AAAI 2020 开源论文 | 用于深度立体匹配的自适应单峰匹配代价体滤波

©PaperWeekly 原创 · 作者|张承灏
学校|中科院自动化所硕士生
研究方向|深度估计

论文链接:https://arxiv.org/abs/1909.03751
源码链接:https://github.com/DeepMotionAIResearch/DenseMatchingBenchmark

研究背景
立体匹配算法分为四个步骤:匹配代价计算,代价聚合,视差回归和视差精修。其中,匹配代价的计算是至关重要的一步。根据匹配代价计算方式的不同,可以将基于深度学习的视差估计算法分为两类。
1. 基于相关性的匹配代价计算。以 DispNetC [1] 为代表,利用相关层对左右图像的特征计算匹配代价,构造 3 维的匹配代价体,最后使用 2D 卷积回归视差图。iResNet [2] 通过引入堆叠的精修子网络进一步提升了性能。
2. 基于 3D 卷积的匹配代价计算,以 GC-Net [3] 为代表,通过将左右图的特征体进行连接来构造 4 维的匹配代价体,最后使用 3D 卷积和可导的”winner takes all (WTA)”策略来得到视差图。基于此改进的 PSMNet [4] 和 GANet [5] 等模型是目前性能较好的网络。
本文属于第二类方法,基于 PSMNet 对匹配代价体增加自适应的单峰滤波约束,从而使得预测的代价匹配体在真值附近能够得到和真值一致的分布,如图 1 所示。第 1、3 行分别是 PSMNet 和 AcfNet 预测的代价分布,第 2、4 行分别是真值的代价分布。PSMNet 在真值附近生成了两个最小值的峰值,这与真值的分布不符合。而本文的 AcfNet 在真值附近生成了正确的分布。
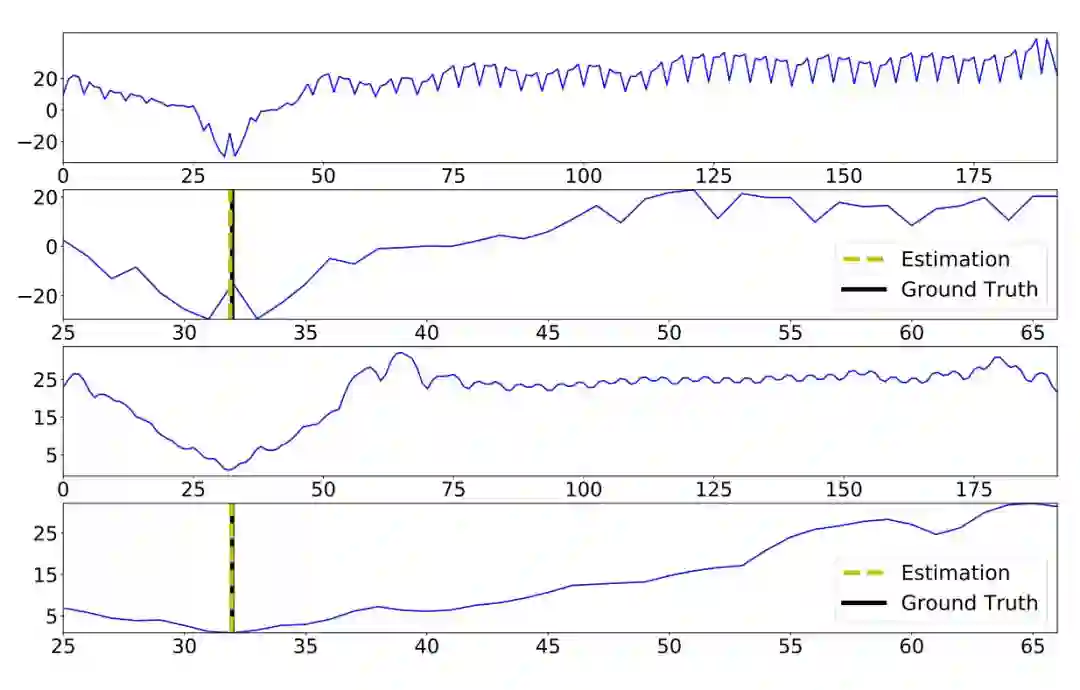
▲ 图1. 沿匹配代价体的视差维度展示的代价分布情况

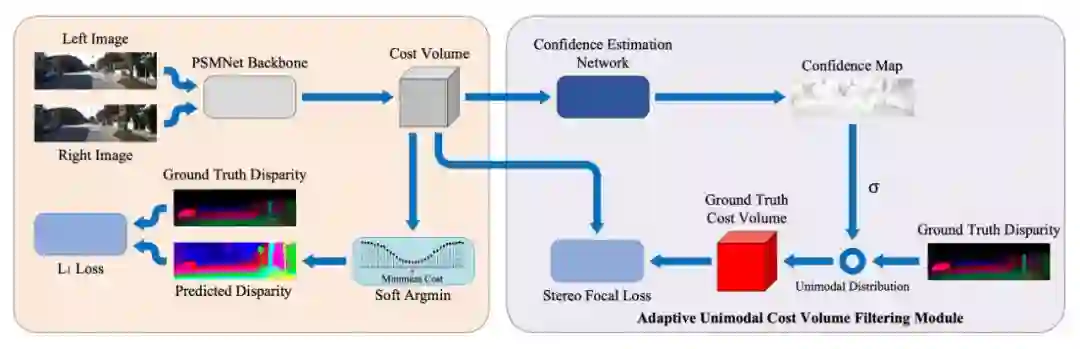
图 2 是 AcfNet 的整体框架图。论文在 PSMNet 的基础上,提出自适应单峰匹配代价体滤波,它作用于匹配代价体上。匹配代价体一方面通过 CENet 得到置信图,结合真值视差形成对匹配代价体进行监督的单峰分布,另一方面通过 soft argmin 来预测视差。
在匹配代价计算中,可能的视差分布是 {0, 1, ..., D-1},那么构建得到的匹配代价体的大小即为 H×W×D(高度×宽度×最大视差值)。形式上,对每个像素包含 D 个代价的匹配代价体定义为 
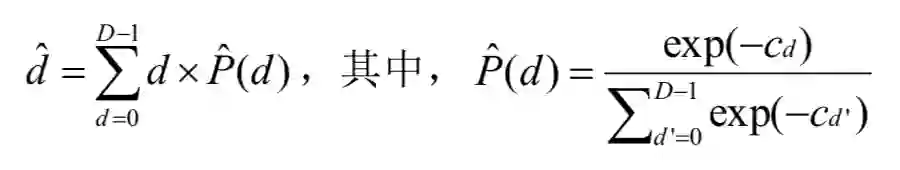
将每个子像素预测的视差和真值视差做 smooth L1 loss 使得整个网络模型是可导的,可以进行端到端的训练。
然而,这种监督信息还是不够完善的,可能有无数种模型权重来实现正确的插值结果。中间产物代价匹配体由于其灵活性很容易过拟合,因为许多学习不正确的匹配代价体可能会插值接近真实的视差值。为了解决这个问题,根据匹配代价体的单峰特性,直接对其进行监督。
匹配代价体是用来反映候选匹配像素对之间的相似性的,因此真实的匹配像素对应该具有最小的代价,这反映出在真值视差的附近应该是单峰分布的,这种单峰分布可以定义为:
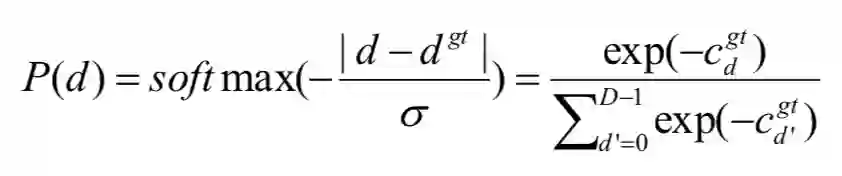
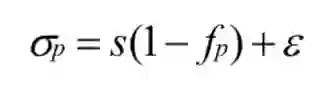
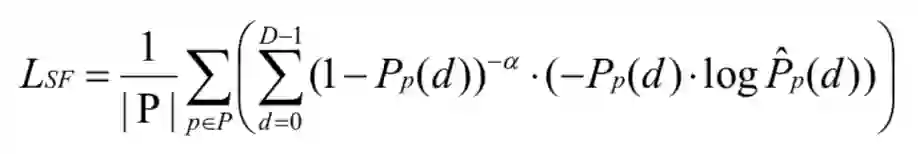
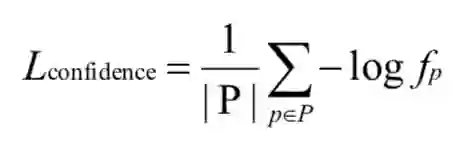

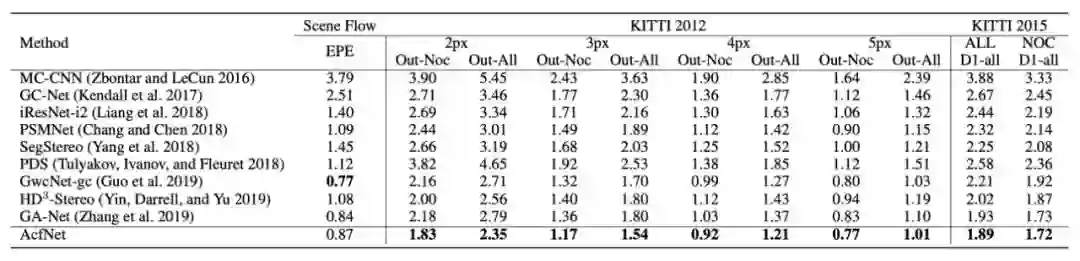
▲ 表1. AcfNet在Sceneflow,KITTI 2015和KITTI 2012上的性能

▲ 图3. Sceneflow数据集上的可视化结果

▲ 图4. KITTI 2015数据集上的可视化结果

本文的创新点比较新颖,关注的是以往被忽略的匹配代价体的监督问题,从理论上得出匹配代价体的分布是单峰分布。作者所提出的 CENet 和 stereo focal loss 也直观而有效。行文写作简洁明了,值得学习。
立体匹配方法最大的难点是缺少泛化性能,本文对匹配代价体的概率分布施加约束,能够作为辅助的监督信息,适用于多种基于匹配代价体的立体匹配方法。

[1] Mayer, N., Ilg, E., Hausser, P., Fischer, P., Cremers, D., Dosovitskiy, A., Brox, T.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4040–4048 (2016)
[2] Liang, Z., Feng, Y., Guo, Y., Liu, H., Chen, W., Qiao, L., Zhou, L., Zhang, J.: Learning for disparity estimation through feature constancy. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2811–2820 (2018)
[3] Kendall, A., Martirosyan, H., Dasgupta, S., Henry, P.: End-to-end learning of geometry and context for deep stereo regression. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 66–75 (2017)
[4] Chang, J.R., Chen, Y.S.: Pyramid stereo matching network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5410–5418 (2018) [5] Zhang, F., Prisacariu, V., Yang, R., Torr, P.H.: Ga-net: Guided aggregation net for end-to-end stereo matching. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 185–194 (2019)

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码


