清华大学周伯文教授:从原则到实践解读多模态人工智能进展与可信赖AI
以人为中心的 AI 才是真正有活力的 AI。


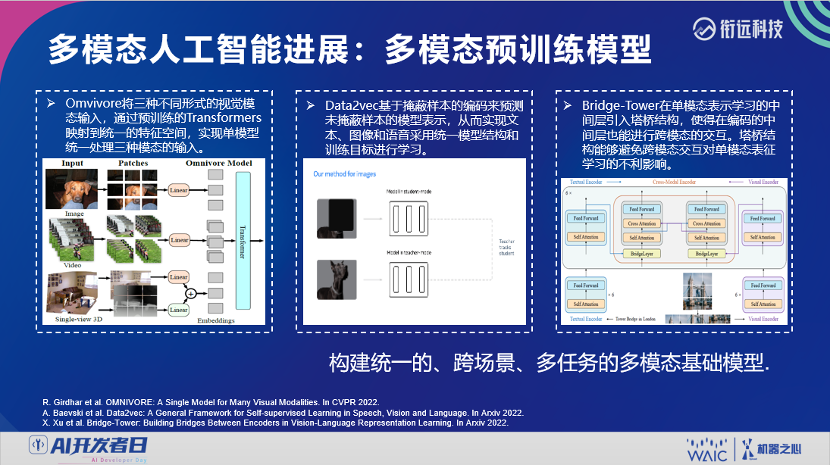
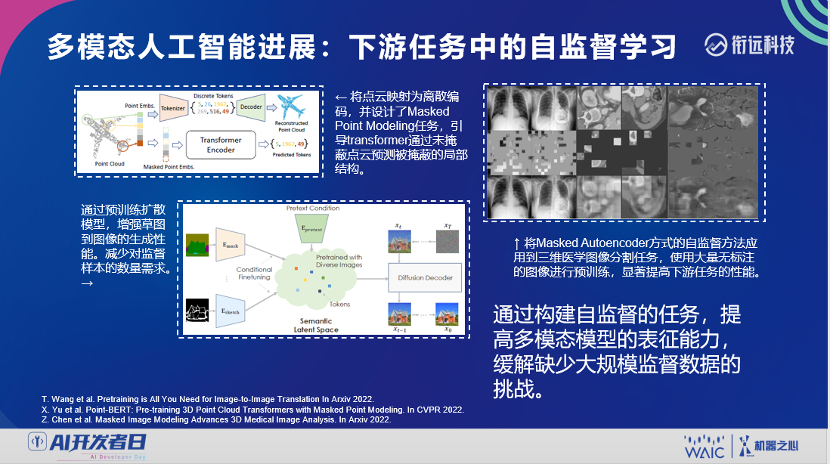
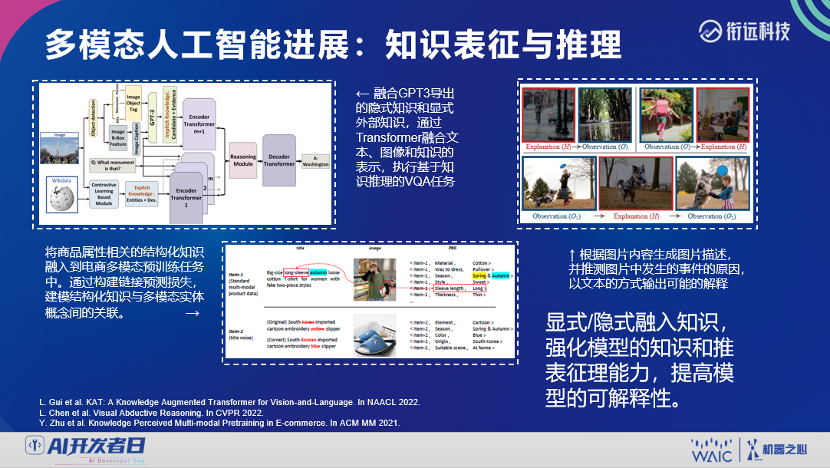
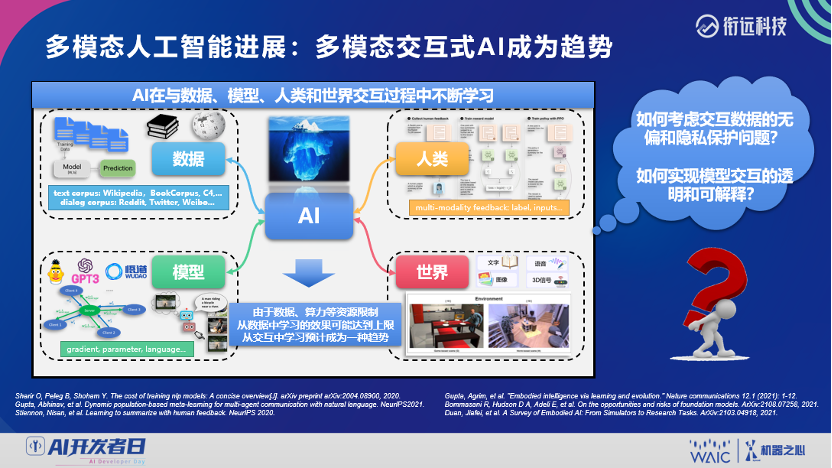


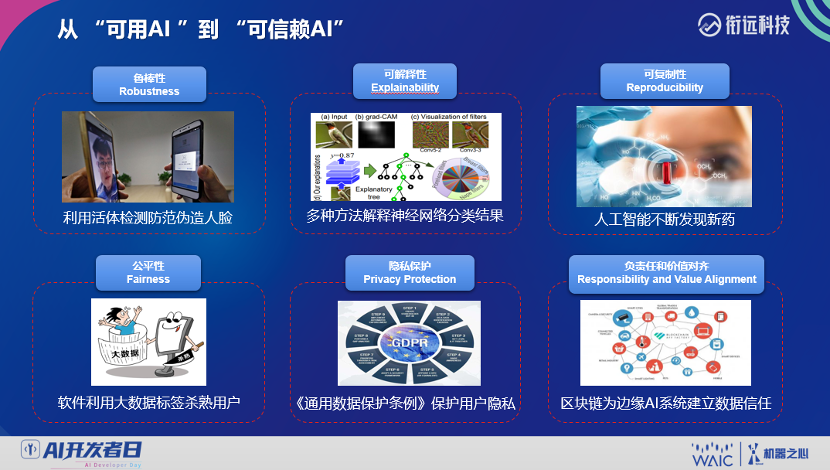
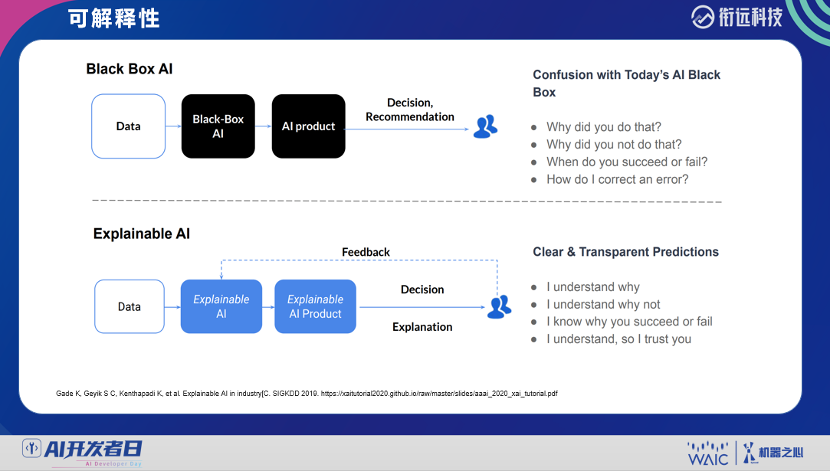
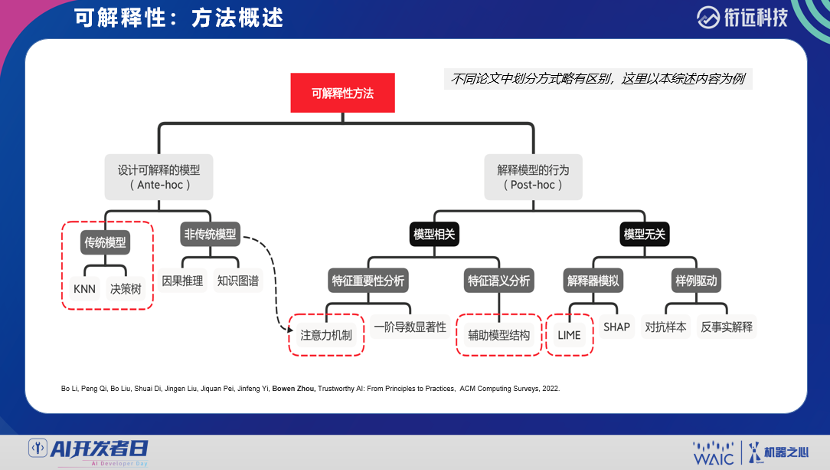
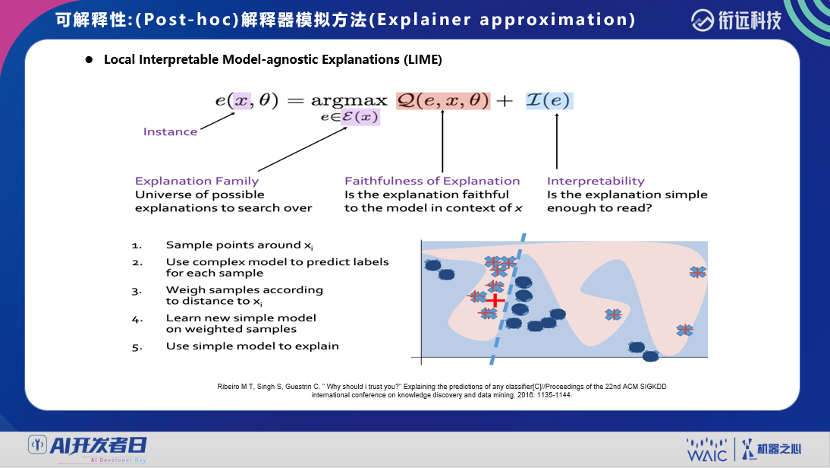
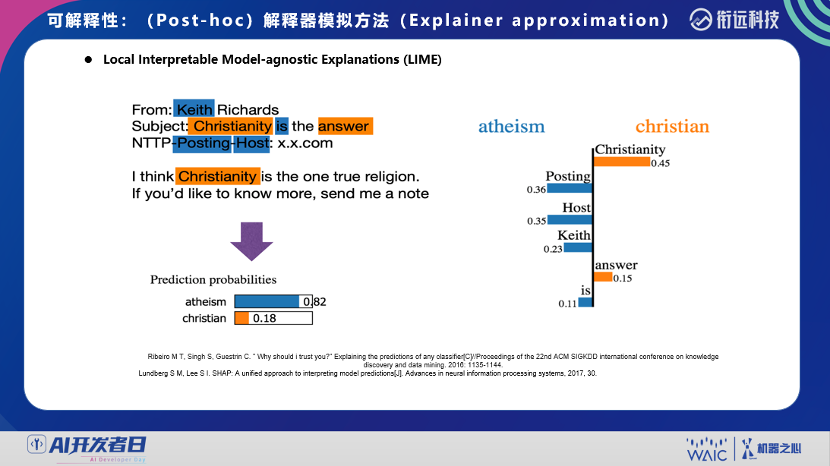

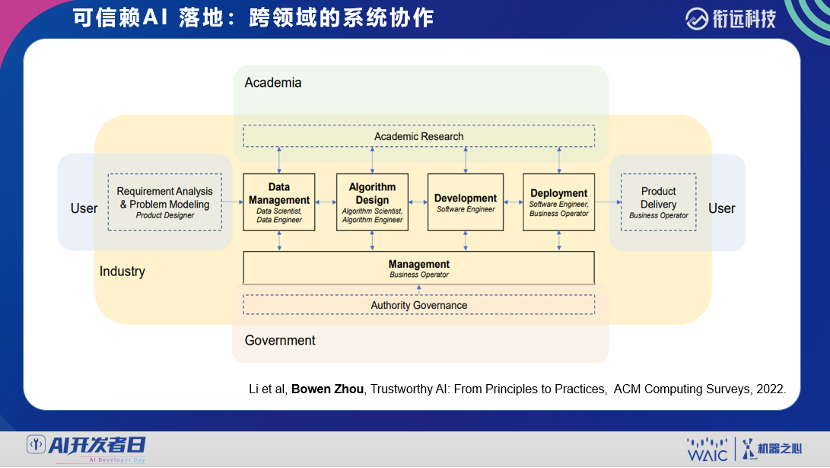
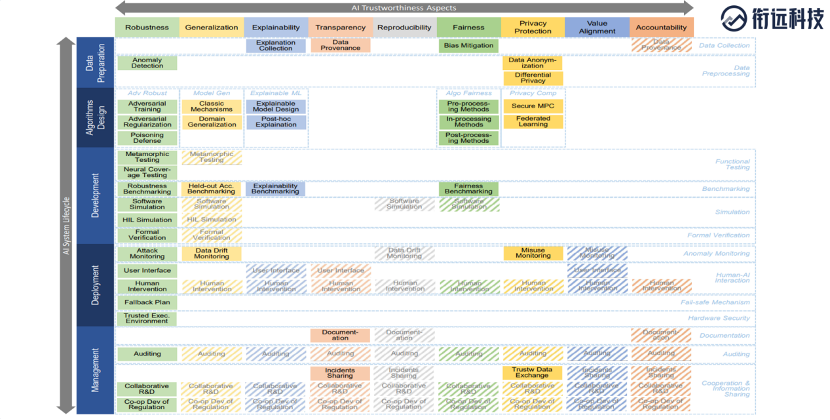
登录查看更多
相关内容
Arxiv
16+阅读 · 2021年5月26日




相关VIP内容
相关资讯
相关论文
Arxiv
16+阅读 · 2021年5月26日