在深度网络和人工智能复兴十年后,本文提出了一个理论框架,并提出了两个基本原则——简约性和自洽性,视它们为人工智能的基石。
耗时三个多月,夜以继日撰写,马毅教授的综述文章《 On the Principles of Parsimony and Self-Consistency for the Emergence of Intelligence 》终于来了!
马毅教授表示:这篇文章把过去五年自己的工作以及智能七十多年的发展有机结合起来。并表示自己一生从未在一篇文章上花这么多精力和时间。希望这篇文章能对现在的研究方向和品味产生正面的影响。
![]()
这篇论文由马毅教授联合神经生物学家曹颖、计算机大牛沈向洋共同撰写。
![]()
论文地址:https://arxiv.org/pdf/2207.04630.pdf
本文旨在提供整体立场和观点,而不是从技术上证明每一项主张的合理性。研究者希望这篇论文能给大家理出智能的起源以及计算原理的基本轮廓和框架,让大家认识到这种理论联系实践的可能性。他们也希望通过这篇文章,对目前的研究方向和风气在一定程度上起到正本清源的作用 。
![]()
马毅教授表示:「在这篇论文中,我们不再区分人工智能或自然智能。如果任何事物 / 任何人是智能的,其应该遵循相同的原则和机制。」
本文主要分 4 个章节,第 1 节主要介绍研究背景和动机;第 2 节使用可视化数据建模作为具体示例来提出两个原则——简约和自洽,并说明如何将它们实例化为可计算的目标、架构和系统;第 3 节研究者推测这两个原则会使得通用学习引擎用于更广泛的感知和决策任务;最后,第 4 节研究者讨论了所提出原则的多层含义及其与神经科学、数学和高级智能的联系。
本节中,研究者以视觉表象(visual imagery)数据建模为例,从简约性和自洽性的第一原则推导出了压缩闭环转录框架。
过去十年,人工智能的进步在很大程度上依赖于使用蛮力工程方法训练黑盒模型,例如深度神经网络可以说是使用蛮力方法训练而成。虽然功能模块化可能出现在训练中,但学习到的特征表示在很大程度上仍然是隐藏的、潜在的、并且是难以解释的。我们都了解,端到端黑盒模型这种昂贵的蛮力训练不仅导致模型规模不断增长和高昂的数据 / 计算成本,在实践中也伴随着许多问题:由于神经崩溃导致最终学习表征缺乏丰富度;由于模式崩溃导致训练缺乏稳定性;缺乏对灾难性遗忘的适应性和敏感性;缺乏对变形或对抗性攻击的鲁棒性。
我们假设在当前深度网络和人工智能实践中出现这些问题的根本原因之一是对智能系统的功能和组织原则缺乏系统和综合的理解。
例如,在实践中,训练用于分类的判别模型和用于采样的生成模型在很大程度上是分开的。此类模型通常是开环系统,需要通过监督或自监督进行端到端的训练。在控制论中,研究者长期遵循的一个原则是,这种开环系统不能自动纠正预测中的错误,并且不能适应环境的变化。研究者将闭环反馈引入受控系统,以便系统能够学会纠正其错误。正如本文所讨论的,在这里可以得出类似的经验:一旦将判别模型和生成模型组合在一起形成一个完整的闭环系统,学习就可以变得自主(无需外部监督),并且更高效、稳定且适应性强。
要理解智能系统中可能需要的功能组件,例如判别式或生成式,研究者需要从原则性且统一的角度来理解智能。
本文认为,简约和自洽两个基本原则支配着任何智能系统的功能和设计,无论是人工的还是自然的。这两个原则分别旨在回答以下两个关于学习的基本问题:
1. 学习什么:从数据中学习的目标是什么,如何衡量?
2. 如何学习:我们如何通过高效和有效的计算来实现这样的目标?
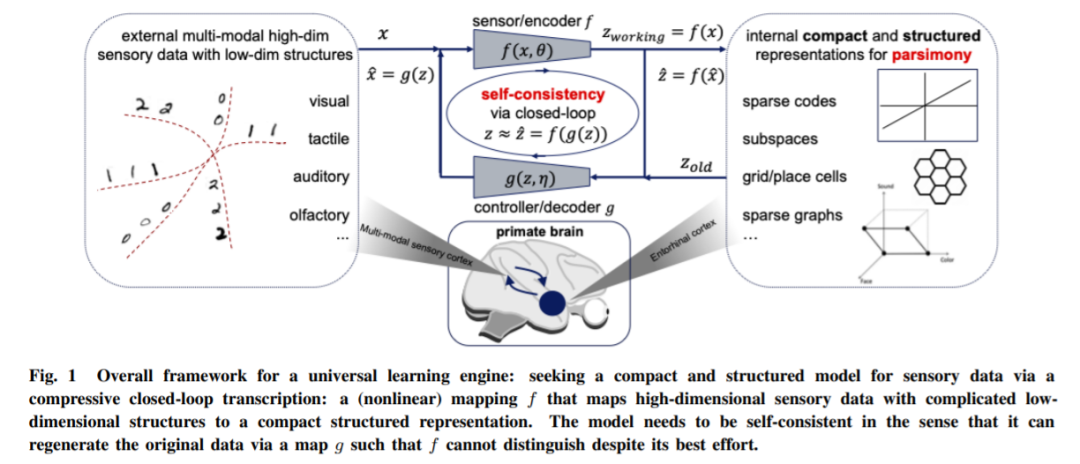
第一个问题的答案属于信息 / 编码理论领域,该理论研究如何准确量化和测量数据的信息,然后寻求信息的最紧凑表示。一旦学习的目标明确并确定,第二个问题的答案自然会落入控制 / 博弈论领域,该领域提供了一个普遍有效的计算框架,即闭环反馈系统,用于一致地实现可测量目标,如下图 1 所示。
![]()
智能系统需要这一原则的一个根本原因是:没有简约原则,智能将是不可能的!现在我们面临的一个问题是智能系统如何体现简约原则。从理论上讲,智能系统可以使用世界上任何理想的结构化模型系列,只要它们简单且足够表达以模拟现实世界感官数据中的有用结构。系统应该能够准确有效地评估学习模型的好坏,并且使用的度量应该是基本的、通用的、易于计算和优化的。该研究使用了可视化数据建模的激励性和直观示例。
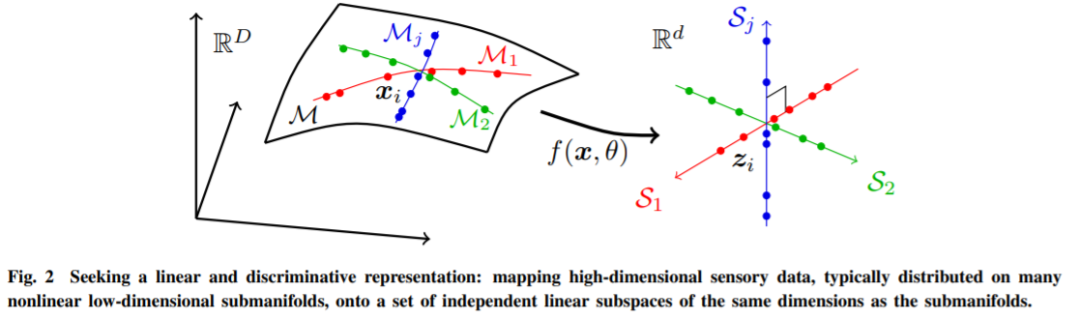
如下图所示,x 表示输入的传感数据,比如一个图像,用 z 来表示它的内部表示。传感数据样本 x ∈ R^D 通常是相当高维的(数百万像素),但具有极低维的内在结构。在不损失一般性的情况下,我们可以假设它分布在一些低维子流形上,如图 2 所示。
![]()
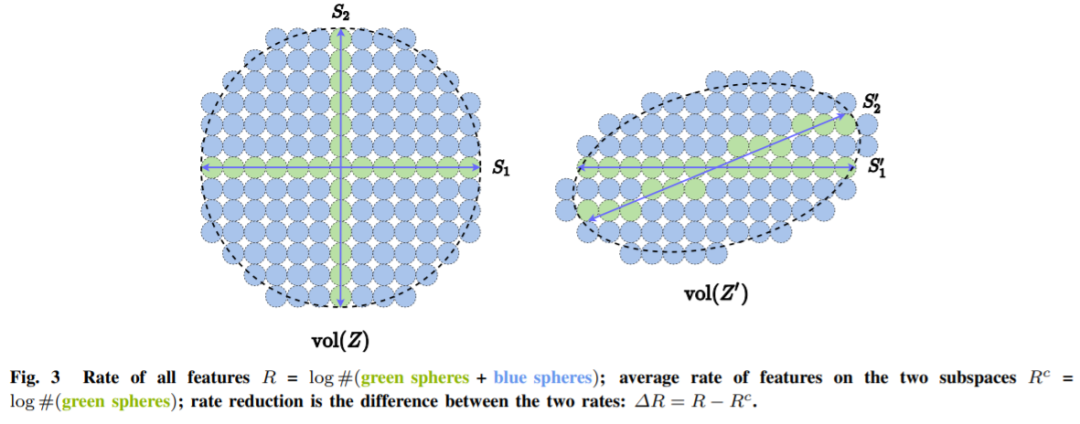
对于 LDR 模型系列,有一种自然的内在简约度量。直观地说,给定一个 LDR,我们可以计算所有子空间上的所有特征所跨越的总体积以及每个类别的特征所跨越的体积之和。然后这两个体积之间的比率给出了一个自然的衡量标准,来表明 LDR 模型性能:比率越大越好。图 3 展示了一个示例,其中特征分布在两个子空间 S1 和 S2 上。
![]()
左侧和右侧的模型具有相同的内在复杂性。显然,左侧的配置是首选,因为不同类别的特征是独立且正交的——它们的外部表征将是最稀疏的。
单凭简约原则并不能保证模型能够从感知到的外部世界数据中获取所有重要信息。例如,通过最小化交叉熵,将每个类映射到一维的 one-hot 向量,可以被视为一种简约的形式。这可能会学习到一个好的分类器,但学习到的特征会崩溃为单例(singleton),被称为神经崩溃。这样学习到的特征将不再包含足够的信息来重新生成原始数据。如果特征空间维数过低,则学习的模型对数据拟合不足;如果过高,模型可能会过度拟合。
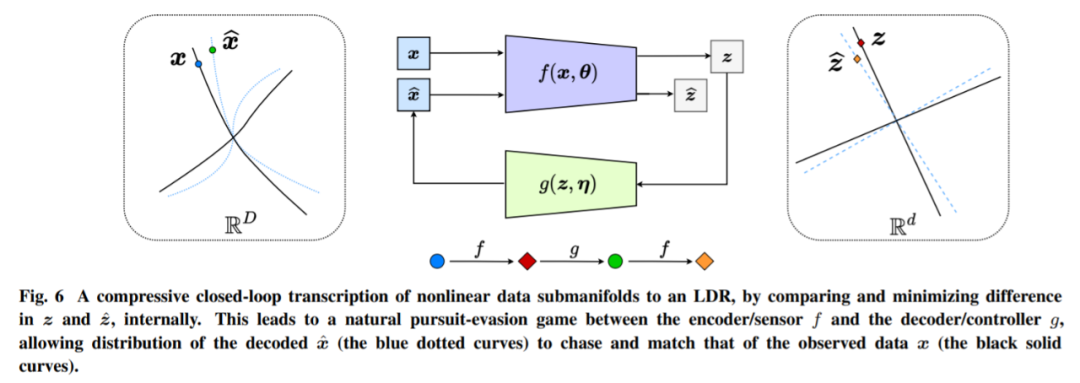
更一般地说,该研究认为感知不同于特定任务的执行,感知的目标是学习感知到的一切可预测的东西,即智能系统应该能够从压缩表示中重新生成观测数据的分布,使其达到自身内部无法区分的程度。为了控制学习完全忠于表征过程,该研究引入了第二个原则:自洽原则,即自主智能系统通过最小化被观测对象与重新生成对象之间的内部差异,来寻求外部世界观测的最自洽模型。
不过自洽和简约是高度互补的,应该一起使用。仅靠自洽原则并不能确保压缩或效率方面的增益。
下图为一个闭环反馈系统,整个过程如图 6 所示。这个过程可以在编码器 f 和解码器 g 之间重复,产生一种自然的追逐和逃避游戏。
![]()
![]()
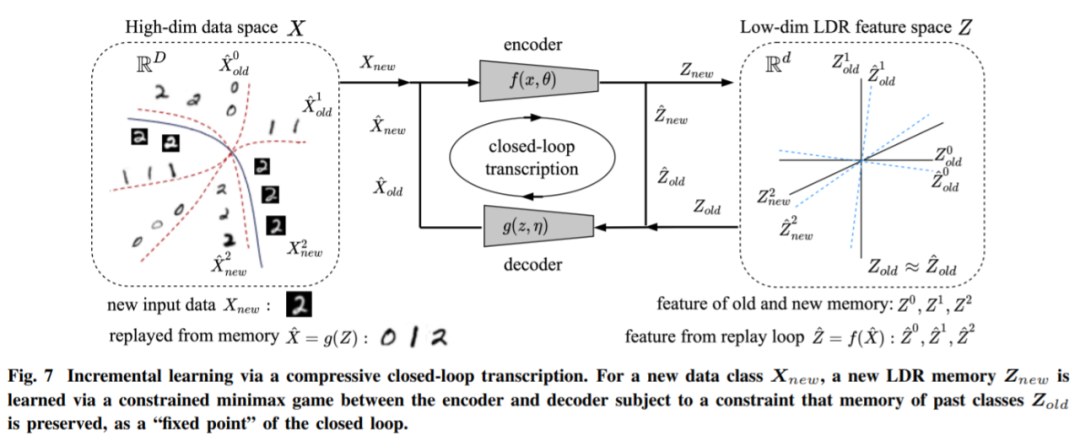
请注意,该框架的基本构想是在完全无监督的设置中工作。因此,即使出于示范目的,该研究提出了假设类信息可用的原则,但该框架可以自然地扩展到完全无监督的设置,其中没有为任何数据样本提供类信息。在这种情况下,只需将每个新样本及其增强视为(15)中的一个新类。这可以被视为一种自监督。结合自批评游戏机制,可以轻松学习压缩闭环转录。
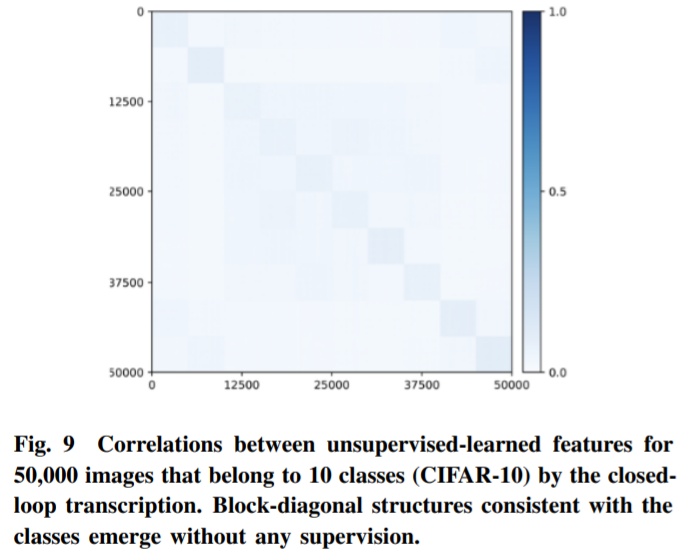
如图 8 所示,如此学习的自动编码不仅表现出良好的样本一致性,而且学习到的特征还表现出清晰且有意义的局部低维(薄)结构。更令人惊讶的是,即使在训练期间根本没有提供任何类信息,子空间或特征相关的块对角结构也开始出现在为类学习的特征中(图 9)。因此,学习到的特征结构类似于在灵长类动物大脑中观察到的类别选择区域。
![]()
![]()
在剩下的两节中,该研究对压缩闭环转录框架的普遍性提出了更多的推测性想法,并将其扩展到 3D 视觉和强化学习(第 3 节),预测其对神经科学、数学和更高层次的智能影响(第 4 节)。
3D 感知和决策被认为是自主智能系统的两个关键模块(LeCun,2022)。该研究推测,在这两个原则的指导下,研究者如何能够发展不同的观点和新的见解来理解这些具有挑战性的任务。
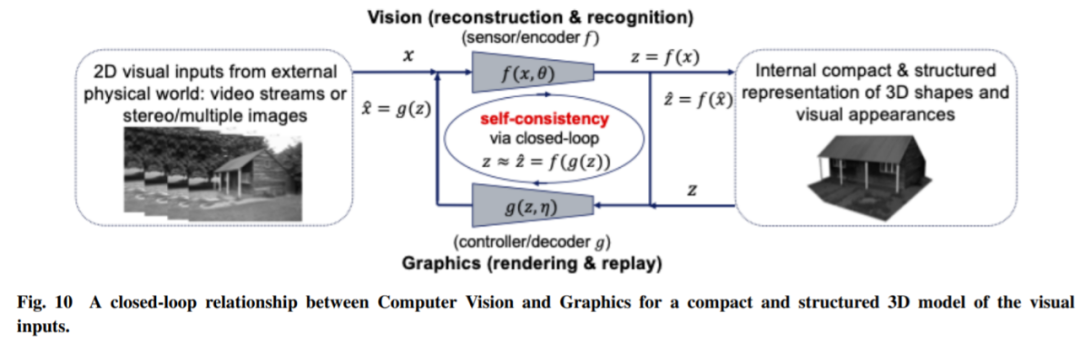
感知为压缩闭环转录?更准确地说,世界上物体的形状、外观甚至动力学的 3D 表征应该是我们大脑内部开发的最紧凑和结构化的表示,以一致地解释所有感知到的视觉观察。如果是这样,那么这两个原则就表明,一个紧凑和结构化的 3D 表征就是我们要寻找的内部模型。这意味着我们可以并且应该在一个闭环计算框架内统一计算机视觉和计算机图形,如图 10 所示。
![]()
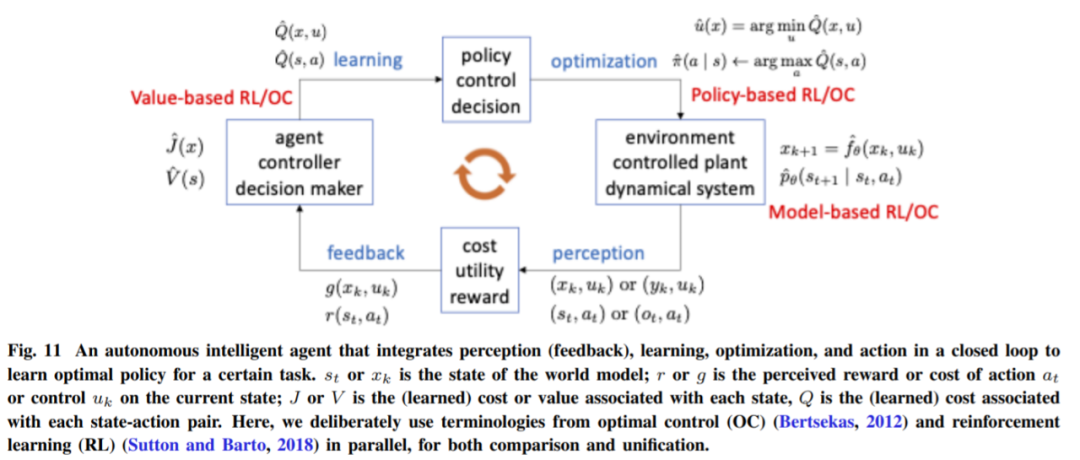
智能体从感知结果中学习或从其行动中获得奖励的整个过程形成了另一个更高级别的闭环(图 11)。
![]()
总而言之,对于大规模 RL 任务,正是这两个原则使得感知、学习和行动的闭环系统成为真正高效和有效的学习引擎。有了这样的引擎,如果环境和学习任务中确实存在这样的结构,自主智能体就能够发现低维结构,并最终在学习的结构足够好、泛化良好时智能地行动!
参考链接:https://weibo.com/u/3235040884?topnav=1&wvr=6&topsug=1
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com