人脸专集3 | 人脸关键点检测(下)—文末源码
今天继续上期的《人脸关键点检测》,精彩的现在才真正的开始,后文会陆续讲解现在流行的技术,有兴趣的我们一起来学习!




近年来,深度学习成为解决计算机视觉问题的常用工具。对于人脸关键点检测和跟踪,有从传统方法向基于深度学习的方法转变的趋势。
在早期的工作中(Wu, Y., Wang, Z., Ji, Q.: Facial feature tracking under varying facial expressions and face poses based on restricted boltzmann machines. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 3452–3459 (2013)),深层Boltzmann模型,一个概率深度模型,被用来捕捉由于姿态和表情而引起的面部形状变化,用于人脸里程碑的检测和跟踪。近年来,卷积神经网络模型成为人脸关键点检测,主要是深度学习模型,并且大多采用全局直接回归或级联回归框架。这些方法大致可分为纯学习法和混合学习法。
纯学习方法直接预测人脸关键点位置,而混合学习方法则将深度学习方法与计算机视觉投影模型相结合进行预测。
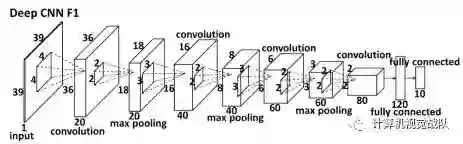
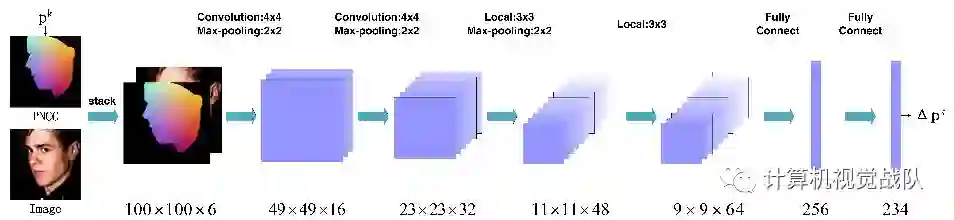
纯学习方法:这类方法使用强大的CNNs模型从人脸图像中直接预测关键点位置。在早期的工作中(Sun, Y., Wang, X., Tang, X.: Deep convolutional network cascade for facial point detection. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 3476–3483 (2013)),它以级联的方式预测了五个人脸关键点。在第一层,它应用一个包含四个卷积层的CNN模型(下图)来预测由面部边界框确定的人脸图像的关键点位置。然后,几个浅层网络对每个点进行局部细化。
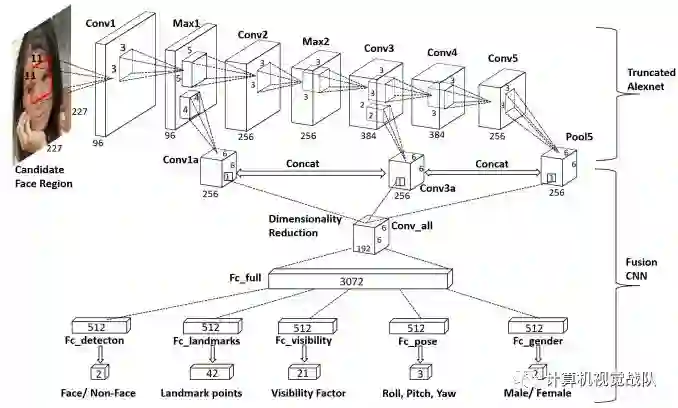
从那以后,在两个方向上都比早起某些工作有一些改进。在第一个方向上,(Zhang, Z., Luo, P., Loy, C., Tang, X.: Facial landmark detection by deep multi-task learning. In: European Conference on Computer Vision, Part II, pp. 94–108(2014)和Zhang, Z., Luo, P., Loy, C.C., Tang, X.: Learning deep representation for face alignment with auxiliary attributes. IEEE Transactions on Pattern Analysis and Machine Intelligence 38(5), 918–930 (2016))利用多任务学习的思想来提高性能。直觉是,多个任务可以共享相同的表示,它们的联合关系将提高单个任务的性能。例如,多任务学习与CNN模型相结合,共同预测面部特征、面部头部姿态、面部属性等。在该工作(Ranjan, R., Patel, V.M., Chellappa, R.: Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. CoRR abs/1603.01249 (2016). URL http://arxiv.org/abs/1603.01249)提出了一个类似的多任务CNN框架,以联合执行人脸检测、地标定位、姿态估计和性别识别。不同的是它结合了多个卷积层的特征,以利用粗特征表示和精细特征表示。
在第二个方向上,一些工作改进了方法的级联程序(Sun, Y., Wang, X., Tang, X.: Deep convolutional network cascade for facial point detection. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 3476–3483 (2013))。例如,某paper构造了类似的级联CNN模型来预测更多的点(68个关键点而不是5个)(Zhou, E., Fan, H., Cao, Z., Jiang, Y., Yin, Q.: Extensive facial landmark localization with coarse-to-fine convolutional network cascade. In: IEEE International Conference on Computer Vision Workshops, pp. 386–391 (2013))。它从所有68个点的预测开始,并逐步将预测分解为局部的面部成分。在该paper(Zhang, J., Shan, S., Kan, M., Chen, X.: Coarse-to-fine auto-encoder networks (CFAN) for real-time face alignment. In: European Conference on Computer Vision, Part II, pp. 1–16 (2014))中,深层自动编码器模型用于执行相同的级联关键点搜索。而在(Trigeorgis, G., Snape, P., Nicolaou, M.A., Antonakos, E., Zafeiriou, S.: Mnemonic descent method: A recurrent process applied for end-to-end face alignment. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4177–4187. Las Vegas, NV, USA (2016))中,Trigeorgis等人没有以级联的方式训练多个网络,训练了一种深度卷积递归神经网络(RNN),用于端到端面部关键点的检测,以模拟级联行为。级联阶段嵌入到RNN的不同时间切片中。
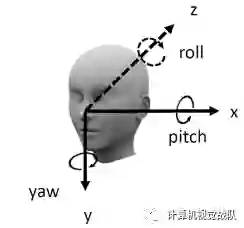
混合深度方法将CNN与3D视觉相结合,如投影模型和三维形变形状模型(上图)。它们不是直接预测二维面部关键点位置,而是预测三维形状可变形模型系数和头部姿态。然后,通过计算机视觉投影模型确定二维关键点位置。例如,(Zhu, X., Lei, Z., Liu, X., Shi, H., Li, S.: Face alignment across large poses: A 3d solution. In: IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV (2016))建立了一个密集的三维人脸模型。然后,采用迭代级联回归框架和深度CNN模型对三维人脸形状系数和姿态参数进行更新。在每一次迭代中,利用视觉投影模型将三维形状投影到二维,并将二维形状作为CNN回归预测模型的附加输入,以融合目前估计的三维参数。类似地,(Kanade, T., Cohn, J.F., Tian, Y.: Comprehensive database for facial expression analysis. In: IEEE International Conference on Automatic Face and Gesture Recognition, pp. 46–53)在第一个级联CNN模型中使用整个面部外观来预测三维形状参数和姿态的更新,而在后期级联CNN模型中使用局部斑块来细化关键点。
与纯学习方法相比,混合方法的三维形状变形模型和姿态参数是表示二维关键点位置的更为紧凑的方法。因此,CNN中需要估计的参数较少,形状约束可以显式地嵌入到预测中。此外,由于引入了三维姿态参数,它们可以更好地处理姿态变化。
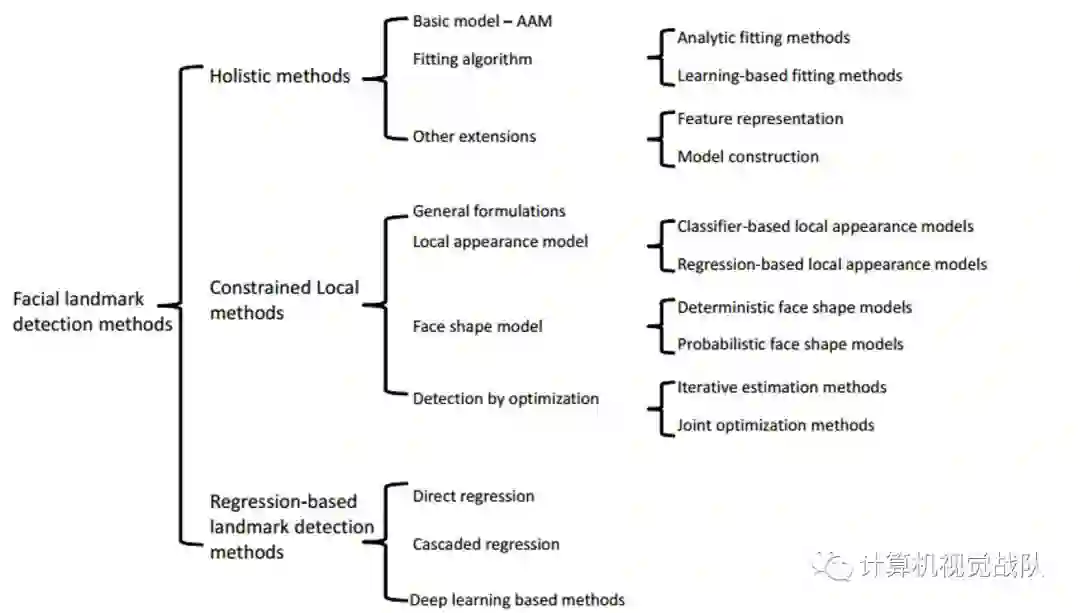
在之前讲解中,我们讨论了面部表情三种主要类别中的关键点检测方法:整体方法、约束局部方法(CLM)和基于回归的方法。三种主要的方法存在着相似之处和相互关系。
首先,整体方法和CLMs都将使用显式构造的面部形状模型捕捉全局面部形状模式,这些模型通常在它们之间共享。CLMs改进了整体方法,因为它们使用局部外观,而不是整体的面部外观。所需的动机是将整体的面部外观建模更困难,并且局部图像修补程序与整体外观模型相比,光照改变和面部遮挡更加鲁棒。
第二,基于回归的方法,尤其是用于级联回归方法与整体AAM共享相似的直觉。例如,它们通过拟合外观来估计关键点,并且它们全部可以被配制成非线性的平方问题。然而,整体方法预测2D形状,外观模型系数通过拟合整体外观模型,而级联回归方法直接通过拟合局部外观而不显式2D形状模型来预测关键点。该配件整体方法的问题可以用基于LearnBased的方法或分析方式来解决,如前面所讨论的那样,所有级联回归方法执行通过学习进行估计。虽然整体模型的基于学习的拟合方法通常使用相同的方法,用于以迭代方式进行系数更新的模型,级联回归方法以级联方式学习不同的回归模型。
AAM模型在之前讨论为一种特定类型的整体方法非常类似于监督下降方法(SDM)(Xiong, X., De la Torre Frade, F.: Supervised descent method and its applications to face alignment. In: IEEE International Conference on Computer Vision and Pattern Recognition (2013))作为一种特定类型的方法级联回归方法。两个级联学习从形状索引特征到形状(系数)更新的映射的模型。经训练的模型在当前级联阶段中,将修改训练用于在下一状态下训练回归模型的数据。虽然以前的整体方法适合整体外观并预测模型系数,但SDM拟合局部外观并预测关键点位置。
第三,在CLM中使用的基于regressional的局部外观模型中存在相似性。之前的基于回归方法,两者都预测从关键点位置的初始猜测的位置更新。以前的方法独立地预测每个关键点位置,而后来的方法预测它们是联合的,形状约束可以隐式嵌入。以前的方法通常执行一步预测,相同的回归模型,而后面的方法可以以级联方式应用不同的回归函数。
第四,与整体方法和约束局部方法相比,基于回归的方法可能会更有希望。基于回归的方法绕过显式面部形状建模并隐式嵌入人脸形状模式约束。基于回归的方法直接预测关键点,而不是整体方法中的模型系数。直接预测形状通常可以由于小模型系数,实现较好的精度错误可能导致大的关键点误差。



下期我们针对各种因素进行讲解,并在流行的数据集上的实验效果做详细描述,最后给出未来趋势及着重点。
End





https://github.com/luoyetx/deep-landmark
https://github.com/yinguobing/cnn-facial-landmark
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。