一种崭新的长尾分布下分类问题的通用算法|NeurIPS 2020

极市导读
本文从因果分析的角度,利用一种非常优雅、且非常简单实现,提出了一种崭新的长尾问题的通用解决思路,能够广泛适用于各种不同类型的任务。
Long-Tailed Classification系列之四(终章):
1. (往期) 长尾分布下分类问题简介与基本方法
2. (往期) 长尾分布下分类问题的最新研究
3. (往期) 长尾分布下的物体检测和实例分割最新研究(https://zhuanlan.zhihu.com/p/163186777)
4. (本期) 一种崭新的长尾分布下分类问题的通用算法
作为这个系列的最后一章,本文主要介绍我们组今年被NeurIPS 2020接收的论文《Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect》。目前代码已经在Github上开源,链接如下:
https://github.com/KaihuaTang/Long-Tailed-Recognition.pytorch
论文链接:https://kaihuatang.github.io/Files/long-tail.pdf
一. Motivation (研究动机)
这个工作从因果分析的角度,利用一种非常优雅的实现,提出了一种崭新的长尾问题的通用解决思路。而且实现非常简单,能够广泛适用于各种不同类型的任务。之前几期介绍了很多过往的工作,然而有几个问题(缺陷)却一直萦绕在我的脑中没有被解决:
-
虽然利用数据集分布的re-sampling和re-weighting训练方法可以一定程度上缓解长尾分布的问题。然而这种利用其实是违背现实学习场景的,他们都需要在训练/学习之前,了解“未来”将要看到的数据分布,这显然不符合人类的学习模式,也因此无法适用于各种动态的数据流。 -
目前长尾分类最优的Decoupling算法依赖于2-stage的分步训练,这显然不符合深度学习end-to-end的训练传统,而论文本身也没有提出让人信服的理由解释为什么特征提取backbone需要在长尾分布下学,而偏偏classifier又需要re-balancing的学。 -
长尾分布下简单的图片分类问题和其他复杂问题(诸如物体检测和实例分割)研究的割裂,目前长尾分布下图片分类问题的算法日趋复杂,导致很难运用于本来框架就很繁琐的检测分割等任务。而我觉得长尾问题的本质都是相似的,真正的解决方案一定是简洁的,可以通用的。
基于上面这些问题,也就最终诞生了我们的这篇工作。我们提出的De-confound-TDE的优势如下:
-
我们的训练过程 完全不依赖于提前获取的数据分布,只需要在传统训练框架的基础上统计一个特征的移动平均向量,并且这个平均特征在训练中并不会参与梯度计算(只在测试时使用)。这也就解决了传统长尾分类方法依赖“提前获取未来数据分布”的问题。 -
尽管我们的测试过程和训练过程有所不同,但我们的 模型是一次训练到位的,并不需要依赖繁琐的多步训练,这大大简化了拓展至其他任务时的修改成本。 -
并且,我们成功的将这个方法运用于图片分类(ImageNet-LT,Long-tailed CIFAR-10/-100)和物体检测/实例分割(LVIS dataset)等多个任务,均取得了最优的结果(截止至我们投稿也就是2020年5月)。 这证明了我们的方法可以作为继re-balancing之后又一个在长尾数据下通用的Strong Single-Stage Baseline。
二. Introduction (简介)
长尾分布这个问题是什么我已经在往期文章里介绍过了,我一直觉得大家普遍运用的re-balancing不是一种方法而更像是一个trick,当我决定做这个task时,我follow的Decoupling给了我启发。他的2-stage训练模式让我意识到,re-balancing确实是有问题的,因为他会破坏backbone的特征学习,而必须为此额外增加一个stage来预训练所有的特征提取部分,并且在后续re-balancing学习中freeze住backbone。但既然backbone可以在原始长尾数据上直接训练,classifier真的需要再利用额外的一步训练来balance吗?还是只是目前没有找到对的方法而已呢?
我认为,需要利用原始的长尾分布来学习特征提取的原因在于,大量的尾部类别其实不足以提供足够的样本来学习鲁棒的特征表达,如果强行利用re-balancing trick只会让模型对尾部类别特征过拟合,而对样本充足的头部类别欠拟合。这也不符合人类的认知习惯,人类描述罕见的物体时,往往是通过和已知常见类的比较,比如我会说狮鹫是有着狮子的身体,鹰的翅膀和头的生物,而不必要单独拿一堆狮鹫的图片出来,让你死记硬背住狮鹫的长相。这就解释了为什么直接利用长尾分布的原始数据学习的特征表达器更好,因为他可以充分的利用优质的头部类指导特征学习,可问题在于我们分类时也是直接记住(狮鹫=狮子+鹰),而不需要额外的再去看很多狮鹫样本来和头部的类做“均衡”啊。

狮鹫(尾部类)=狮子(头部类)+鹰(头部类)
于是我想到了自己CVPR 2020的Unbiased Scene Graph Generation工作,https://zhuanlan.zhihu.com/p/109657521),可类似的技术却依赖场景图生成本身的复杂网络结构和内部有意义的中间节点。这明显不是个通用的方法,比如图片分类的网络模型除了输入图片和输出的预测,中间层没有任何可解释的意义。近似地使用上述方法也没有明显提升。直到有一天我意识到,机器学习和人类学习的区别既然不在数据,那肯定就在学习方法上了,于是我发现优化器(e.g.,SGD,Adam)本身对网络的学习也有很大的影响,尤其是我发现优化器的动量项时,这货不就是在训练数据时引入数据分布,从而产生shortcut的元凶么。我马上就试了下直接去除动量项,当然这个是不work的,结果非常糟糕。因为动量可以大大提升训练的稳定性,使其更容易收敛到较好的区域,尽管长尾分布下这个较好区域明显倾向于头部类,但也比没有动量的优化结果更好。于是,我们最终决定利用因果分析中的一些思想和技术,尝试在保持动量项的同时,在测试时去除他的影响。这样就可以即利用动量“好的部分”,也剔除了动量“坏的部分”(点题!)。
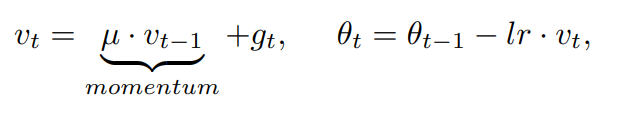
Pytorch中SGD地Momentum实现
三. Recipe (快速食用指南)
在介绍本文复杂的因果图构建和后续推导实现,让同学们失去耐心之前,对于想赶紧快速食用我们方法的同学,我给个4步速成指南吧:
1) 训练时需要De-confound Training,说人话就是classifier需要使用multi-head normalized classifier,即每个类的logits计算如下: ,其中 是超参,K是multi-head的数量。分子部分为正常的无bias项的线性分类器,分母部分可以是任何形式的normalization(公式中是我们自己提出的形式,不过事实上如果分母变成 ,也就是cosine classifier也一样work)。
2) 同时不要忘记在训练时统计一个移动平均特征 , 并将他的单位方向看作是特征对头部类的倾向方向 。
3) 在测试时做counterfactual TDE inference,人话就是从training的logits中剔除我们认为代表对头部类过度倾向的部分,即测试时改用如下公式计算TDE logits:
详细实现可以参考我们的代码文件:
De-confound-TDE
https://github.com/KaihuaTang/Long-Tailed-Recognition.pytorch/blob/master/classification/models/CausalNormClassifier.py
4) 最后,当运用到诸如物体检测,实例分割的任务中时,还需要对background类做特殊处理,因为background类也是一个头部大类,但是对background的bias却是有益的,因为我们需要依赖他来剔除大量琐碎的细节。其计算方式如下,其中i=0代表background类, 是利用原始training的logits计算出的probability, 是利用TDE logits计算出的softmax后的概率。实现可参考链接:
https://github.com/KaihuaTang/Long-Tailed-Recognition.pytorch/blob/master/lvis1.0/mmdet/models/roi_heads/bbox_heads/convfc_bbox_head.py中的KEEP_FG部分。
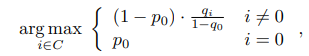
基本只要改classifier,不需要任何额外的训练步骤或复杂的采样算法,是不是很方便。食用完不要忘记引用下我们的工作吖~
四. Causal Graph (因果图构建)
下面就是具体我怎么得出上述的算法。首先,基于我的分析,我们构建了如下的因果图。其中M就是优化器的动量,X是backbone提取的特征,Y是预测。D是特征对头部大类的偏移量。至于为什么会有这个偏移量呢?因为优化器的动量包含了数据集的分布信息,他的动态平均会显著地将优化方向倾向于多数类,这也就造成了模型中的参数会有生成头部类特征的倾向。
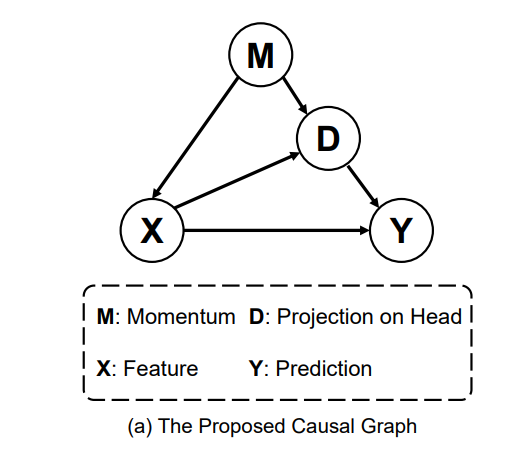
如果对因果图有了解的同学,就会发现这里的M对X和Y是个混淆因子,而D在X-->Y的预测时又会带来中介效应。详细的因果知识背景介绍可以看我一个学弟的知乎文章,https://zhuanlan.zhihu.com/p/111306353。我这里简单说下,1)关于混淆因子的概念,最简单的例子是:老年人因为退休了会比年轻人更有时间去保健,而老年人却比年轻人更容易的癌症,即(保健<--年龄-->癌症)。如果不控制年龄的分布,就会得到一个荒谬的结论,保健越多的人得癌症概率越大。这里的年龄就是混淆因子,需要被控制。2)关于中介效应,最简单得例子就是安慰剂效应,即(吃药-->安慰剂效应-->治愈率),如果不剔除安慰剂的中介效应,我们就得不到吃药的真实疗效(吃药-->治愈率)。
五. De-confound-TDE 算法
因为混淆因子和中介的存在,我们最终期望得到的X对Y的effect其实并不是原始效应(原始logits),而是下图这样的去混杂后的直接效应。其中De-confound training可以在训练中控制M对X的影响,而counterfactual inference的减法,通过类似设置安慰剂对照组的思想,去除了间接效应。
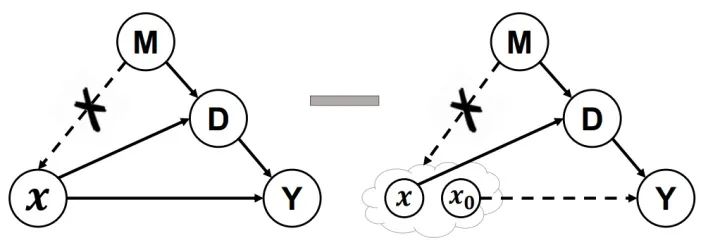
关于我们论文原文的4.1章De-confound training很多同学都觉得有点绕看不懂,其实这一章里公式的承接关系并不是严格的数学推导,而是我们基于因果分析的思想,用数学语言重新定义的工程实现(因为原始的因果分析领域并没有可以直接运用于深度学习的工具)。简单概括为两点:1)由于我们无法统计M的真实分布,因此可以通过multi-head多重采样来近似。2)当我们把原始的logits看成X对Y的因果效应后,我们参考了propensity score的思想,认为这样的effect需要对受控和非受控组(即大类和小类,也就是所有类)做归一化统一分布,最终我们将其实现为一种logits的normalization,其中有包含类别相关与类别不相关两个normalization项。
至于4.2的inference时TDE的减法其实还是比较直接的,我这就不细说了。同时考虑到在一些特殊任务中,有些大类是需要保持合理的倾向性的,比如物体检测和实例分割时,就需要合理地倾向于background类这个大类,否则就会检测到过多无意义地细节。因此我们在4.3中介绍了Background-Exempted Inference这种特殊处理。
六. How to Understanding TDE (怎么理解TDE)
我们提出的这个因果框架,其实也同时解释了2-stage的方法,并可以将其近似为NDE,关于怎么理解TDE和NDE的区别,可以参考我在补充材料里写的下面这个简单的一维数据二分类例子。
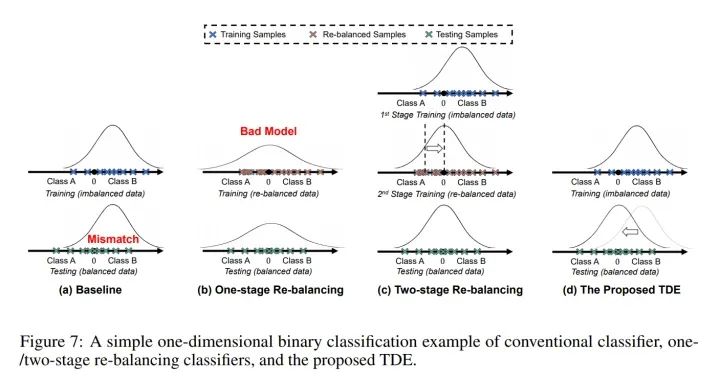
其中高斯曲线代表预测的分布,可以看到传统的直接训练和单步的re-balancing都有严重的问题,而2-stage的方法通过第二步再训练去矫正分类器的分类边界。我们提出的TDE方法则直接通过矫正特征本身的分布来更简单优雅的解决了分布不均衡的问题。
七. Experiments (实验结果)
我们在ImageNet-LT和Long-tailed CIFAR-10/-100上都超过了之前最优的长尾分布分类算法。
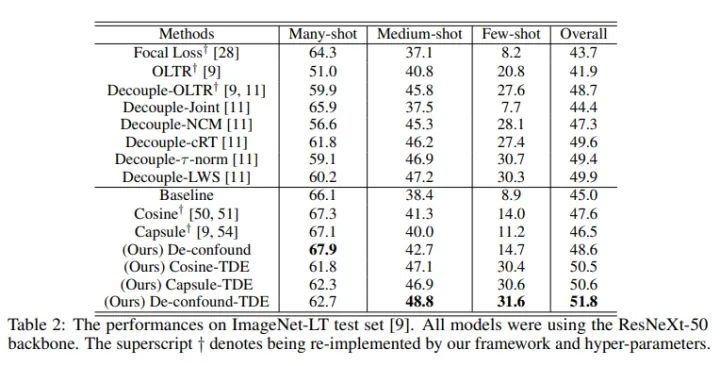
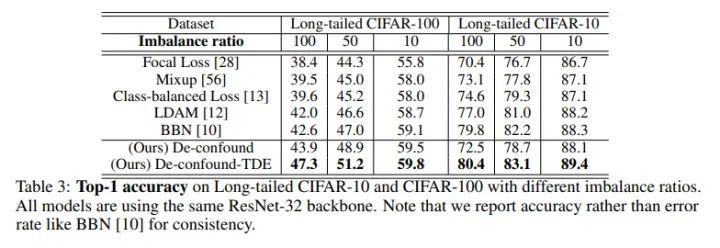
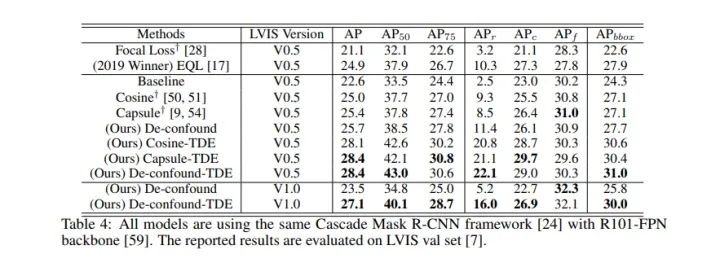
同时我们直接运用到LVIS长尾实例分割数据集下后,我们也超过了去年LVIS 2019比赛的冠军EQL(当然是在相同setting下,比赛正式结果还包含很多比赛专用的trick,比如额外数据,模型融合等)。关于LVIS的实验,比较逗的是,我们paper投出去后,LVIS官方更新了数据集,因此我们最终版也在最新的LVIS V1.0下跑了个结果,方便大家比较。
下面是最有意思的,当我们用Grad-CAM可视化了我们的feature map后我们发现,De-confound-TDE事实上让feature map更紧致了,即更关注少数区分度高的区域,而非整体结构。比如下图中“长牙野猪”的例子,传统的算法关注整个身体,而这部分其实和“猪”这个大类没什么区别,唯一的区别在于“长牙”,而我们的算法则明显的关注到了这些区分度高的紧致区域中了。
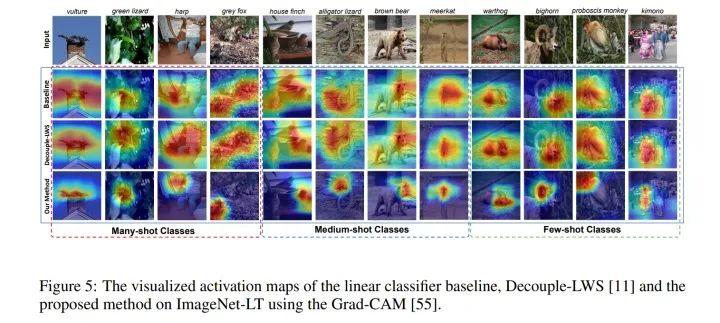
八. Conclusion (总结)
最后我想说一下,我其实还是很喜欢我们的这个工作的,因为我觉得我们提出了一个完全不同于以往算法的新思路,甚至解释了已有算法,同时这个方法又非常的简洁,优雅,通用。欢迎大家follow我们的这个工作~最后再附上我们的论文citation。
@inproceedings{tang2020longtailed, title={Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect}, author={Tang, Kaihua and Huang, Jianqiang and Zhang, Hanwang}, booktitle= {NeurIPS}, year={2020}}
推荐阅读
长尾(不均衡)分布下图像分类问题最新研究综述(2019-2020)
Long-Tailed Classification:长尾(不均衡)分布下的分类问题简介
CVPR2020 | 长尾数据特征学习新方法:为尾部样本构造特征云




