

随着视觉、听觉、语言等单模态人工智能技术的突破,让计算机拥有更接近人类理解多模态信息的能力受 到研究者们的广泛关注。另一方面,随着图文社交、短视频、视频会议、直播和虚拟数字人等应用的涌现,对多模态 信息处理技术提出了更高要求,同时也给多模态研究提供了海量的数据和丰富的应用场景。该文首先介绍了近期 自然语言处理领域关注度较高的多模态应用,并从单模态的特征表示、多模态的特征融合阶段、融合模型的网络结 构、未对齐模态和模态缺失下的多模态融合等角度综述了主流的多模态融合方法,同时也综合分析了视觉-语言跨 模态预训练模型的最新进展。
http://jcip.cipsc.org.cn/CN/abstract/abstract3314.shtmt
1. 引言
人工智能研究经过70多年的探索,在视觉、语 音与声学、语言理解与生成等单模态① 人工智能领 域已取得了巨大的突破。特别是视觉领域的目标检 测与人脸识别技术、语音领域的语音识别与语音合 成技术、自然语言处理领域的机器翻译与人机对话 技术在限定场景下已经实现了规模化的应用。然 而,人类对周围环境的感知、对信息的获取和对知识 的学习与表 达 都 是 多 模 态 (Multimodal)的。近 些 年,如何让计算机拥有更接近人类的理解和处理多 模态信息的能力,进而实现高鲁棒性的推理决策成 为热点问题,受到人工智能研究者的广泛关注。另 一方面,随着图文社交(Facebook、Twitter、微信、微 博等)、短视频(YouTube、抖音、快手)、音频(Club-音、京东、淘宝等)和数字人(2D、3D、卡通、写实、超 写实等)等应用的涌现,对多模态信息处理技术在用 户理解、内容理解和场景理解上提出了更高的要求, 同时也给多模态技术提供了海量的数据和丰富的应 用场景。 多模态信息处理技术打破计算机视觉、语音与 声学、自然语言处理等学科间的壁垒,是典型的多学 科交叉技术。多模态技术从20世纪70年代开始发 展,Morency等人[1]将多模态技术的发展划分为四 个阶段,即 1970-1980 年 的 行 为 时 代 (Behavioral Era)、1980-2000 年 的 计 算 时 代 (Computational Era)、2000-2010 年的交互时代(InteractionEra) 和2010年起的深度学习时代(DeepLearningEra)。 多模态核心技术又分为:多模态表示(Representation),多模态融合(Fusion)、多模态转换(Translation)、多 模 态 对 齐 (Alignment)和 模 态 协 同 学 习 (Co-learning)类。
近些年,研究者从不同的视角对多模态信息处 理技术做了很好的总结回顾。Zhang等人[2]围绕图 像描述、视觉-语言生成、视觉问答和视觉推理四个 应用,从计算机视觉的角度总结了多模态表示学习 和多模态融合的最新进展。Summaira等人[3]的综 述覆盖了更多的多模态应用,并根据应用组织了每 一个多模态应用的技术进展和局限性。
本文从自然语言处理的视角出发,介绍多模态 信息处理技术的最新进展,组织结构如下:第1节 介绍 NLP领域关注度较高的多模态应用和相关的 数据集。多模态融合是多模态信息处理的核心问 题。第2节从单模态信息的表示方法、多模态信息 的融合阶段、融合模型的网络结构、未对齐模态和模 态缺失情况下的多模态融合等角度介绍主流的多模 态融合方法。第3节介绍多模态预训练技术,并从 模型的网络结构、模型的输入、预训练目标、预训练 语料和下游任务等维度对比最新提出的多模态预训 练模型。第4节介绍多模态技术在工业界的应用。 最后一节是总结和对未来工作的展望。
2. 多模态应用
我们分析了最近两年在自然语言处理领域国际 学术会议上(ACL、EMNLP、NAACL)发表的多模 态信息处理的论文,并从应用的角度对论文进行了 分类。关注度较高的多模态应用如图1所示。本节将对这些应用展开介绍。除此之外,多模态应用还 包括视听语音识别(Audio-VisualSpeechRecognition)、多 模 态 语 言 分 析 (Multimodal Language Analysis)和视觉辅助的句法分析[4]等。文献[4]还 获得 NAACL2021的最佳长文奖。
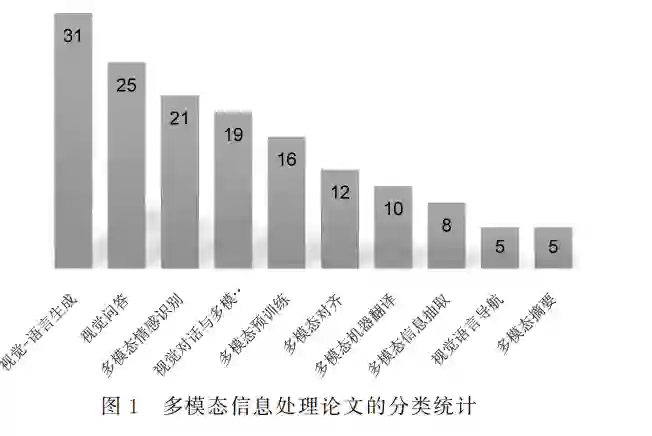
1.1 多模态情感识别
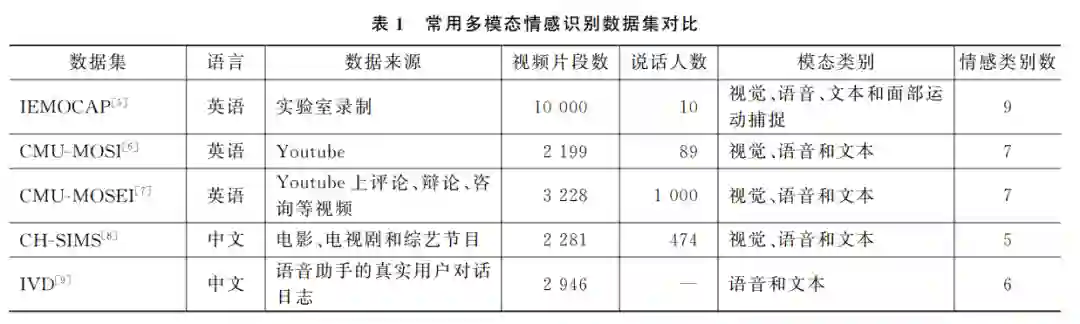
情感是人类区别于机器的一个重要维度,而人 的情感往往又是通过语音、语言、手势、动作表情等 多个模态表达的。在交互场景下,多模态情感识别 研究如何从人的表情和动作手势、语音音调、语言等 多模态信息中理解用户细颗粒度的情感表达,进而 指导人机交互策略。其主要研究内容有:①基于 多模态信息互补性和异步性的动态融合;②高噪 声环境下对于模态模糊或模态缺失问题的鲁棒性 融合;③客服和营销等自然交互情境下的情感识 别等。 多模态情感识别的常用数据集有IEMOCAP [5]、 CMU-MOSI [6]、CMU-MOSEI [7]、CH-SIMS [8] 和 IVD [9]等。 数 据 集 的 多 维 度 比 较 如 表 1 所 示。 IEMOCAP数据集收录了10位演员的表演数据,包 含视频、语音、面部运动捕捉和文本模态,并标注了 高兴、悲 伤、恐 惧 和 惊 讶 等 共 9 类 情 感。CMUMOSI数据集收录了89位讲述者的2199条视频 片段,每段视频标注了7类情感。CMU-MOSEI数 据集是 CMU-MOSI的扩展版,收录了 1000 多名 YouTube主播的 3228 条视频,包括 23453 个句 子,每个句子标注了7分类的情感浓度(高度负面、 负面、弱负面、中性、弱正面、正面、高度正面)和6分 类的情 绪 (高 兴、悲 伤、生 气、恐 惧、厌 恶、惊 讶)。 CH-SIMS数据集是一个中文多模态情感分析数据 集,该数据集为2281个视频片段标注了细颗粒度的情感标签。IVD 是从中文语音助手的真实用户 对话日志中抽取的语音情感数据集,包括500000 条无标注的语音数据和2946条带6分类情感标注 的语音数据。
随着图文和短视频等新兴社交媒体的迅速发 展,人们在社交平台上的表达方式也变得更加丰富。 社交场景下的多模态情感识别主要研究基于图文表 达的情感倾向[10]和方面级的细颗粒度情感[11]等。
1.2 视觉-语言生成
视觉(图像或视频)到语言的生成和语言到视觉 (图像或视频)的生成打破了计算机视觉和自然语言 处理两个领域的边界,成为多模态交叉学科中最热 门的 研 究 课 题。2021 年 初,OpenAI推 出 的 基 于 GPT-3的语言到视觉的生成模型 DALL-E① 可以根 据自然语言的描述生成逼真的图像,产生了较大的反 响。本节主要介绍视觉到语言生成的相关应用。
1.2.1 图像描述
图像描述(ImageCaptioning)是对给定的一幅 自然图像生成一句自然语言描述的任务。2015年 以前,图像描述的主流方法是基于模板的方法。其 基本思想是检测图像中的物体、动作,并将这些词作 为主语、动词和宾语等填写到预定义的模板中。从 2015年开始,基于视觉编码器(CNN 等)和语言解 码器(RNN/LSTM 等)的序列到序列(Sequence-toSequence,Seq2Seq)框架广泛应用于这一任务。通 过从 视 觉 图 像 中 解 析 出 属 性 (Attribute)、关 系 (Relation)和结构(Hierarchy)等高层语义信息,并 将这些语义信息融入视觉编码和语言解码中,提高 了图像描述的生成效果。 图像描述任务的常用数据集有 MSCOCO [12]、 Conceptual Captions [13]、 Flickr30K [14]、 Visual Genome [15]和SBUCaptions [16]。MSCOCO 数据集 是微软发布的可用于目标检测(ObjectDetection)、 人体姿势识别(DensePose)、关键点检测(Keypoint Detection)、实例分割(StuffSegmentation)、全景分 割 (PanopticSegmentation)、图 片 标 注 (Category Labelling)和图 像 描 述 (ImageCaptioning)的 数 据集。该数据集有91类物体(人、猫和卡车等),共计 32.8 万 幅 图 像,每 幅 图 像 包 含 5 个 英 文 描 述。 ConceptualCaptions数据集收录了330万幅“图像, 描述”对,是目前最大的多模态数据集,其中的图像 有自然图像、产品图像、专业照片、卡通和绘图等类 型,描 述 取 自 HTML 中 的 Alt-text属 性 字 段 值。 Flickr30K 收录了来自 Flickr的共计31783幅日常 活动、事件和场景的图像,每幅图像通过众包方式标 注了5个图像描述。VisualGenome是基于10.8万 幅图像的 大 规 模 多 模 态 数 据 集,该 数 据 集 标 注 了 380万个对象、280万个属性、230万个关系、170万个 “图像、问题、答案”三元组和540万个区域描述。图 像中的对象、属性、关系、区域描述和视觉问答中的名 词与短语还被归一化到相应的 WordNet同义词集
1.2.2 视频描述
视频描述(VideoCaptioning)是对给定的一段 视频(通常是几十秒的短视频)生成一句准确、细致 描述的任务。视频除了图像信息外,还包括时序和 声音等信息。视频描述可提取的特征更多,技术挑 战也更大。 视频描述任务的常用数据集有 MSR-VTT [17]、 ActivityNet-Captions [18]、YouCook2 [19] 和 ACTIONS [20] 等。MSR-VTT数据集由1万个网络视频剪辑、20万 “视频,描述”对组成。MSR-VTT数据集涵盖了音乐、 游戏、体育、教育等20多个类别的视觉内容,每个视频 剪辑时长10~20秒,人工为每个视频剪辑标注了20个 描述句子。YouCook2数据集是一个烹饪教学视频数 据集,包括89个食谱的2000个未经剪辑的教学视频(最长10分钟,平均5分钟)。ACTIONS是首个无需 人工标注、从数以亿计的网页内容中自动提炼“视频, 描述”对的视频描述数据集,总共包含了163183个 GIF视频。
1.2.3 视觉叙事
视觉叙事(VisualStorytelling)要求模 型 对 于 给定的图像序列,在深度理解图像序列的基础上生 成连贯的叙事故事。相比于图像描述和视频描述, 视觉叙事更具挑战性。在视觉理解上,视觉叙事的 输入是有时序关联的图像序列,需要模型具备根据 历史视觉事件推测当前的视觉事件的能力。在语言 生成上,对比图像描述和视频描述中的客观文字描 述,视觉叙事的输出由更多评价性、会话性和抽象性 语言组成。SIND [21]是一个视觉叙事数据集,该数 据集收集了81743幅图片,以及排列成符合文字描 述和故事情节的20211个序列。
1.3 视觉问答和多模态对话
1.3.1 视觉问答
视觉问答(VisualQuestionAnswering,VQA)[22-27] 是2015年新提出的任务,简单来说就是图像问答。 给定一幅图像和一个关于该图像的开放式自然语言问题,要求模型准确回答该问题。视觉问答是一个典 型的多模态问题,需要模型具备物体定位、属性检测、 事件分类、场景理解和推理及数学计算等能力。根据 图 片 类 型 的 不 同,VQA 又 分 为 自 然 图 像 理 解 VQA [22-23]、合成图像推理 VQA [24]和自然图像推理 VQA [25]。表2列举了这3种 VQA的示例。 VQA常用数据集有 VQAv1/v2 [22-23]、CLEVR [24] 和 GQA [25]。VQAv1/v2是自然图像理解 VQA 数 据集,VQAv2 解 决 了 VQAv1 中 明 显 的 语 言 先 验 (LanguagePriors)问题。CLEVR [24]是合成图像推 理问答数据集。CLEVER 中的图像由简单的几何 形状的物体组成,旨在测试模型对组合式语言的理 解能力和对视觉场景的推理能力。CLEVR 数据集 中的图像是程序合成的,其场景的复杂度与自然场 景相去甚远。对此,Hudson等人[25]发布了基于自 然图像的组合式问题视觉问答数据集 GQA,该数据 集包括关于11.3万幅图像的超过2000万的问题。 每幅图像都标注了一个场景图(SceneGraph),表示 图像中的对象、属性和关系。每个问题都对应一个 功能性程序(FunctionalProgram),列出了获得 答 案所需执行的一系列推理步骤。每个答案都有与之 对应的验证信息,指向图片中的相关区域。

1.3.2 视觉对话
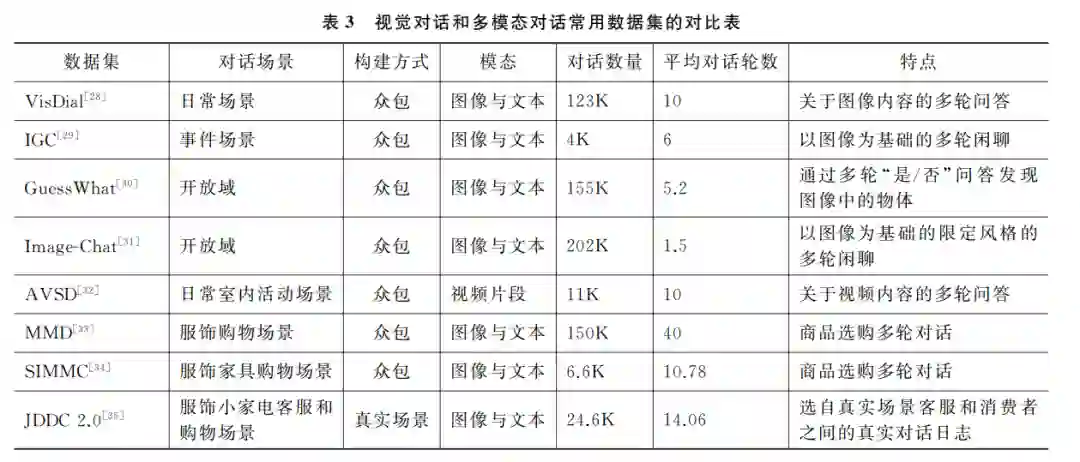
视觉对话(VisualDialog)[28-32]是给定一幅图像 (或视频等视觉内容)和一个上下文相关的问题,要 求模型根据图片(或视频)内容回答该问题。与视觉 问答相比,视觉对话还要解决对话中特有的挑战,如 共指(Co-references)和省略(Ellipsis)等。视觉对话 也被认为是视觉图灵测试。视觉对话常用数据集有 VisDial [28]、IGC [29]、GuessWhat [30]、Image-Chat [31] 和 AVSD [32]。VisDial中的问题和答案都是形式自由的。GuessWhat是通过一系列“是/否”问题发现 图像中的物体。IGC是一个闲聊型的视觉对话数据 集,但闲聊的话题受限于给定的图像。Image-Chat 也是一个闲聊型视觉对话数据集。与IGC 不同的 是,Image-Chat数据集还限定了对话参与者 A 和 B 的风格特征。AVSD 定义了一个视听场景的多轮 对话任务,要求机器在理解问题、对话历史和视频中 的场景等语义信息的基础上回答用户问题。 视觉对话中的用户问题只与单个图像(视频)相关,且用户问题和模型回答都是文字的。

1.3.3 多模态对话
多模态对话(MultimodalDialog)关注更接近人 类自然对话的多模态人机对话技术的研究。它与上 一节介绍的视觉对话的主要差异有:①多模态对话 给定的输入图像可能是多幅的;② 随着对话的推 进,图像是不断更新的;③用户问题和模型的回答 可以是文本的、图像的或者图文结合的;④模型可 能需要查询外部领域知识库才能回答用户的问题 (如购物者希望看到更多与特定商品相似的商品,或 者要求提供满足某些特征的商品,或者查询特定商 品的属性等);⑤模型可能需要通过反问等对话策 略澄清用户需求。零售和旅游等限定领域的多模态 对话最近受到了越来越多的关注。常用的面向购物场景的多模态对话数据集有 MMD [33]、SIMMC [34]和JDDC [35]。MMD 是在服饰 专家的指导下通过模拟扮演(Wizard-of-Oz,WoZ)的 方式收集的时尚购物场景的数据集。SIMMC2.0是 时尚和家 具 购 物 场 景 的 数 据 集。其 中,时 尚 和 家 具杂乱的购物场景是通过逼真的 VR 场景生成器 (VRSceneGenerator)生成的。与 MMD 和 SIMMC 不同,JDDC2.0是从电商平台客服和消费者之间的 真实对话数据中采样的(图2)。JDDC2.0包括多模 态对话24.6万,其中,图片50.7万张,平均对话 轮 数14轮。此 外,JDDC2.0还 提 供 了30205个商品的759种商品属性关系,共计21.9万的<商品ID、 属性、属性值>三元组。 视觉对话和多模态对话常用数据集的详细对比 如表3所示。
1.4 多模态摘要
多模态摘要是基于对多模态输入(文本、语音、图 像和视频等)的理解,归纳并生成单模态或者多模态 的概括性总结(摘要)的任务。根据具体任务类型,多 模态摘要又可细分为视频会议摘要[36]、教学视频摘 要[37]、多模态新闻摘要[38-42]和多模态商品摘要[43]。 视频会议摘要方面,Li等人[36]提出了一个从音 视频会议 输 入 中 提 取 会 议 文 本 摘 要 的 方 法,并 在 AMI数据 集 上 验 证 了 方 法 的 有 效 性。AMI数 据集[44]包含 137 场视频会议。每场会 议 持 续 30 分 钟,包含4名参与者和约300字的文本摘要。 教学视频摘要方面,Palaskar等人[37]提出一种 融合视觉信息和文本信息(用户生成的和语音识别 系统输出的)的生成式文本摘要方法,同时在开放域 教学视频数据集 How2 [45]上验证了方法的有效性。 多模态新闻摘要方面,Li等人[38]提出一种从异 步的多模态(文本、图像、音频和视频)输入中抽取文 本摘要的方法,并发布了中文和英文数据集 MMS。 Li等人[39]提出一种为“文本,图像”对生成多模态摘 要的模型,同时发布了英文数据集 MMSS。Zhu等 人[41]提出了一种从异步的多模态(文本和多张图 像)输入中生成多模态(一段短文和一张图片)摘要 的方法,同时发布了英文数据集 MSMO。 多模态商品摘要方面,Li等人[43]提出了一种从 异构的多模态输入(文本、图像、商品属性表)中生成 商品摘要的方法,同时发布了数据集 CEPSUM①。 CEPSUM 数据集由140万“商品文本介绍,商品图 片,文本摘要”三元组组成,涉及3个商品大类。
1.5 多模态对齐
多模态对齐研究多个模态不同颗粒度元素间的 对齐关系,具体又分为显式对齐和隐式对齐。视觉语言跨模态的显式对齐任务研究图像和句子[46-47]、 图像和词[48]、图像中的目标和句子中的短语[49-50]间 的对齐关系。多模态对齐方法可直接应用于多模态 检索等应用,也可作为图像描述、VQA、多模态预训 练的训练语料,尤其是在缺乏大规模多模态人工标 注语料的场景。 图像和句子(或文档内其他文本单元)间的显式 对齐通常是不存在的。对此,Hessel等人[46]提出了 一种将同一网页内的图像和句子对齐的无监督方 法。该方法在7个难度不同的数据集上获得了不错 的性能。Suhr等 人[47]定 义 了 一 个 视 觉 推 理 任 务 NLVR2,对于给定的两幅图像和一段自然语言的描 述,要求模型判断它们是否存在语义上的对齐关系。 文本预训练语言模型已经取得了巨大的成功, 但该方法仅使用文本上下文信息作为监督信号,导 致词的 上 下 文 表 示 学 习 严 重 依 赖 词 的 共 现 关 系 (Co-occurrence),缺乏外部物 理 世 界 的 背 景 知 识。 为了给预训练语言模型提供视觉监督信号,Tan等 人[48]提出了 Vokenization技术(图3),其通过给文 本中的每一个词打上一幅图像的标签,实现在大规 模文本语料上自动构建多模态对齐语料库。在大规模图像-词汇对齐的多模态语料库上训练的预训练 语言模型可增强其对自然语言的理解能力。实验证 明,该 模 型 在 多 个 纯 文 本 的 任 务 上 (如 GLUE、 SQuAD和SWAG 等)均获得了显著的性能提高。

图像中的目标和文本中的短语对齐也被称为图 像短语定位(PhraseGrounding),可用于提高图像 描述、VQA、视 觉 导 航 等 视 觉-语 言 下 游 任 务 的 性 能。Plummer等人[49]发布了一个大规模的短语定 位数 据 集 Flickr30kEntities,如 图 4 所 示。Wang 等人[50]提出了一种基于细粒度视觉和文本表示的 多模态对齐框架,在 Flickr30kEntities数据集上显 著提高了短语定位的性能。

视频定位(VideoGrounding)[51]是多模态对齐中另 一项 重 要 且 具 有 挑 战 性 的 任 务。给 定 一 个 查 询 (Query),它要求模型从视频中定位出与查询语言对应 的一个目标视频片段。该技术可应用于视频理解、视 频检索和人机交互等场景。常用数据集有 CharadesSTA [52]、ActivityNet-Captions [53]和 TACoS [54]。CharadesSTA 数据集是基于 Charades数据集[55]构建的,包括 6672个视频和16128个“查询,视频片段”对。ActivityNet-Captions数据集包含两万个视频和10万个“查 询,视频片段”对,其覆盖的视频类型更多样。TACoS 数据集包含127个烹饪视频和18818个“查询,视频 片段”。
1.6 多模态翻译
多模态翻译是将多模态输入(文本、图像或视频 等)中的源语言文本转换为目标语言文本的过程。 多模态翻译的目标是在视觉等多模态信息的辅助 下,消除语言的歧义,提高传统文本机器翻译系统的 性能。 Elliott等人[56]于2015年首次提出多模态翻译 任务。随后,在2016年举办的第一届机器翻译会议 上成功组织了第一届多模态机器翻译比赛,并于接 下来的两年连续举办了两届比赛,引发了研究者们 对多模态机器翻译的关注热潮。目前的工作主要集 中在 Multi30k数据集[57]上。该数据集是英语图像 描述数据集 Flickr30k [14]的多语言扩展,每幅图像 配有一个英语描述和一个德语描述,任务定义为给 定图像和英语描述,生成德语描述。 模型方面,Huang等人[58]首先从图像中提取视 觉全局表示(参见2.1.1节的介绍)和视觉目标表示 (参见2.1.3节的介绍),提取的视觉表示被视为源 语言中特殊的单词与文本拼接,再融入编码器-解码 器神经网络翻译模型中的编码器中。在 Calixto等 人[59]提出的模型中,视觉特征被视为源语言中特殊 的单 词,或 者 融 入 编 码 器 中,或 者 融 入 解 码 器 中。 Calixto等人的模型显著提 高 了 模 型 的 翻 译 效 果。 文献[58-59]中的模型依赖大量的多模态翻译对齐 语料 (源 语 言、图 像、目 标 语 言)。对 此,Elliott等 人[60]将多模态机器翻译分解为两个子任务:文本 翻译 和 基 于 视 觉 的 文 本 表 示 (Visually Grounded Representations)。该模型不依赖昂贵的(源语言、 图像、目标语言)对齐语料。模型可以分别在文本翻 译语料(源语言,目标语言)和图像描述(图像,源语 言)语料上训练。受文献[60]的启发,Zhou等人[61]提 出 了 一 种 机 器 翻 译 任 务 和 视 觉-文 本 共 享 空 间 (Vision-TextSharedSpace)表示学习任务相结合 的多 任 务 多 模 态 机 器 翻 译 框 架 (VAG-NMT)。 VAG-NMT 首先把文献[60]中的基于视觉的文本 表示(即从文本表示重建图像)修改为视觉-文本共 享空间表示学习。其次,VAG-NMT 还提出了一种 视觉文本注意机制,可以捕获与图像语义强相关的 源语言中单词。多模态机器翻译中的视觉信息只在 非常特殊的情况下(如文本上下文不足以消除歧义 词的歧义)对翻译模型有帮助。对此,Ive等人[62]提 出了一 种 翻 译-优 化 (Translate-and-refine)的 两 段 式翻译方法。该方法先翻译源语言中的文本,再使 用视觉目标表示对第一阶段的翻译文本进行调整。 大多数的多模态机器翻译模型没有考虑不同模态的 相对重要性,但同等对待文本和视觉信息可能会引 入一 些 不 必 要 的 噪 声。Yao 等 人[63]基 于 Transformer,提出了一种多模态自注意机制,探索了如何 消除视觉特征中的噪音信号。一方面,单层多模态 注意力模型难以有效提取视觉上下文信息,另一方 面,多层多模态注意力模型容易导致过拟合,尤其是 对训练数据少的多模态翻译。对此,Lin等人[64]提 出一种基于动态上下文指导的胶囊网络(Dynamic Context-guidedCapsuleNetwork,DCCN)提取和利 用两种不同颗粒度(视觉全局表示和视觉区域表示) 的视觉信息。也有研究者对多模态翻译的可解释性 进行了探索。Wu等人[65]的研究表明,视觉特征对 多模态翻译的帮助来自于正则化,视觉特征的合理 选取对模型性能至关重要。
1.7 多模态信息抽取
命名实体识别(NER)是指识别自由文本中的 具体特定意义的实体(如人名、地名和组织机构名 等)。命名实体识别虽然取得了较大的成功,但对于 社交媒体中大量的用户生成内容(User-Generated Content,UGC),仅根据文本模态的信息来定位和 分类其中的实体仍然存在一些挑战。多模态命名实 体识别(MNER)通过引入视觉、语音等其他模态作 为文本模态的补充,识别社交媒体中高噪声短文本 中的实体,最近几年受到了比较多的关注。 模型方面,Moon等人[66]首次提出了融合图像 和文本模态信息的通用多模态注意力模型。文献 [66]还发布了 SnapCaptions数据集,该数据集由1 万张“图像,短文本标题”对构成,并标注了短文本标 题中 的 四 类 命 名 实 体 (实 体 类 型:PER、LOC、ORG、MISC)。一方面,文献[66]中的方法提取的 是图像的视觉全局表示,这可能把图像中的噪声信 息也引入到模型中。另一方面,视觉和文本模态的 特征融合较简单。对此,Zhang等人[67]提出了一种 自适应 的 协 同 注 意 力 网 络 (AdaptiveCo-attention Network,ACN)。ACN 首先提取图像的视觉区域 表示(参见2.1.2节的介绍),再通过文本到视觉和 视觉到文本的协同注意力剔除图像中的噪声信息, 以提高 MNER的性能。文献[67]在内部数据集上 验证了该方法的有效性。基于类似的出发点,Lu等 人[68]提出了一种注意力机制与门控机制相结合的 模型提取视觉图像中与文本最相关的区域的特征。 该模型可忽略不相关的视觉信息。文献[68]基于注 意力机制获取了单词感知(word-aware)的视觉表 示,却忽略了图像感知(image-aware)的单词表示。 对此,Yu等人[69]首次将 Transformer应用于多模 态 NER任务中,并提出了实体片段检测辅助任务, 进一步消除视觉偏差,提升了模型效果。 Sui等人[70]提出了融合语音和文本信息的多模 态 NER,并在自建的中文数据集 CNERTA 上验证 了方法的有效性。 多模态信息抽取领域中另一个受到较多关注的 研究方向是多模态商品属性抽取。多模态商品属性 抽取是指从给定商品文本描述和商品图片中抽取商 品的属性信息,例如商品的“颜色”“材料”等属性值。 为了推动多模态商品属性抽取的研究,IV 等人[71] 发布了 首 个 大 规 模 多 模 态 属 性 提 取 英 文 数 据 集 MAE。MAE包含400万图片和760万“属性-属性 值”对。文献[71]提出的多模态属性抽取模型需要 对每一个属性识别其对应的属性值,且无法滤除视 觉噪声。为了提高模型的效率,Zhu等人[72]将属性 预测和属性值抽取建模为一个层叠化的多任务学习 过程,实现了多个属性及其对应属性值的一次性识 别,且视觉全局表示和视觉区域表示通过门控机制 和文本信息融合,可有效过滤视觉噪声。Zhu等人 还发布了一个包含9万“属性-属性值”对的多模态 商品属性抽取中文数据集 MEPAVE。
2 多模态融合
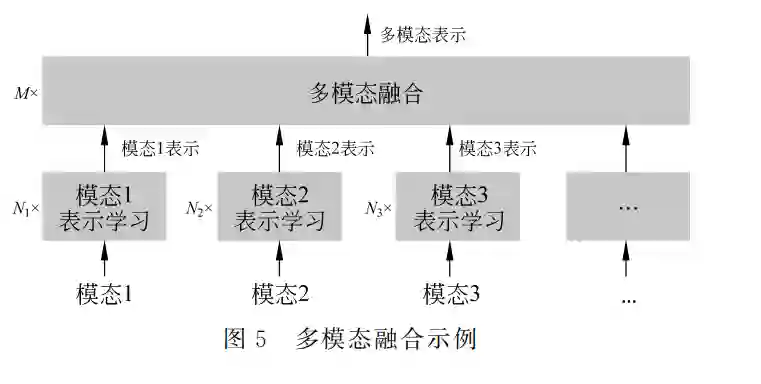
多模态融合将多个单模态表征整合成为一个多 模态信息表征,它是多模态信息处理的核心问题。多 模态融合的示例如图5所示,其中,Ni{i=1,…K} 表示单模态表示学习模型的模型深度,M 表示K 个多模态表示的融合模型深度。多模态融合的研究方 向有:基于多模态互补性的全模态融合问题、模态 模糊或者模态缺失下的鲁棒性融合问题、非对齐的 多模态融合问题等。目前,大部分工作是关于模态 对齐且无模态缺失情况下的多模态融合算法研究, 这也是多模态融合中最基础的挑战。本节根据单模 态的特征表示、多模态融合的阶段、多模态融合的模 型结构等对多模态融合方法进行分类介绍。
2.1 根据单模态表示进行分类
单模态的特征表示是多模态融合的基石。这一 类方法重点研究如何在多模态融合之前提取更好的 单模态特征表示。以视觉-语言-音频多模态应用为 例,如何从视觉内容中解析出高层语义信息以增强 视觉特征表达是这一类方法的主要研究内容。例 如,从视觉内容中识别目标(Object)、属性(Attribute)、动作(Action)、关系(Relation)、场景图(Scene Graph)[73-75]和树形语义结构(Hierarchy)[76]等,进 而 实 现 对 视 觉 内 容 的 全 局 (Global)、区 域 (Regional)、目标(Object)和关系(Relation)等颗粒 度的视觉语义建模。语言表示通常使用词的独热编 码表示、词 的 上 下 文 表 示 (ContextualRepresentation)[77-78]、句子表示[79-80]、句法依存关系(Syntactic Dependency)表示[81]、场景图表示[82]等。音频表示 可使用 基 于 COVAREP [83]提 取 底 层 声 学 特 征 表 示[85]、基于预训练模型 wav2vec [84]提取低维特征向 量表示[85]等。本节侧重介绍多模态融合中的视觉 特征表示方法。
2.2 根据融合阶段进行分类
根据多模态融合的阶段,多模态融合方法可分 为早期融合[79-82,90]、中期融合[91]和晚期融合[92]。早 期融合的特点是单模态表示学习简单,而多模态融 合部分的模型深度大,融合策略复杂。例如,词的独 热编码 表 示 和 视 觉 区 域 表 示 直 接 参 与 多 模 态 融 合[93]。晚期融合的特点是单模态表示学习模型复 杂,多模态融合一般采用拼接、按位乘/求平均等简 单策略[92]。由于晚期融合抑制了模态之间的交互, 目前大部分基于深度学习的模型均使用早期或者中 期融合。在第3节介绍的多模态预训练模型中,基 于单流架构(Single-Stream)的预训练模型把融合操 作 放 在 早 期 阶 段,如 VideoBERT [94]、UnicoderVL [95]、Oscar [96]、VL-BERT [97]和 M3P [98]等。基于 双流架构(Two-Stream)的预训练模型则把融合操 作 放 置 在 深 层 模 型 的 中 期 阶 段 的 多 个 层 中,如 ERNIE-ViL [82]、LXMERT [91]、ActBERT [99]和 ViLBERT [100]等。
2.3 根据融合方式进行分类
多模态融合模型的设计是多模态融合的关键研 究点。我们将多模态融合模型分为简单融合、门控 融合(Gating)、注意力融合(Attention)、Transformer 融合、图模型融合(GraphFusion)和 双 线 性 注 意 力 (BilinearAttention)融合共六类方法。常见简单融合 方法包括编码器、解码器的初始化(参见1.6 节和 2.1.1节)、拼接、按位乘/求和/求平均等操作。本节 主要介绍其余的五类较复杂的融合方法。
3 多模态预训练
通过预训练语言模型从海量无标注数据中学习 通用知识,再在下游任务上用少量的标注数据进行 微调,已经成为自然语言处理领域成熟的新范式。 从2019年开始,预训练语言模型(BERT [101]、GPT3 [102]、BART [117]和 T5 [118]等)相继被扩展到多语言 和多模态等场景。 相对于文本预训练语言模型,多模态预训练模 型可以更好地对细颗粒度的多模态语义单元(词或 者目标)间的相关性进行建模。例如,基于语言上下 文,被掩码的词“ontopof”可以被预测为符合语法 规则的词“under”或“into”等。但这与关联的图片 场景“猫在车顶”不符。通过多模态预训练,模型从 图像中捕获“汽车”“猫”之间的空间关系,从而可以准 确地预测出掩码词是“ontopof”[82]。大部分的多模 态预训练模型是在视觉-语言对齐数据上进行的。例 如,使用图像和文本对齐数据集(MSCOCO [12]、ConceptualCaptions [13]、VisualGenome [15] 和 SBU Captions [16]等)训练的跨模态预训练模型 LXMERT [91]、 Oscar [96]、VL-BERT [97]和ViLBERT [100],M3P [98]。使 用视频和文本对齐数据集训练的 VideoBERT [94]和 ActBERT [99]等[119-120]。Liu等人[85]最近还发布了视 觉、文本、语音三模态预训练模型 OPT。 本文表5中从网络结构、模型输入、预训练目标、 预训练语料和下游任务等维度对比了最新的视觉-语 言跨模态预训练模型 ERNIE-VIL [82]、LXMERT [91]、 LightningDOT [92]、E2E-VLP [93]、Unicoder-VL [95]、 Oscar [96]、VL-BERT [97]、M3P [98]、ViLBERT [100]、 TDEN [121]、UNIMO [122]。
表 5 中 的 表 示 “图像,语言”对,I表示一幅图像,w=w1,…,wT 表 示长度为T 的文本表示。g=g1,…,gG 是图像区 域表示,q=q1,…,qK 和v=v1,…,vK 分别表示图 像中的目标的文本表示和目标的视觉表示。g 和 v的提 取 可 参 考 2.1 节 的 介 绍。 此 外,[SEP]、 [IMG]、[CLS]等 特 殊 标 记 用 来 分 割 不 同 模 态。 MLM(MaskedLanguage Model)是根据未掩码的 词 和 图 像 区 域 预 测 掩 码 单 词。 MOC(Masked ObjectClassification)根据未掩码的图像区域和文 本预 测 掩 码 区 域 的 目 标 类 别。 MOR (Masked ObjectRegression)根据未掩码的图像区域和文本 预 测 掩 码 区 域 的 特 征 表 示。 MSG (Masked SentenceGeneration)根据输入图像逐字生成句子。 VQA 根据输入的图像和该图像相关问题预测该问 题的答案。CMCL 是跨模态对比学习任务。VLM 是预测图像-文本对是否语义一致。

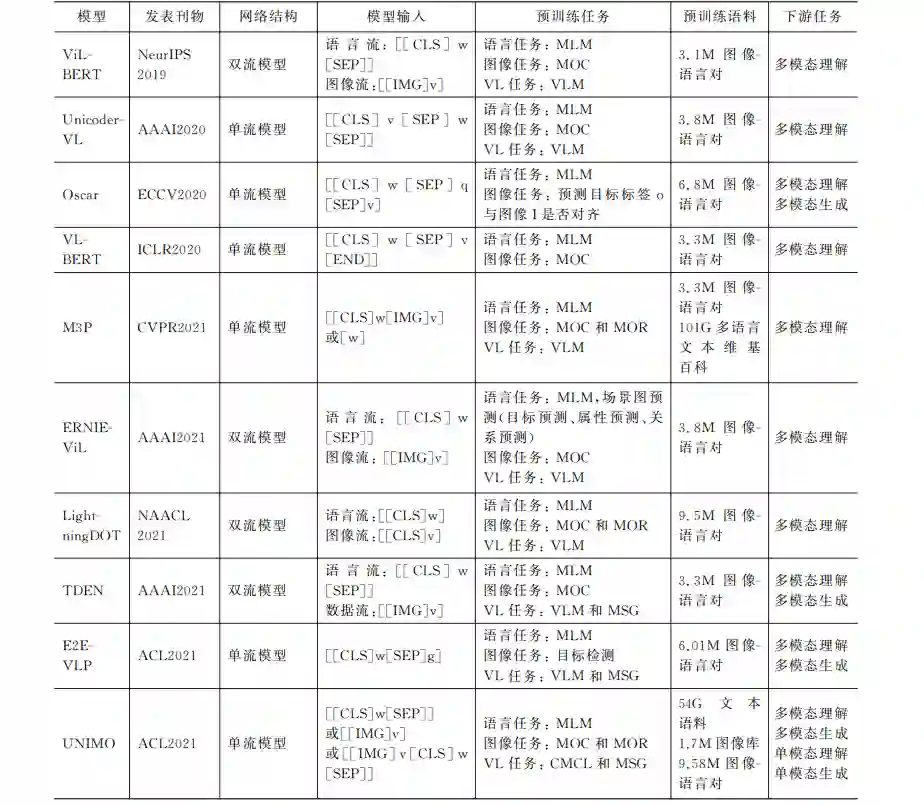
从表5中的11个图像-语言跨模态预训练模型 的对比,我们发现的跨模态预训练模型的特点如下: ①单流模型和双流模型均被广泛采用。虽然双流模 型可以适应每种模态的不同处理需求,但目前尚无 完整的实验证明双流模型优于单流模型。②多模态 预训练模型从应用于多模态理解任务或多模态生成 任务发展到可兼顾多模态理解和生成两大任务的统 一模型。③相对动辄上百 G 甚至 T 级别的单模态 数据,多模态对齐数据的规模有限。最新的多模态 预训练模型可以利用互联网上的大规模非对齐的文 本数据、图像数据、以及文本-图像对齐数据学习更 通用的文本和视觉 表 示,以 提 高 模 型 在 视 觉 和 语 言的理解和生成能力,如 M3P和 UNIMO。④多 模态预训 练 模 型 从 仅 应 用 于 多 模 态 下 游 任 务 发 展到可同 时 应 用 于 单 模 态 下 游 任 务 和 多 模 态 下 游任务。 上述的多模态预训练模型需要在大量图像文本 的对齐语料上进行训练。然而,此类数据的收集成 本昂贵,很难扩大规模。受无监督机器翻译[123-124] 的启发,Li等人[125]提出了一种不依赖图像-文本对 齐语料的预训练 U-VisualBERT,该预训练模型的 输入是一批文本数据,或一批图像数据,并通过图像 中物体标签作为锚点(AnchorPoints)对齐两种模态。U-VisualBERT 在四个多模态任务上取得与使 用多模态对齐数据训练的预训练模型接近的性能。 该方向可能会是接下来的一个研究热点。
4 结束语
多模态信息处理是一个典型的多学科交叉领 域。最近几年,多模态信息处理受到自然语言处理、 计算机视觉和语音与声学领域研究者的广泛关注。 本文从自然语言处理的视角出发,首先介绍了目前 热点的多模态应用,接着介绍了多模态的三个重要 研究方向及其主流方法:即视觉的单模态表示(视 觉全局表示、视觉区域表示、视觉目标表示和视觉场 景图表示)、多模态融合(简单融合、门控融合、注意 力融合、Transformer融合、图模型融合和双线性注 意力融合)和通用的多模态预训练。最后,本文对多 模态技术在产业界的应用进行了简要的描述。
多模态信息处理还有很多亟待进一步研究的课题。我们认为,以下五个方向将是多模态信息处理 技术领域未来重要的研究内容:①非对齐语料上的 多模态信息处理。目前,大多数下游的多模态任务 和多模态预训练模态都依赖多模态对齐语料。相对 动辄上百 G 甚至 T 级别的单模态语料,多模态对齐 语料的规模还是很有限。探索如何在海量非对齐多 模态语料上训练多模态模型具有非常实用的价值, 也是多模态领域需要重点关注的课题之一。此方向 已经有了初步的探索。例如,利用多模态对齐技术 将 海 量 的 单 模 态 语 料 与 其 他 模 态 进 行 自 动 对 齐[48,122]。②面向单模态和多模态的理解和生成任 务的统一模型。当前的主流模型或面向单模态理解 (或生成)或面向多模态理解(或生成)的模型,构建 一个既适用于单模态理解与生成任务,又适用于多 模态理解与生成任务的统一模型是未来非常重要的 研究方向。多模态模型在文本任务上的性能未来可 能会超过单模态模型[48,122]。③高噪声环境下的多 模态鲁棒性融合。真实场景常常有较强的背景噪 声,部分模态的数据通常是模糊或缺失的。因此,探 索如何在高噪声情况下获得信息缺失的有效表征, 提高模型预测鲁棒性和准确性是多模态领域重要的 研究课题之一。文献[116]提出一种基于缺失模态的想 象 网 络 (Missing ModalityImagination Network,MMIN)对该方向进行了初步的探索。④ 多 模态与知识的融合。2.1节介绍的从视觉内容中提 取视觉粗粒度特征表示和基于视觉场景图的细颗粒 度特征表示,其目的都是增强视觉特征表示。我们 认为,如何提取更精细粒度的视觉特征表示是多模 态领域重要的基础研究方向之一。引入知识图谱作 为图像实体信息的补充,从而进行知识增强的视觉 特征表示是该方向一种探索思路[126-127]。⑤复杂交 互情境下的多模态应用。第1节介绍了多模态信息 处理技术的多个应用场景。我们认为,数字人、元宇 宙(Metaverse)是多模态信息处理技术最佳的应用 场景之一,探索复杂交互情境下的多模态信息处理 是多模态领域未来最重要的研究方向之一。
