深度 | Yoshua Bengio AIWTB大会解读深度生成模型:让机器具备无监督学习能力
机器之心报道
演讲者:Yoshua Bengio
参与:吴攀、蒋思源
面向开发者的世界上最大的人工智能主题在线演讲与对话大会 AI WITH THE BEST(AIWTB)于 2017 年 4 月 29-30 日在 AIWTB 官网上通过在线直播的方式成功举办。作为第三届 AI WITH THE BEST 华语社区独家合作伙伴,机器之心在前两天接连整理报道了生成对抗网络(GAN)的提出者 Ian Goodfellow 和联想 AI 实验室负责人徐飞玉的精彩演讲。今天,我们将呈现的是著名深度学习学者 Yoshua Bengio 所带来的主题为《深度生成模型(Deep Generative Models)》的演讲。此外,Bengio 本次演讲的幻灯片内容也已经对外开放,感兴趣的读者可访问: https://www.slideshare.net/secret/9aV7jBf08vCMR
人工智能研究的最大难题之一是无监督学习(unsupervised learning)。当前在应用上成功的深度学习严重依赖于监督学习,即需要人类来分类数据和定义我们希望计算机了解的高层面的抽象。但是,人类即使没有老师告诉它有关世界的任何东西也能发现有关世界的很多方面,计算机要想获得这种自动学习理解世界的能力还需要进一步的发展。面向无监督学习的深度学习方法以学习表征(learning representation)问题为核心,不同的算法都会定义一个目标函数,该目标函数可以让该学习器获取到其数据表征的重要关键方面以及一个可以表征数据的新空间。深度生成模型可以通过生成全新的样本来演示其对于数据的理解,尽管这些生成的样本非常类似于那些训练样本。许多这样的模型都和之前的自编码器的思想有关,其有一个编码器函数将数据映射到表征,还有一个解码器函数(或生成器)将该抽象的表征映射到原始数据空间。本演讲将特别关注生成对抗网络(GAN),其质疑了当前已有的基于最大似然和概率函数估计的方法,并将我们带入了博弈论的领域,为我们提供了比较不同分布的全新方法以及非常出色的图像生成。
Bengio 演讲的视频:
以下为该演讲的内容详情整理:

演讲主题:深度生成模型。在这张幻灯片上,我们可以看到 Bengio 任职的多个机构,包括蒙特利尔学习算法研究所(MILA)、蒙特利尔大学、加拿大高等研究院(CIFAR)、IVADO。右下角可以看到他与另外两位学界领军人物 Ian Goodfellow 和 Aaron Courville 合著的新书《Deep Learning》,目前该书的中文印前版已经出炉并和英文版一样开放了下载,可参阅文章《资源 |《Deep Learning》中文印前版开放下载,让我们向译者致敬》。

智能需要知识,所以机器若想智能,就需要学习。传统人工智能的失败在于很多知识是直觉式的,难以直接编程给计算机使用。我们的解决方案是使用机器学习来从数据和经历中获取知识。

过去几年,机器学习的进展让人惊叹,但人工智能还远不及人类智能的水平:
目前取得了工业应用成功的人工智能大都基于监督学习;
学习到的都是肤浅标签的线索,难以很好地泛化到训练环境之外,训练好的网络也很容易被欺骗(比如通过调整狗照片的像素,使其被误认为是一只鸵鸟)——通过选取简单的规则就能欺骗现在的模型;
仍然不能在多种时间尺度上发现高层面的特征。
人类在无监督学习上的表现优于机器
人类非常擅长无监督学习,比如,两岁小儿也知道直观的物理作用;
婴儿可以得到近似的但足够可靠的物理模型,它们是怎么做到这一点的?注意他们不仅仅是观察世界,而且还会与世界进行交互。
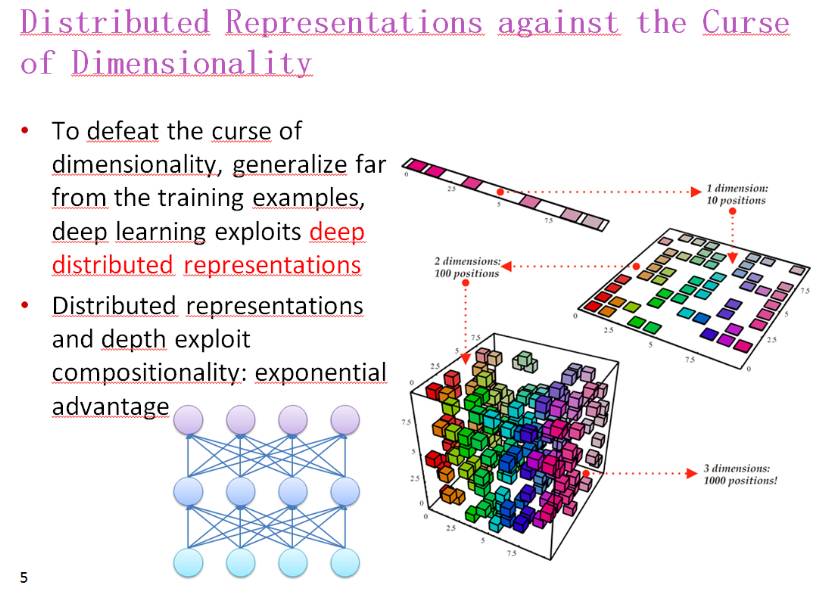
用分布式表征对抗维度灾难
为了解决维度灾难和很好地泛化到训练样本之外,深度学习利用了深度分布式表征
分布式表征和深度利用了组合性,具有极大的优势

隐藏单元能发现有意义的概念

分布式表征=高层抽象的集合
假设一个网络的隐藏单元需要发现以下特征:
人——带着眼镜
人——女性
人——小孩
那么它就需要获取非常大量的变量,其中高层面的特征对应于世界的不同方面。那么问题来了:我们如何将原始数据映射到这样一个空间,而无需预定义这些特征的含义?

不变性与 Disentangling
不变特征
哪些是不变的
备选:学会 disentangle 要素
好的 disentangling:避免维度的诅咒
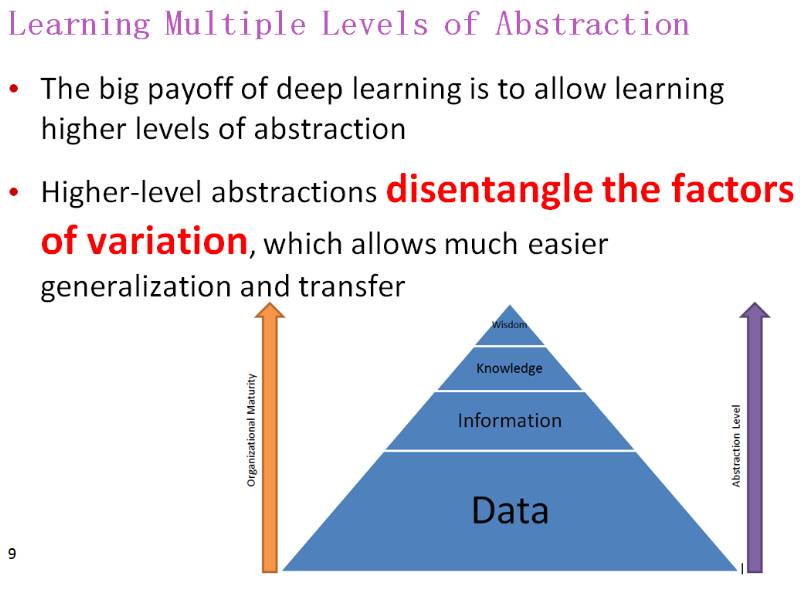
学习多层次的表征
深度学习的一大好处是能够学习更高层次的抽象化。
更高层次的抽象化能够 disentangle 变化系数,从而能进行更简单的泛化与迁移。
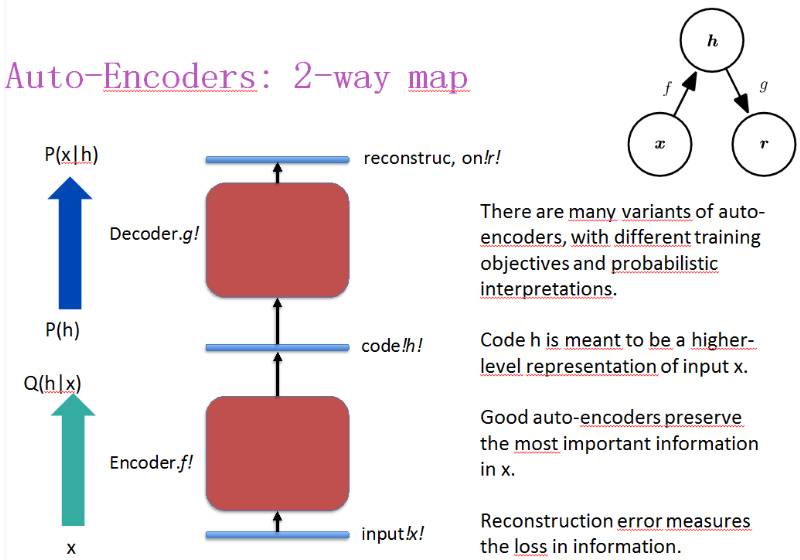
自编码器
自编码器有很多变体,有不同的训练目标和概率解释;
代码 h 应该是输入 x 的一个更高层面的表征;
好的自编码会保留 x 中最重要的信息;
用重构误差来衡量信息的损失。
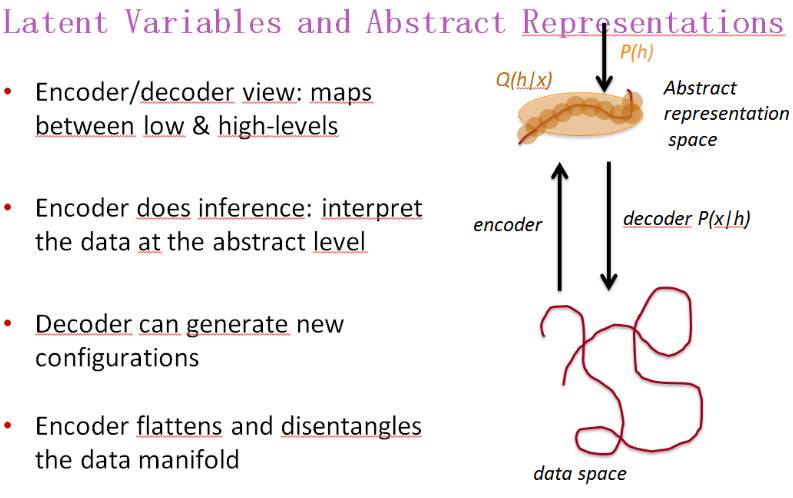
隐变量和抽象表征
编码器/解码器角度:低层和高层之间的映射;
编码器进行推理:在抽象层面解读数据;
解码器可以生成新的配置;
编码器可以展平和 disentangle 数据流形
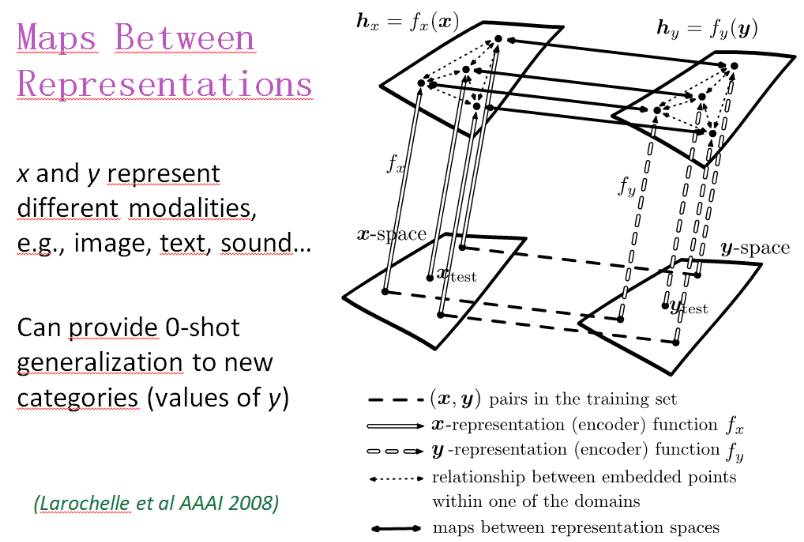
表征之间的映射
x 和 y 表示不同的模态,比如图像、文本、声音
可以提供到新类别(y 的值)的 0-shot 泛化

生成模型
要演示一个学习器是否已经理解了数据分布,可以让它根据该分布生成一个新样本。比如上面这个使用 BEGAN 在一个人脸图像数据集上生成的新图像。我们可以怎么做呢?如右上图的示意,可以为该模型在参数之外输入额外的随机数,使其生成新样本。
可以说生成模型就是由无穷样本得出概率密度模型,再借用其得出预测。生成方法由数据学习联合概率分布 P(X,Y),然后求出条件概率分布 P(Y|X)=P(X,Y)/P(X) 作为预测的模型。这样的方法之所以成为生成方法,是因为模型表示了给定输入 X 产生输出 Y 的生成关系。用于随机生成的观察值建模,特别是在给定某些隐藏参数情况下。

Helmholtz 机和变分自编码器
而对于变分自编码器(Variational Autoencoder/VAE),其使得我们可以在概率图形模型(probabilistic graphical model)的框架下将这个问题形式化,在此框架下我们可以最大化数据的对数似然值的下界。
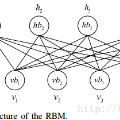
Yoshua Bengio 也表明现如今已经有许多类型的生成模型。他首先介绍了最早出现的玻尔兹曼机和受限玻尔兹曼机(Boltzmann machines & RBMs)。受限玻兹曼机不仅在降维、分类、协同过滤、特征学习和主题建模中得到应用,同时 Bengio 还表明在 2006 年深度学习最开始的进程中,RBM 也可以应用于第一阶段的深度神经网络。随后在 90 年代,出现了 Helmholtz 机和 sigmoid 信念网络。Bengio 还介绍了其他几种生成模型:降噪自编码器(Denoising auto-encoders)、变分自编码器(Variational auto-encoders)和自回归神经网络(如 RNN、 NADE、 pixelCNN 等)。当然最后少不了介绍一番生成对抗网络。
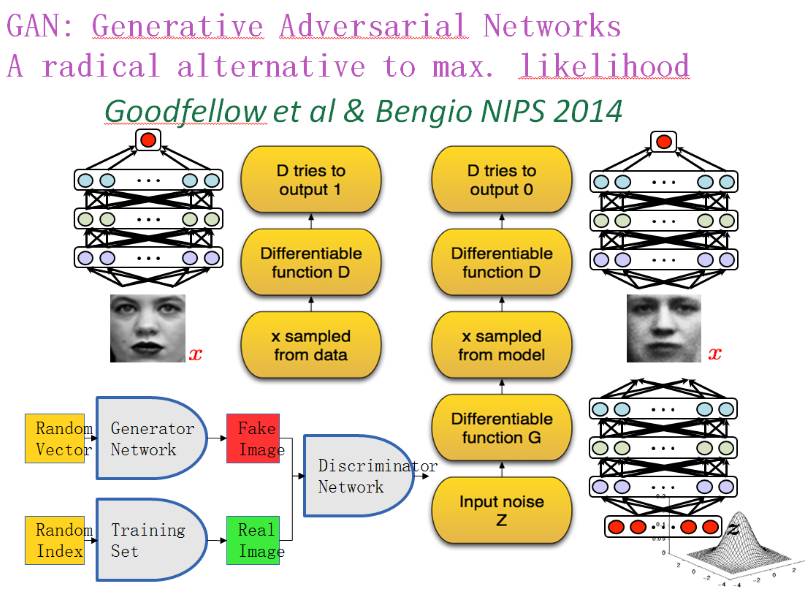
据 Bengio 介绍 GAN 是由两个彼此竞争的深度神经网络:生成器和判别器组成。为了理解生成对抗网络的基本原理,可以假定我们需要让 GAN 生成类似于训练集中的人脸图片。那么我们整个 GAN 的架构可能如下所示:
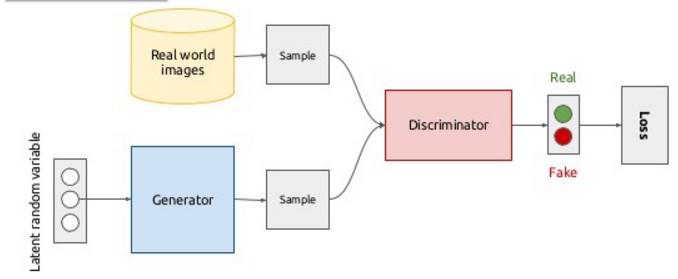
「生成器努力生成让辨别器认为是真的假图片。然后当一张图片输入时,辨别器会尽最大的努力试着辨别真的图片和生成的图片」
生成器和辨别器会共同进步直到辨别器无法辨别真实的和生成的图片。到了那时,生成式对抗网络只能以 0.5 的概率猜一下哪张是真实的哪张是生成的,因为生成器生成的人脸图片太逼真了。
GAN 论文是这样描述的:
生成模型可以被看作是一队伪造者,试图伪造货币,不被人发觉,然而辨别模型可被视作一队警察,努力监察假的货币。游戏当中的竞争使得这两队不断的改善方法,直到无法从真实的物品中辨别出伪造的。
因此在理想最优状态下,生成器将知道如何生成真实的人脸图片,辨别器也会知道人脸的组成部分。
随后 Bengio 还展示了生成对抗网络的早期数据样本:

GAN 本身也存在大量变体,可参阅机器之心文章《资源 | 生成对抗网络及其变体的论文汇总》。由于 CGAN 对于无监督学习和生成模型的巨大推动作用,Bengio 对卷积生成对抗网络也是做了一个概要介绍。

近年来,深度卷积神经网络(CNN)的监督学习在计算机视觉应用上发挥巨大的作用,然而 CNN 的无监督学习只受到较少的关注。因此,他又接着介绍了深度卷积生成对抗网络,该 DCGAN 具有一定的结构约束,并显示了其在无监督学习方向上强有力的潜力。他说通过在各种各样的图像数据集的训练,深度卷积对抗对(adversarial pair)从对象到场景在生成模型和判别模型上都能够学习到层级的表示。此外,在一些的新的任务上使用学习到的特征表明该网络在一般的图像表示上具有通用性。
GAN:在潜在空间中插值(Interpolating),如果模型是好的(展开了 manifold),在隐藏值间插值,就能产生貌似可信的图像。比如下图戴眼镜的男性图像减去男性图像加上女性图像就会得到戴眼镜的女性图像。

接下来 Bengio 又介绍了一篇提交到 CVPR 2017 的论文,该论文主要是介绍了一种通过在生成网络的潜在空间中进行梯度上升而合成高分辨率与逼真的图像。该论文及其地址如下:https://arxiv.org/abs/1612.00005

最后,Bengio 介绍了在训练生成对抗网络时所面对的一些挑战与困难:
训练时可能会产生模型不稳定或发散的情况
GAN 模型对超参数和训练的细节十分敏感
模式崩溃:几乎相似的图像生成太多次
模式缺失:有些数据子类型缺失
在监督学习中,如果没有在训练期提供潜在类别,那么其就很难处理这些类别
很难监控进程
对于模型质量没有一个可接受的定量度量
但 GAN 真的十分优秀
现在也已经提出了很多变体来解决这些问题,但还有更多的研究者正在努力解决它们
如想要了解更多,可查看 Goodfellow 在 NIPS 所做的教程,参阅机器之心文章《独家 | GAN 之父 NIPS 2016 演讲现场直击:全方位解读生成对抗网络的原理及未来(附 PPT)》

点击阅读原文,报名参与机器之心 GMIS 2017 ↓↓↓