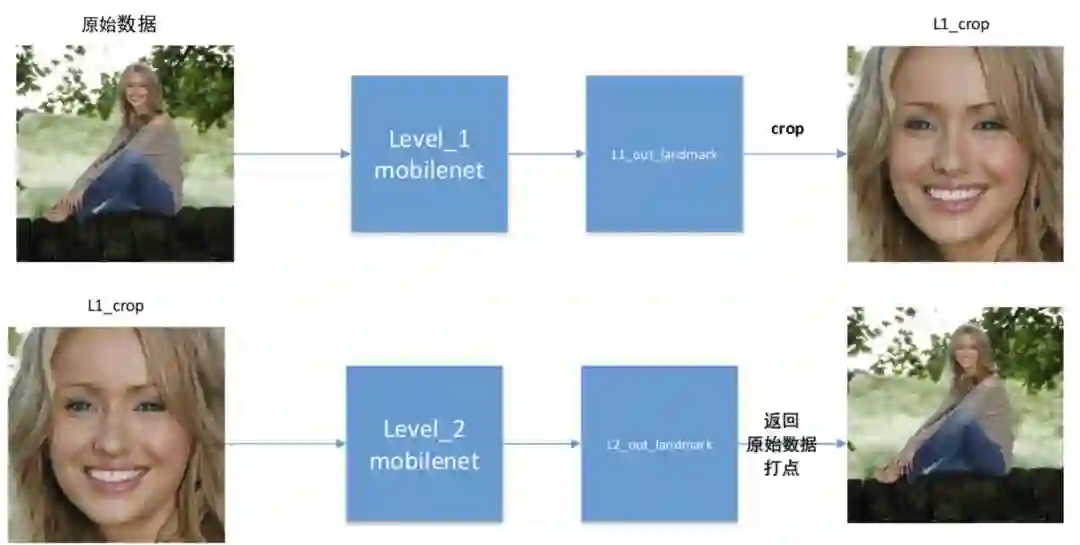
通常进行人脸关键点检测之前,需要进行人脸检测,即将人脸检测获得的人脸图像区域作为人脸关键点检测模型的输入。然而进行人脸检测是相当耗时的,所以,在特定场景下(即确定有且仅有一个人的图像)可以采用 level_1 代替人脸检测步骤,通过 level_1 可获得人脸区域,从而提高整个任务效率和速度。本实验正是采用 level_1 剔除非人脸区域,从而使得后一级的网络可以更为精准的进行关键点定位。
本实验仅做了两级级联,其实还可像 DCNN[5] 那样继续级联,对眼睛,鼻子,嘴巴分别进行预测,或者是学习 Face++[6] 那样,在 68 点的关键点定位中,将 68 点划分为两个区域分别预测。这些都是很好的想法,十分值得借鉴,但个人精力有限,在此仅做了两级级联作为学习,希望大家可以基于 MobileNet-V2 去改进上述两种方法。
2.2 基础模型——MobileNet-V2
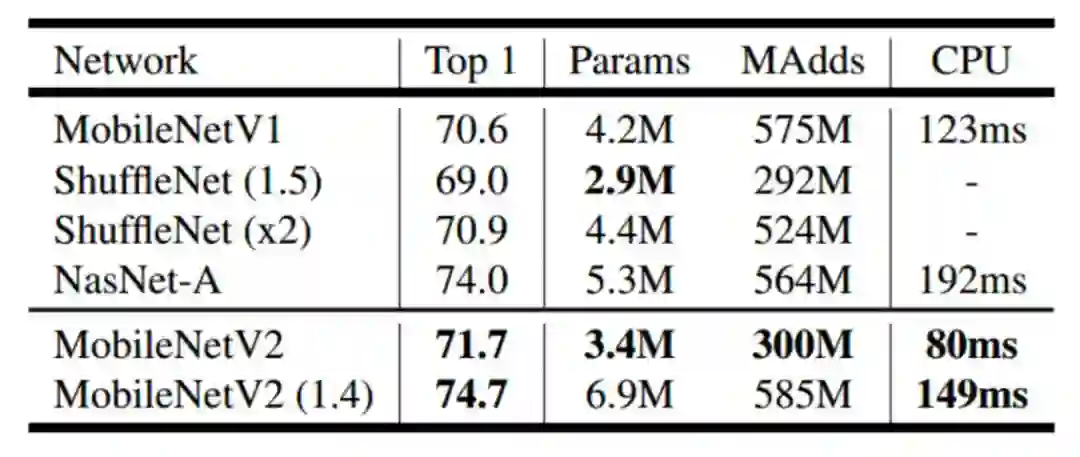
MobileNet-V2[15] 由 Google 团队于 2018 年 1 月公布在 arXiv 上,是一种短小精悍的模型,仅数 M 的模型就在 ImageNet 上获得 74.7% 的准确率(top-1),具体分类性能如下:
原版 MobileNet-V2 网络结构如下图所示:
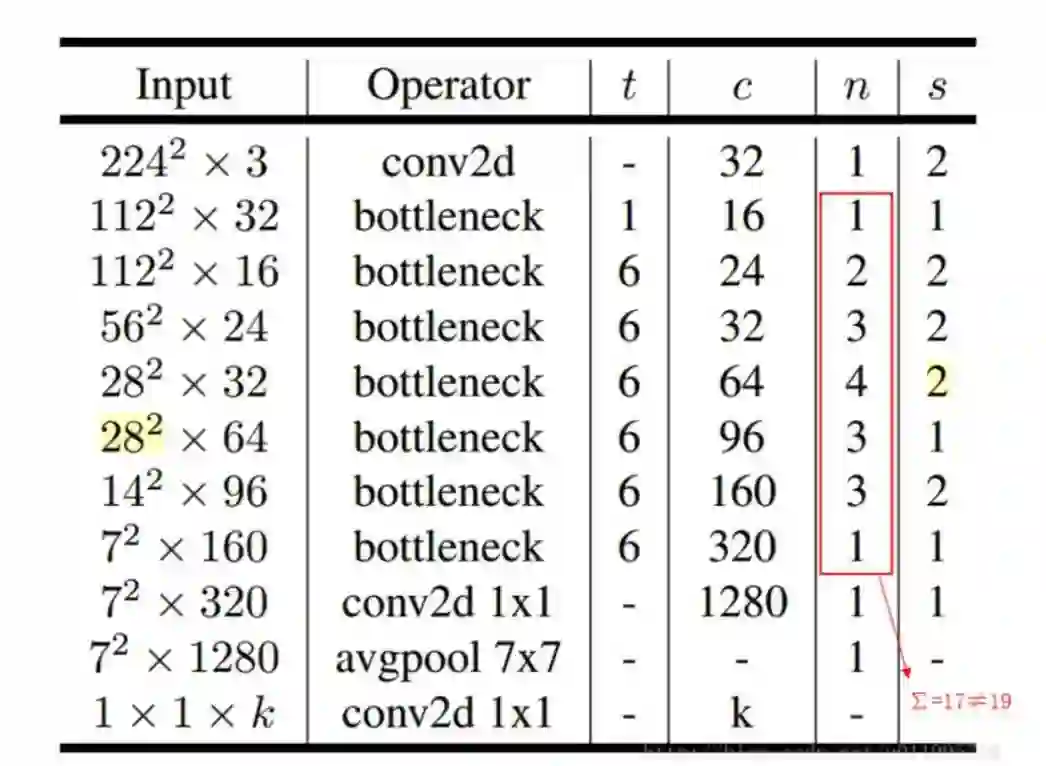
其中:t 表示「扩张」倍数,c 表示输出通道数,n 表示重复次数,s 表示步长 stride。
解释一下原文的有误之处:
1. 第五行,也就是第四个 bottleneck,stride=2,分辨率应该从 28 降低到 14;要么就是 stride=1;
2. 文中提到共计采用 19 个 bottleneck,但是这里只有 17 个。
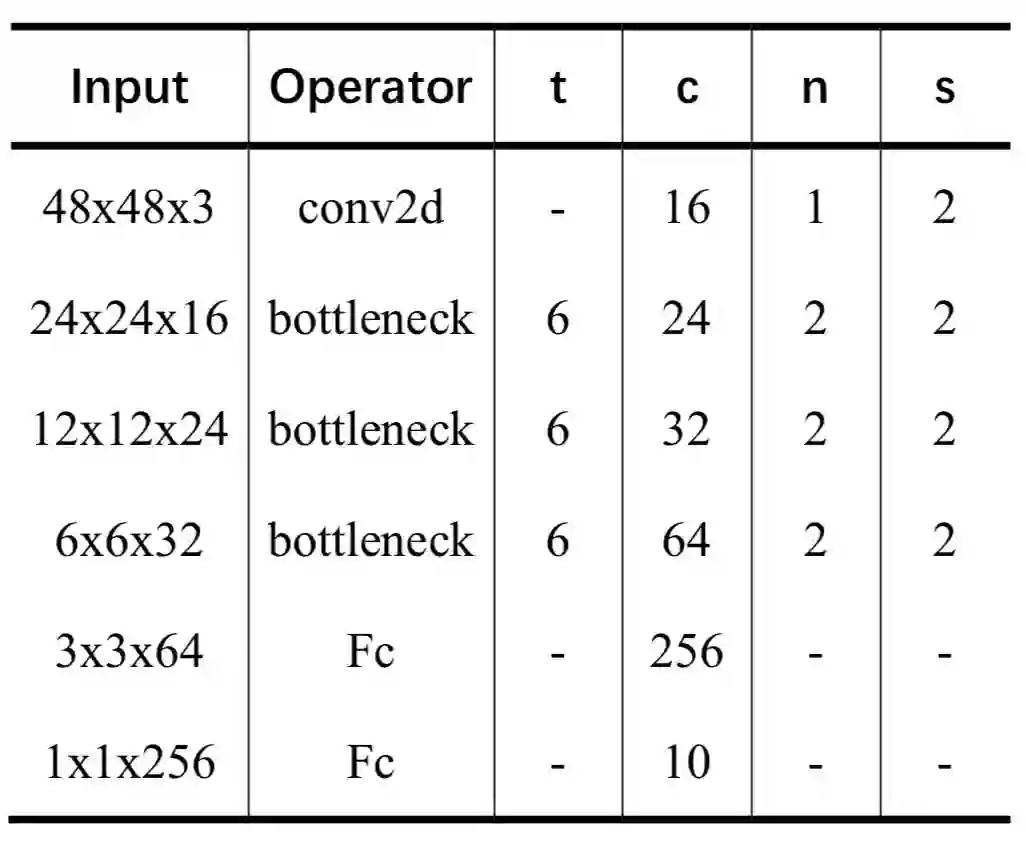
结合本实验任务的需求,设计了一个输入尺寸为 48*48 的 MobileNet-V2(level_1 和 level_2 均采用此网络结构),网络结构如下图所示:
三、实验及结果
3.1 数据集简介
实验数据采用 CelebFaces Attributes Dataset (CelebA) 公开数据集 (http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html),CelebA 数据集是香港中文大学的开放的数据集,此数据集包含 10177 个名人,共计 202599 张图片,每张图片含 5 个关键点标注信息以及 40 个属性标签。经过实验结果分析,此数据集在人脸关键点检测上的困难点在于:
1. 人脸区域面积占图片面积大小不一,有部分图片中的人脸占比相当小。
例如:

2. 人脸角度多样性强,俯仰角(pitch)、偏航角 (yaw) 和横滚角 (roll) 均有,但绝大多数数据为正向无偏角,从而导致正向无偏角检测效果较好,复杂偏角检测效果较差。

3. 噪音图片,图片「不完整」,例如存在大部分黑色区域图片。
3.2 评价指标
这里采用相对误差作为评价指标,相对误差计算公式为:,其中表示输出 landmark 与真实 landmark 的欧氏距离,表示图片对角线的长度。一开始,本实验采用的是双眼距离作为归一化因子,但是 CelebA 数据集并不适合采用双眼距离作为归一化因子,因为在计算时会出现 inf!即两眼在同一位置,导致分母为零,这是 LFW,ALFW 数据集不会出现的情况。两眼距离为零的图片示意图;

3.3 模型训练
level_1 与 level_2 采用相同网络结构,solver 也一致。solver 为:

level_1 的训练 loss 曲线如图所示:
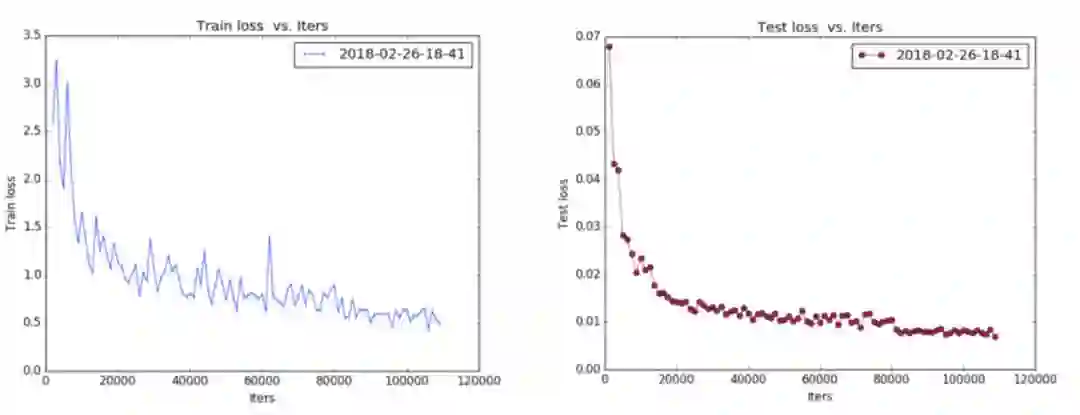
Train loss 大概是在 0.005~0.006,Test loss 是在 0.007~0.008(注:训练的时候 loss_weighs 设置为 100,因此上图数量级上不一致)
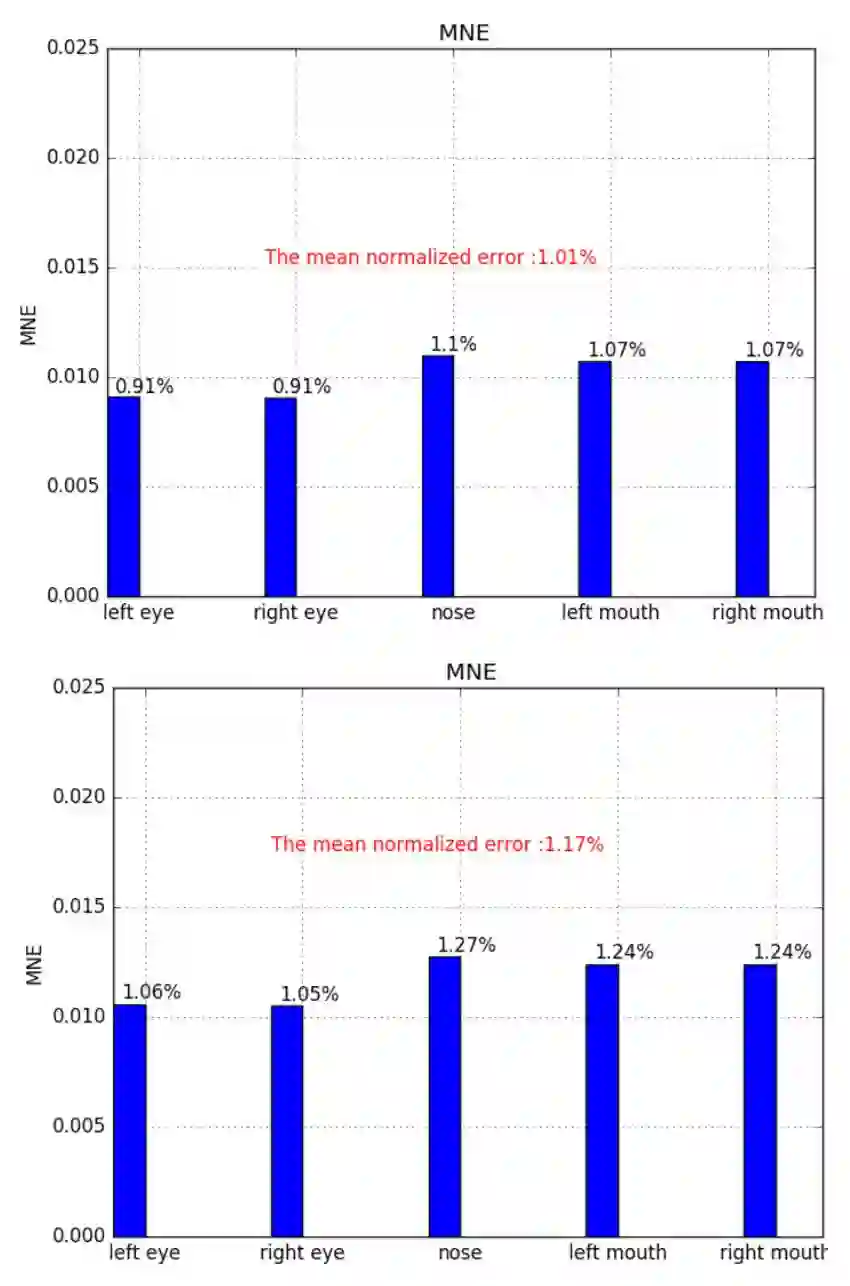
训练和测试的平均误差分别为 1.01% 和 1.17%。5 个点的平均误差如下图所示:
训练集和测试集各点误差分布如图:

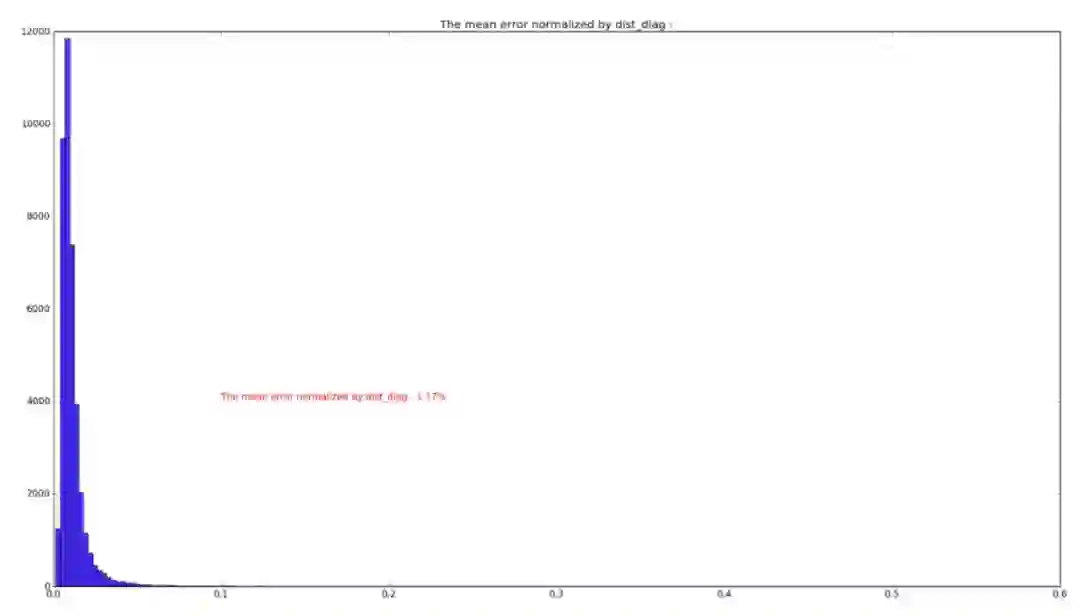
从误差分布图可以看到,误差分布呈高斯分布状,训练与测试的分布形状基本一致,通过误差分布图可知,在训练集中,绝大部分误差小于 5%,因此在选取 level_1 的裁剪阈值时,可参照此图进行调试。
level_1 训练完毕,需要进行图片裁剪,以供 level_2 进行训练。这里采取的裁剪策略为,以 level_1 预测到的鼻子为中心,裁剪出一个正方形,这个正方形的边长为四倍鼻子到左眼的距离。以下图为例,绿色点为 level_1 的预测关键点,红色方框即为裁剪框:

在裁剪时,还需要对部分图片进行丢弃,以此确保裁剪之后的图片能包含完整的人脸。本实验将丢弃阈值设置为 10%,即误差大于 10% 的图片进行丢弃,然而实验结果表明 10% 并不是一个较好的阈值,应该设置为 5% 比较合理。
经过裁剪操作可获得 level_2 的训练数据,接着训练 level_2,level_2 的 loss 曲线如图:
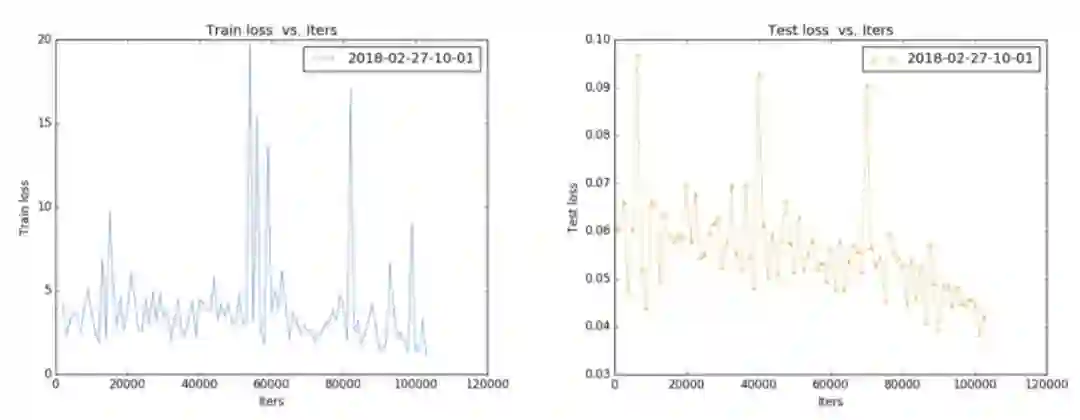
level_2 与 level_1 的曲线有着明显的不同,即曲线出现了很大的浮动,有尖点存在。这是为什么呢?其实是因为 level_1 剪裁出了问题,在裁剪时,将误差小于 10% 的图片保留,用以裁剪。其实这个阈值(10%)还是太大了,以至于裁剪出这一些「不合格」图片。例如:

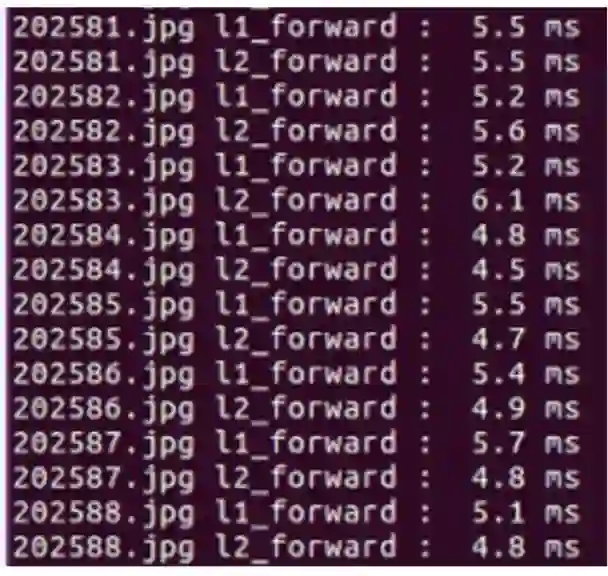
level_2 训练完毕,即可进行级联检测,forward 耗时如图所示:
级联检测效果如下图所示,其中,绿色点为真实 landmark,红色点为 level_1 的预测,蓝色点为 level_2 的预测。可以看到蓝色点比红色点更靠近绿色点:

四、总结与展望
本实验在 CelebA 数据集上,采用最新的轻量化网络——MobileNet-V2 作为基础模型,进行级联卷积神经网络人脸关键点检测实验,初步验证 MobileNet-V2 是短小精悍的模型,并且从模型大小以及运行速度上可知,此模型可在移动端实现实时检测。此实验只是对级联思想的一个简单验证,若要获得更高精度的人脸关键点模型,还有很多可改进的地方。在此总结此实验已知的不足之处,供大家参考并改进:
1. level_1 的输入可为 24*24 甚至更小,只要保证能依据输出的 landmark 来裁剪处人脸区域即可;
2. level_1 的裁剪策略相对「拙劣」,可依据具体应用场景,提出不同的裁剪策略,确保输入到 level_2 的图片包含整个人脸;
3. 模型训练不足,未完全收敛,可对 solver 进行修改,获得更好的模型;
4. 可增加第三级模型,分别对眼睛,鼻子,嘴巴进行检测,从而获得更精确定位点;
5. 对于具体应用场景,应依据困难样本,需要针对性的做数据增强,例如 CelebA 中,正向无偏角人脸较多,而有俯仰角、偏航角和横滚角的图片占少数,从而导致模型对含偏角的图片预测效果较差;
6. 未进行模型压缩,若需要部署,则要进行模型压缩,从而获得更小的模型;
7. Caffe 对 depth-wise convolution 的支持并不友好,从而在 Caffe 下体现不出 MobileNet-V2 的高效,可尝试 TensorFlow 下进行;
8. 欢迎大家补充
下一步工作:
1. 针对以上不足进行改进;
2. 寻找有兴趣的朋友进行 68 点关键点检测实验,并进行模型压缩,获得更小更好的网络。
本实验所有代码可在 GitHub 上获得:https://github.com/tensor-yu/cascaded_mobilenet-v2
详细训练步骤可参见博客:http://blog.csdn.net/u011995719/article/details/79435615
欢迎大家提出宝贵的意见和建议。
参考文献
[1] T.F. Cootes, C.J. Taylor, D.H. Cooper, et al. Active Shape Models-Their Training and Application[J]. Computer Vision and Image Understanding, 1995, 61(1):38-59.
[2] G. J. Edwards, T. F. Cootes, C. J. Taylor. Face recognition using active appearance models[J]. Computer Vision—Eccv』, 1998, 1407(6):581-595.
[3] Cootes T F, Edwards G J, Taylor C J. Active appearance models[C]// European Conference on Computer Vision. Springer Berlin Heidelberg, 1998:484-498.
[4] Dollár P, Welinder P, Perona P. Cascaded pose regression[J]. IEEE, 2010, 238(6):1078-1085.
[5] Sun Y, Wang X, Tang X. Deep Convolutional Network Cascade for Facial Point Detection[C]// Computer Vision and Pattern Recognition. IEEE, 2013:3476-3483.
[6] Zhou E, Fan H, Cao Z, et al. Extensive Facial Landmark Localization with Coarse-to-Fine Convolutional Network Cascade[C]// IEEE International Conference on Computer Vision Workshops. IEEE, 2014:386-391.
[7] Zhang Z, Luo P, Chen C L, et al. Facial Landmark Detection by Deep Multi-task Learning[C]// European Conference on Computer Vision. 2014:94-108.
[8] Wu Y, Hassner T. Facial Landmark Detection with Tweaked Convolutional Neural Networks[J]. Computer Science, 2015.
[9] Zhang K, Zhang Z, Li Z, et al. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J]. IEEE Signal Processing Letters, 2016, 23(10):1499-1503.
[10] Kowalski M, Naruniec J, Trzcinski T. Deep Alignment Network: A Convolutional Neural Network for Robust Face Alignment[J]. 2017:2034-2043.
[11] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
[12] He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]// Computer Vision and Pattern Recognition. IEEE, 2016:770-778.
[13] Huang G, Liu Z, Maaten L V D, et al. Densely Connected Convolutional Networks[C]// CVPR. 2017.
[14] Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[J]. 2017.
[15] Sandler M, Howard A, Zhu M, et al. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification,axXiv.
作者简介:余霆嵩,广东工业大学研三学生,研究方向:关键点定位,模型压缩,Email:yts3221@126.com
本文为机器之心投稿,转载请联系作者获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com

