3 月 23 日,在机器之心 AI 科技年会上,蚂蚁集团金融机器智能部总经理周俊发表了主题演讲《可信 AI 在数字经济中的实践与探索》。
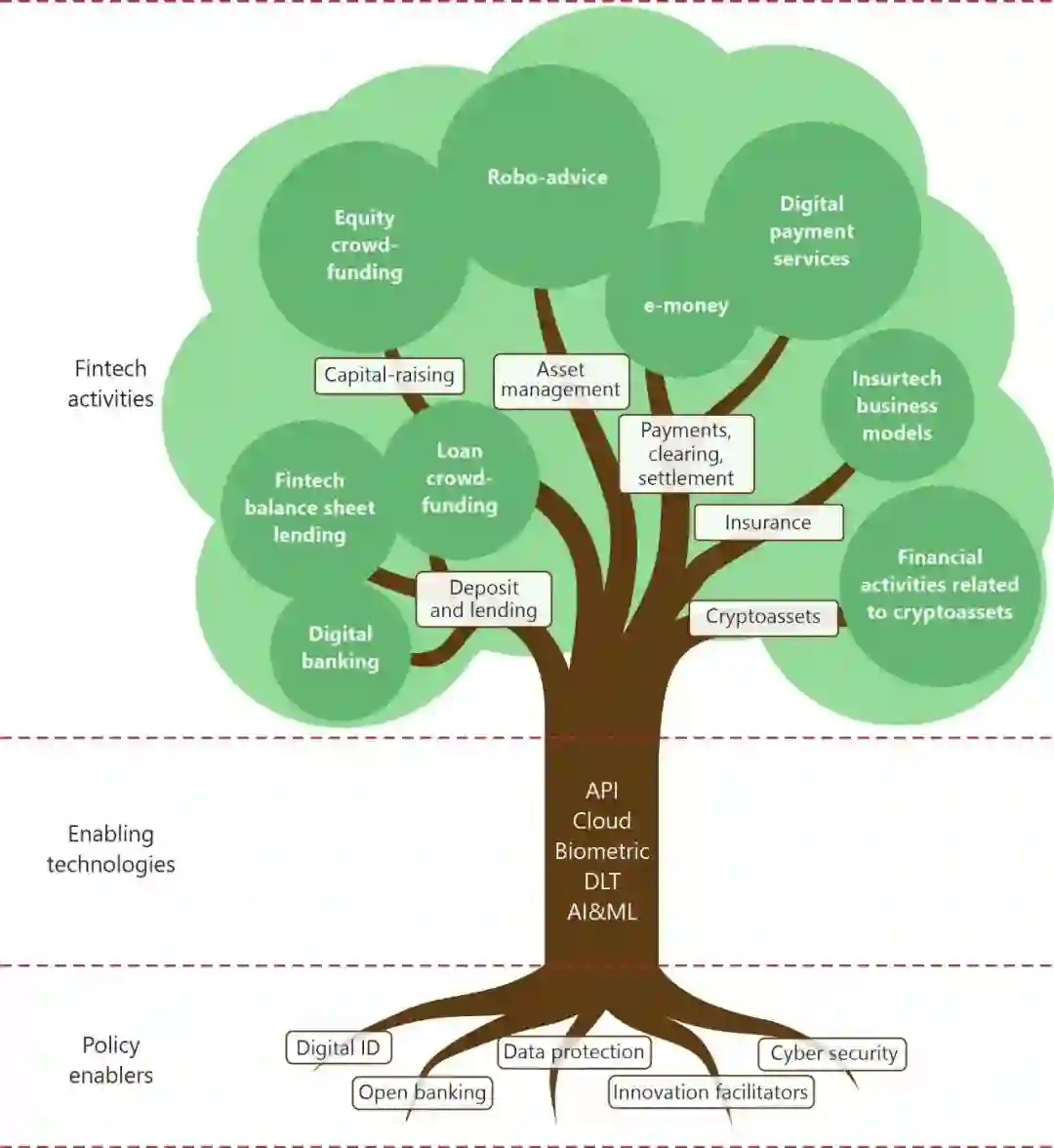
周俊介绍,如果将数字经济比作一棵树,树干中的人工智能 (AI)、大数据、云计算等技术,构成了数字经济的核心,起着承上启下的作用;树根中的隐私、安全等因素,决定长势以及未来;树干跟树根必须紧密融合,才能枝繁叶茂,其中 AI + 隐私、AI + 安全等成为当下亟需突破的方向。而可信 AI 技术理念将是数字时代抵御风险、提升科技包容度的关键能力之一。蚂蚁集团于 2020 年 6 月正式对外发布了其探索 6 年的可信 AI 技术架构体系,目前在
隐私保护、可解释性、鲁棒性、公平性
等技术体系方向上,已有不少的研究突破和落地,也依然任重道远,需要持续投入。
![]()
以下为周俊在机器之心 AI 科技年会上的演讲内容,机器之心进行了不改变原意的编辑、整理:
非常高兴来到机器之心。大家都知道人工智能正在成为日常生活中大家不可或缺的一部分,它被用于帮助用户完成各种各样的决策。但是 AI 技术其实也暴露出了很多弱点,比如偏见和易受攻击。为了解决 AI 中的这些问题,建立可信赖的人工智能的机制、方法将非常重要,这也是我今天要分享的主题,即可信 AI 在数字经济中的实践与探索。
具体到数字经济中,我们可以看到,在国际清算银行给出的金融科技框架里,AI 得到了广泛的应用。树干中的人工智能、云计算等技术成为了金融科技的核心,并且承载了非常重要的承上启下的作用。
![]()
图源:https://twitter.com/bis_org/status/1222834967920685057
在产业智能化的过程中,隐私保护、数据安全等根本性的问题对人工智能的影响会变得越来越重要,也决定了未来整个数字经济的走势。所以,树干跟树根必须紧密融合才有可能枝繁叶茂。其中,AI + 隐私 / 安全等成为当下大家亟需突破的方向。可信 AI 对企业和学术圈都非常重要,只有确保 AI 做出的决策安全可信、尊重隐私、容易理解,人们才能相信 AI,它才能真正发挥作用。
我们在打造数字经济平台的过程中也联合了很多外部的高校,着力发展出了可信 AI 的技术。我们希望可信 AI 在数据隐私保护、可解释性和因果分析、公平性和安全性(鲁棒性)方面都能有比较好的能力,这样才能满足公众或者业界对 AI 的期待。
为了实现可信 AI 的技术,我们在跟数字经济结合的同时,沉淀了一些重点的方向,比如对抗机器学习、图机器学习、可解释机器学习、可信隐私计算等等。通过这些重点技术的研发,我们能够为风险管理、安全风控、财富管理等上层具体应用提供支撑,确保这些方法论能够被科学地定义、拆解成工程的目标,从而推出各种平台和工具,使得 AI 整个生命周期里都能应用「可信 AI」这样一个理念。
![]()
接下来我会逐一介绍我们借助图学习等技术于
可解释、隐私保护、鲁棒、公平
四个方向取得的进展。
图是非常常见的非欧式空间下的一种数据结构,在社交网络、生物医药等领域都有非常广泛的应用。它实际上是对节点和边进行建模。由于图具有非常好的表达能力,这几年出现了大量的被称为图神经网络(GNN)的方法。GNN 是在图上面运行的深度学习方法,在推荐、欺诈检测等很多领域都有非常好的效果。
在实践中,我们发现,GNN 能够比较好地克服信息不足的问题,从而提升 AI 对长尾客户、小微企业等薄信息客群的服务能力,使得他们享受到数字服务、数字经济的概率大幅提升。它能提升 AI 的覆盖率,对 AI 的包容性也有正面的贡献。但是,一个比较大的挑战是如何处理工业级规模的图建模问题。
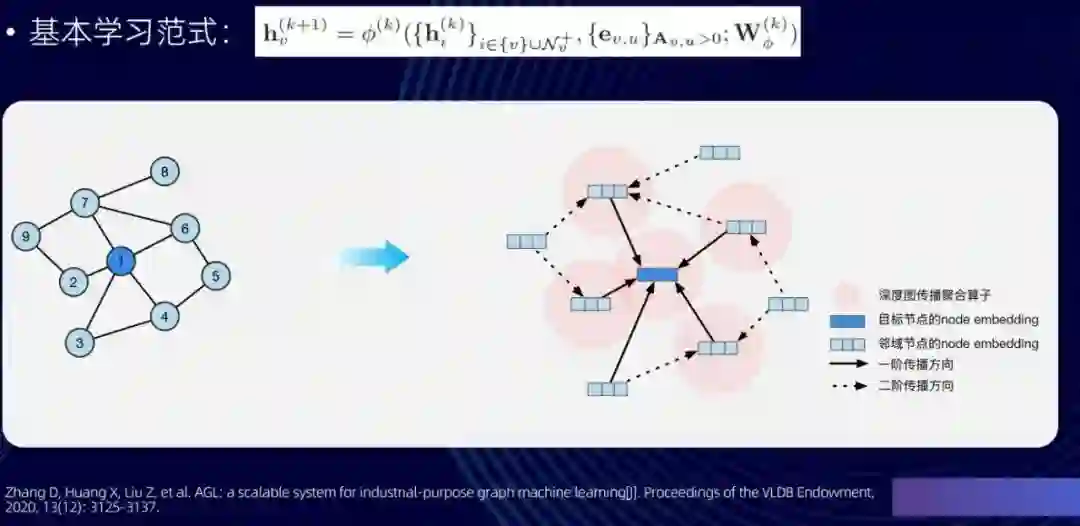
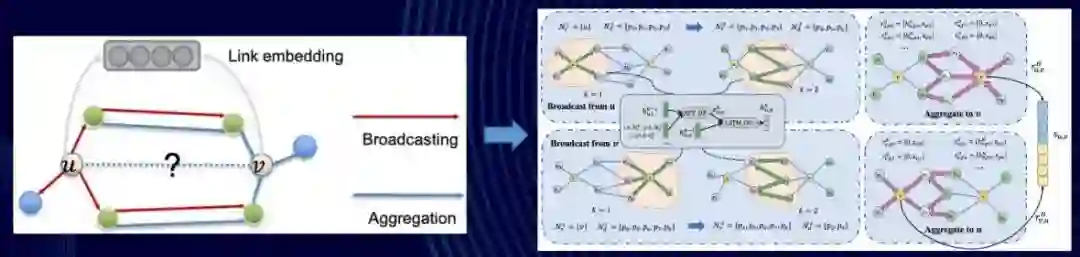
我们知道,在机器学习中,工程是算法的一个底座:没有强大工程的支持,算法很难被大规模应用。为了支持前面所说的工业级图数据的结构,我们首先研发了一个图学习系统——AGL(Ant Graph Learning)[1],这个系统会依据图神经网络里的两个经典操作——汇聚和更新——进行学习。我们这里列了一个基本公式。一个可以捕捉到 k-hop 邻居的图神经网络,它基本的 k 层的学习范式如图上所示,从示意图上也可以看到这里面所做的传播和聚合的方向:
![]()
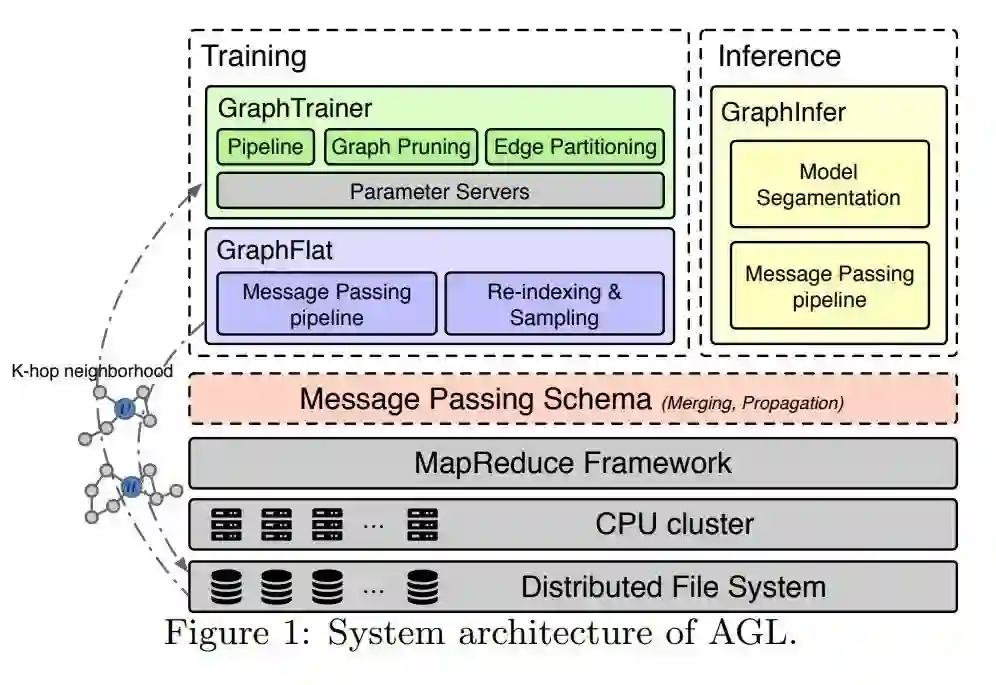
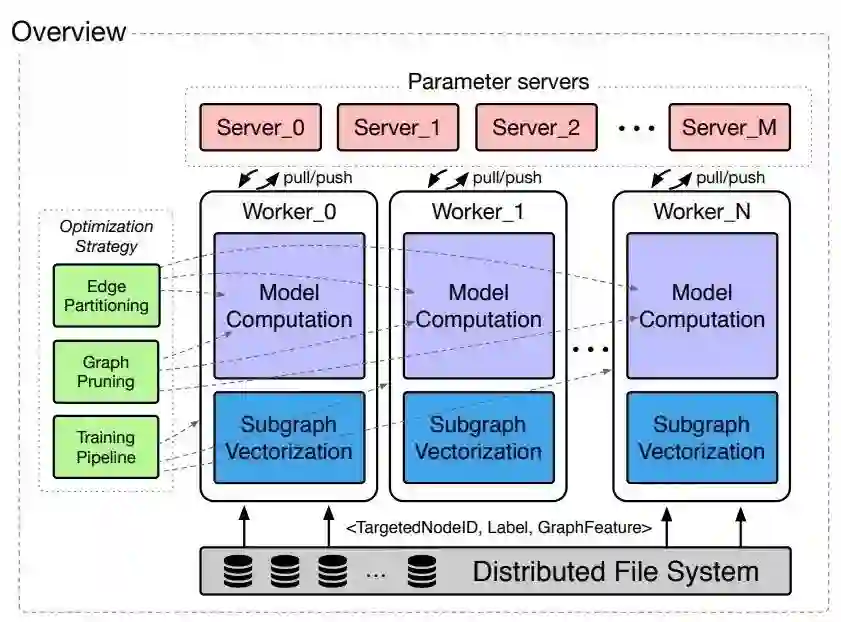
为了实现这样一个图神经网络的训练和大规模的推理,我们的系统主要分为三个部分。当然这个系统设计的初衷会更加关注可扩展性、容错性,以及尽可能对现有的方法进行复用。基于这样一个原则,我们有三个对应的核心模块:
![]()
首先,在训练器这一部分,我们运用了传统的参数服务器的结构。它可以存储比较大的参数,把参数切分成多片很好地存储起来,然后利用工业级系统中存在的大量机器资源,也就是 worker,进行并行的计算。
![]()
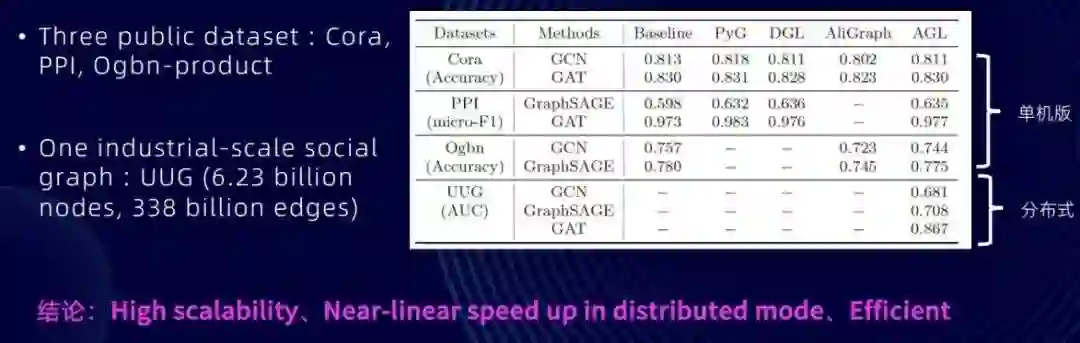
在 AGL 中,我们利用批处理框架如 MapReduce 来进行图样本生成,在训练期间设计了如边分区、图裁减和流水线并行等多种计算优化策略。我们能够看到,在一个比较大的工业级数据集上,在一个 62 亿节点、3300 多亿条边的真实的图数据上面,我们能够使用 3 万多个 core 完成真实系统的测试。也能够看到,在这样一个大规模数据集上面,我们的 AGL 系统能够具备近线性的加速比,并且有比较好的可扩展性,也为支持工业级规模的图机器学习的算法打下了比较坚实的基础。
![]()
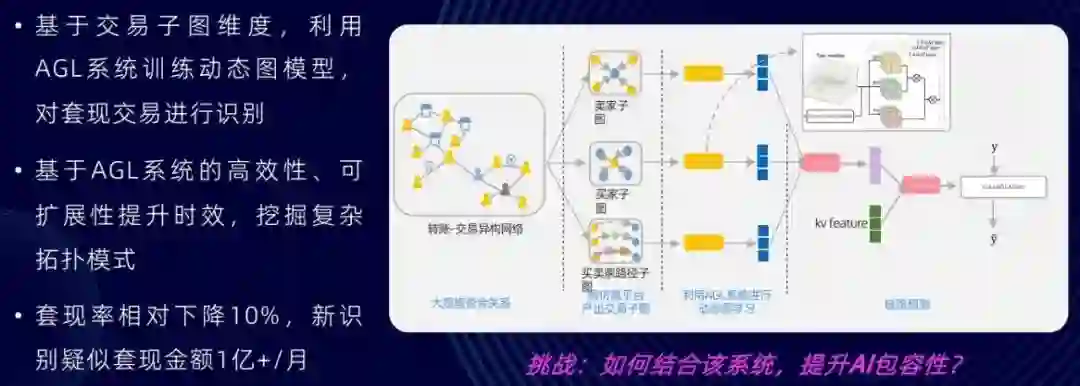
基于这样一个系统,我们首先设计了一个反套现的应用。我们利用这种转账交易的大规模资金的关系,针对买家子图、卖家子图、买卖家路径子图,通过图仿真产生出交易子图,然后再利用 AGL 系统进行动态的图学习,学习到图表征后我们会进行相应的链接预测,对大规模资金关系中存在的套现交易进行识别,使得套现率有比较大幅度的下降(相对下降 10%)。
![]()
完成了这个任务之后,第二部分是我们如何结合这样的系统提升 AI 的包容性,尤其是对于长尾用户和中小企业。我们发现,中小企业会存在麦克米伦缺口(由于金融资源供给不足而形成的巨大资金配置缺口),这经常困扰着中小企业的发展。我们也知道,中小企业是毛细血管,对经济、金融的运行产生了非常关键的作用。我们希望通过 GNN,使得分析信用历史有限的客户的信用度成为可能,从而满足中小企业在金融上的一些诉求,提升 AI 的包容性。
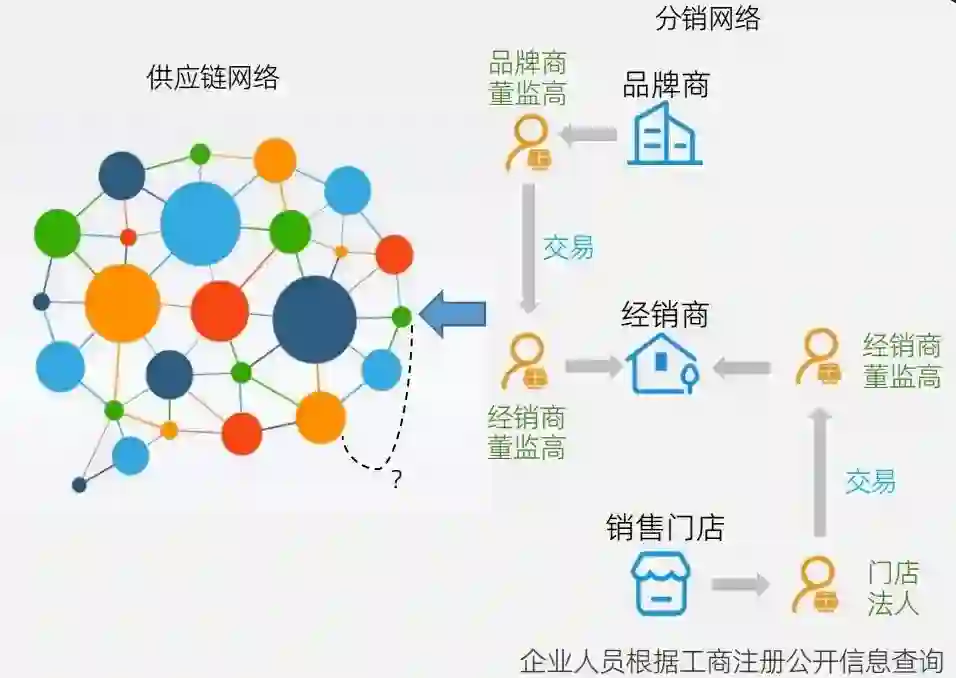
具体来说,我们首先会进行供应链挖掘(链接预测技术),即预测哪些企业之间可能存在经营族群,然后在隐私保护的前提下基于族群进行信用分析。因此,当我们能将大量的中小企业基于供应链族群汇聚到一起,并有了一定的分析之后,便能识别企业的信用情况。
![]()
为此,我们提出了一个时空结合的 GNN(Spatial-Temporal aware Graph Neural Network,ST-GNN )[2]。首先,我们通过前面提到的供应链挖掘补足企业之间的关联,再结合图里面现有的一些风险标签,通过这个时空结合的 ST-GNN 方法,把这样一个问题转化成信用评分的问题,从而对整张供应链网络里面的企业完成信用评分,基于这样的信用评分评估这个企业违约的概率,从而满足他们金融上的诉求。
![]()
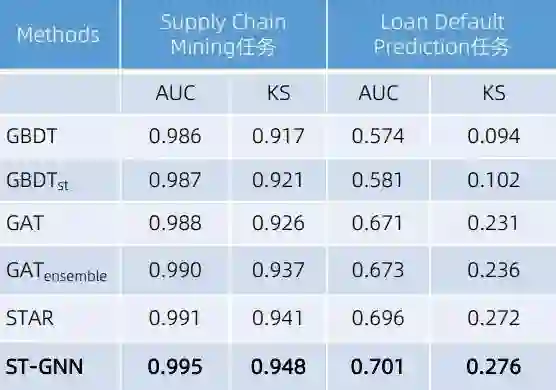
我们跟一些传统方法(如 GBDT、GAT)做了对比。结果显示,我们这个结合了时空信息的方法能够在中小企业的金融诉求预测上大幅改进模型的性能。主要原因在于,我们的方法结合了很多图上面的信息,而且设计了时空注意力的机制,能够比较好地融合多元、多维度的信息,体现出企业之间比较复杂的族群相关度,从而识别中小企业的信用评分,基于这样的信用评分助力他们享受对应的金融服务。
![]()
为了提高供应链挖掘的能力,我们也提出了另外一种路径感知的图神经网络(Path-aware Graph Neural Network,PaGNN)[3]。它融合了传播和汇聚两个算子,并在融合的过程中学到了两个节点之间的结构(比如路径的结构),这样就能更好地判断两个节点之间可能存在的复杂相关,从而更好地绘制族群,助力供应链金融,满足中小企业资金上的需求。
![]()
我们这里给了一个案例。首先,通过公开的企业数字信息,我们可以查到供应链网络的一张图。有了这样一张图之后,我们可以形成某些品牌的供应链网络,然后再通过前面提到的各式各样的 GNN 方法对图进行相关度挖掘,然后再把它转成信用评分的问题。有了这样的一个图的方法之后,族群发现的准确率也有比较大的提升,这可以助力下游的企业更好地拿到经营性贷款,可以提高 AI 覆盖率和包容性。
![]()
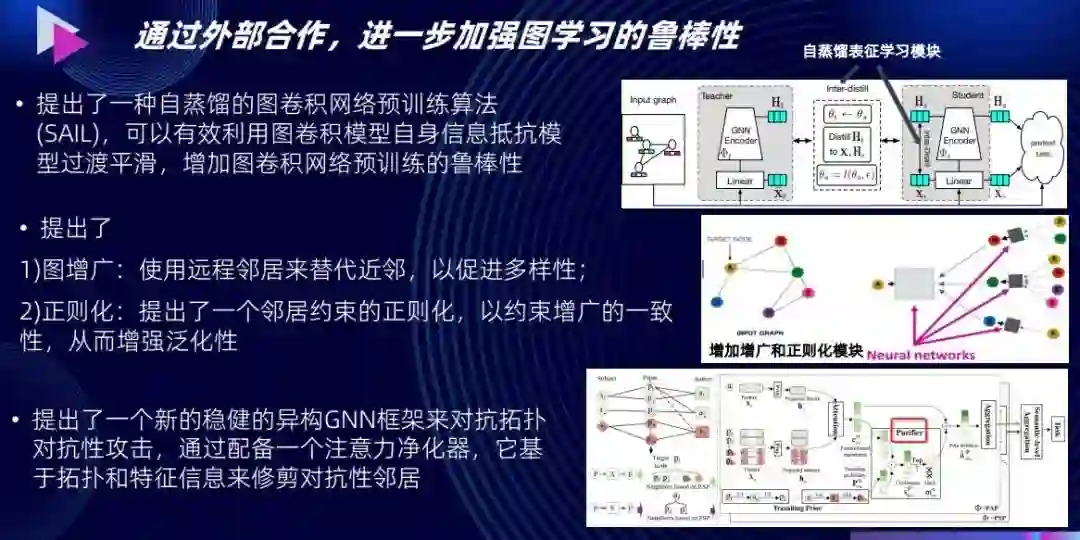
同时我们也注意到,图学习这种算法本身存在鲁棒性的问题。于是,我们跟外部高校合作,提高了模型的鲁棒性,也解决了模型过渡平滑、难泛化等潜在问题。我们还提出了一个新的稳健的异质 GNN 框架来对抗拓扑对抗性攻击。它配备一个注意力净化器,基于拓扑和特征信息来修剪对抗性邻居,从而进一步增强 AI 的可靠性 [4] [5] [6] 。
![]()
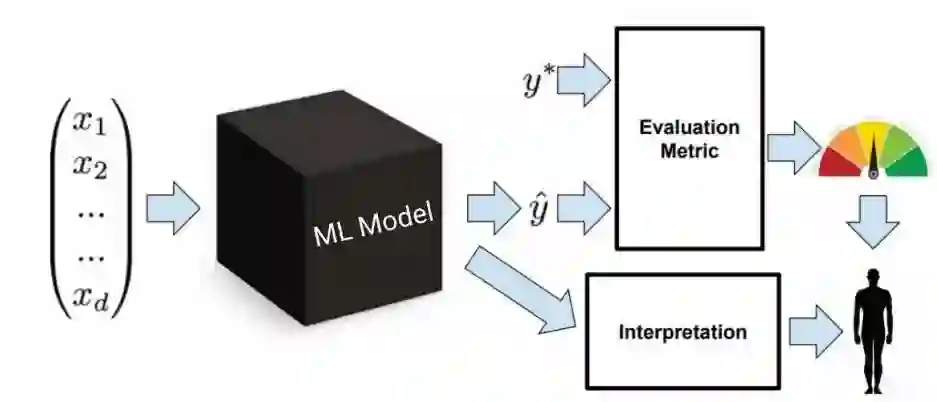
现在很多 AI 的方法都是一个黑盒模块(下图),人们对中间的过程并不是特别了解。我们希望通过可解释的机器学习,让黑盒由黑变灰(在一定程度上可解释),并最终变成白盒(完全可解释)。可解释机器学习使得机器学习模型能够以易于理解的方式向用户解释或呈现其行为。
![]()
我们提出了一种新的方法—— COCO(COnstrained feature perturbation and COunterfactual instances) [7] 来解释任意模型的测试样本。在此之前,业界已经有一些可解释方法,比如自身可解释性方法(如决策树)、全局可解释性方法(如 PLNN)、后置局部可解释性方法(如 SHAP)等。而我们提出的是一个比较适合在工业界中应用的可解释性方法。
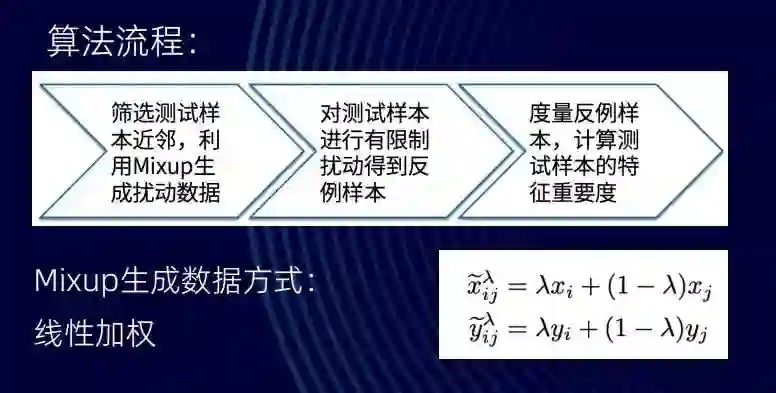
这个方法本身不是很复杂,算法的流程主要分三步:首先,它会去筛选测试样本的近邻,利用 Mixup 生成扰动数据;然后,它会对测试样本进行有限制的扰动得到反例样本;最后,它通过度量反例样本,计算测试样本的特征重要度,来给出任意模型的可解释性。
![]()
在图像数据上面,我们这个方法筛选出了前 200 个重要特征。画成图的话,这些特征基本上贴合在数字的边界上,这样一看就知道挖掘出来的重要特征确实在上面。在工业界中常用的表格上面,我们也会先把重要特征挖掘出来,再训练成模型,然后看模型挖掘出来的重要特征和其他方式(如 SHAP、LIME)挖掘出的特征精度效果的对比。可以看到,我们的方法在精度上有比较好的效果。
![]()
据此,我们可以得出这样几个结论:一是通过有限制的扰动,COCO 能够更容易辨识出重要特征;二是通过 Mixup 进行增广,数据会更合理;三是 COCO 鲁棒性表现相对较好并且更稳定。
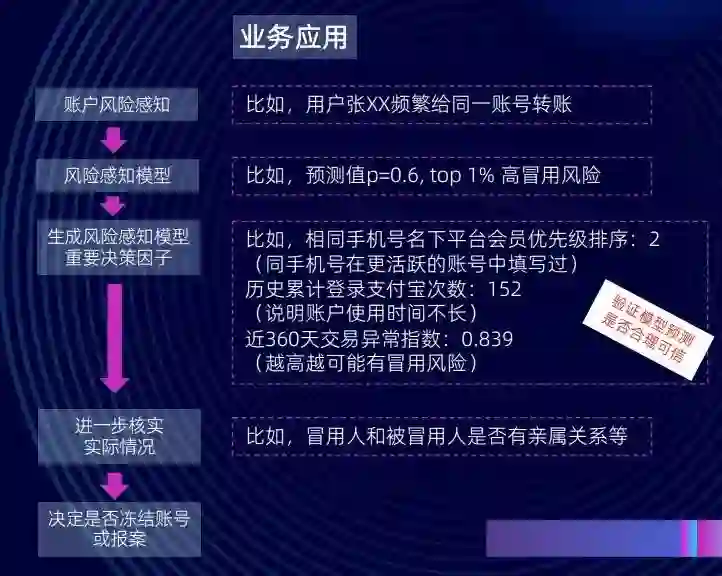
我们将这样的方法用到了风险感知场景中。比如有时候我们发现某人(如张某某)支付宝有两个账户,他用一个账户频繁给自己的同一账户进行转账。此时,我们的风险感知模型可能会判断这个账户被冒用了。我们希望知道这个风险感知模型为什么会做出这样一个决策。因此,我们会用 COCO 模型生成该风险感知模型的重要决策因子。我们最后可能会得出这样一些因子:比如说相同手机号名下平台会员优先级排序;历史累计登录支付宝次数;近 360 天交易异常指数等。
通过这样的一些重要特征,我们可以分析一个风险感知模型为什么会做出某个决策,从而去验证这个风险感知模型是否合理,它给出的结果是不是可信、可靠。通过这样一个方式,我们把这些重要决策因子给到业务决策,他们会进一步核实实际情况(比如冒用人和被冒用人之间是否有亲属关系),然后再进一步去做人机结合的判断,决定是否冻结账号或报案。这能使我们的业务人员更好地理解风险感知模型决策的逻辑,也能帮助我们的业务专家结合模型解释来帮助决策,控制模型风险。
![]()
在这样一个涉及金融账户的决策里,我们其实是非常谨慎的。我们希望更好地控制模型的风险及对用户的打扰,使得风险感知模型能够比较好地保护大家的账户安全,打击犯罪。我们也希望专家理解这个模型,然后把业务的经验反哺到业务模型里面,从而使人机结合达到比较好的效果。
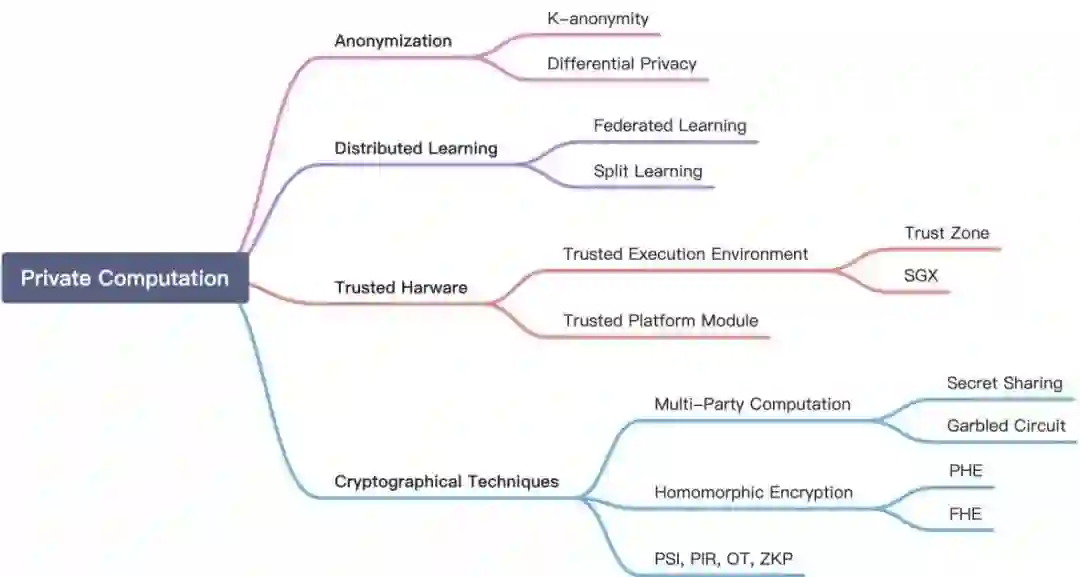
隐私保护已经在业界发展了很多年,也积累了很多术语,比如匿名化、差分隐私、TEE、多方安全计算等。每一种技术都有自己适用的场景。但我们发现,现在的隐私保护技术很难在模型强度、精度、效率三方面取得比较好的平衡,这三方面目前是一个相互制约的局面。
![]()
我们在推荐、营销、广告等工业场景中经常见到大量的数据,同时又非常稀疏。虽然学术圈有很多隐私机器学习方法,但如何将它们应用到大规模稀疏数据上是一个比较大的问题。
为此,我们提出了一种名为 CAESAR(Secure Large Scale Sparse Logistic Regression)[8] 的方法,它会基于混合 MPC 协议,设计出大规模隐私保护 LR 算法。
![]()
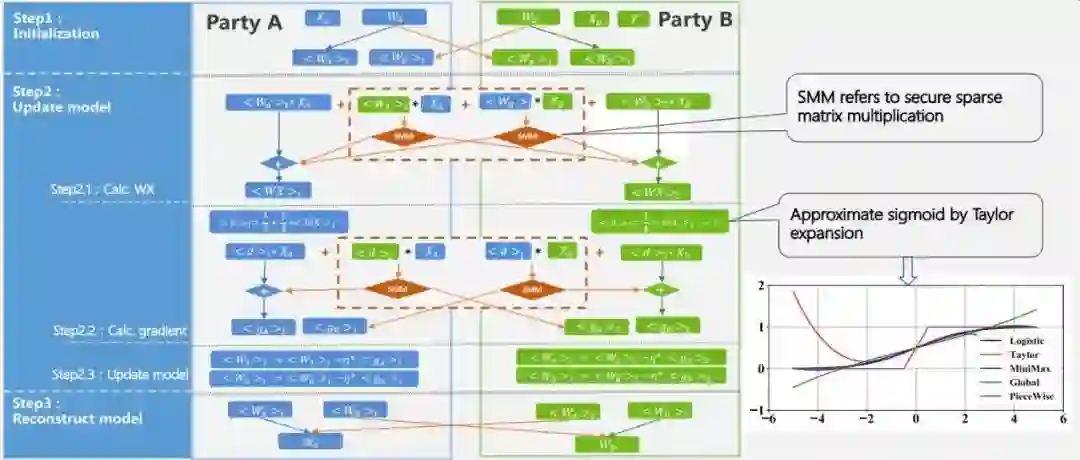
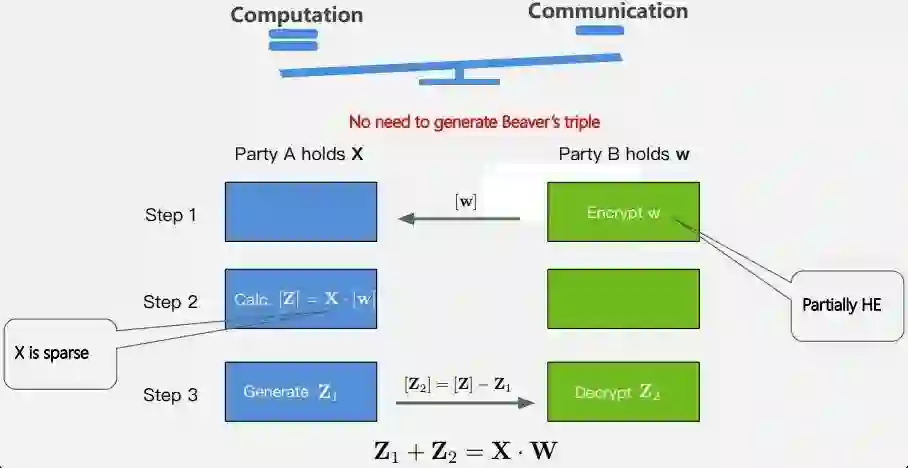
为什么会设计这样一个混合 MPC 协议?因为我们发现:1)虽然同态加密协议总体来说通信复杂度比较低,但是计算复杂度比较高,而秘密分享协议的通信复杂度虽然较高,但计算复杂度较低;2)机器学习模型中的非线性函数在密态空间下没有办法直接计算,或者说计算性能没有办法满足真实场景的需求,需要高效的表达式,在满足模型精度的前提下降低函数的计算要求 ,进一步降低通信开销。因此,我们提出了混合 MPC 协议,设计了隐私保护矩阵乘法,再通过泰勒展开去降低非线性运算的复杂度,完成了 LR 的方法。
这里面的要点包括:1)稀疏的矩阵乘法,我们通过混合的 MPC 协议,在合适的地方选择合适的协议,不需要产生 Beaver’s triple,能够更好地提升效率;2)安全、稀疏的矩阵运算,能够同时交叉利用秘密分享和同态加密的技术,最后结合分布式计算,在协调器的指挥下充分利用已经有的集群资源。每个集群本身也是分布式的学习系统,通过这样的方式,我们能够非常好地去进行分布式的运算,然后再通过整体的协调器的协调来完成最终的运算。
![]()
![]()
通过这种方式,我们发现 CAESAR 的效率达到了业界已有的 SecureML 方法的 130 倍左右。
![]()
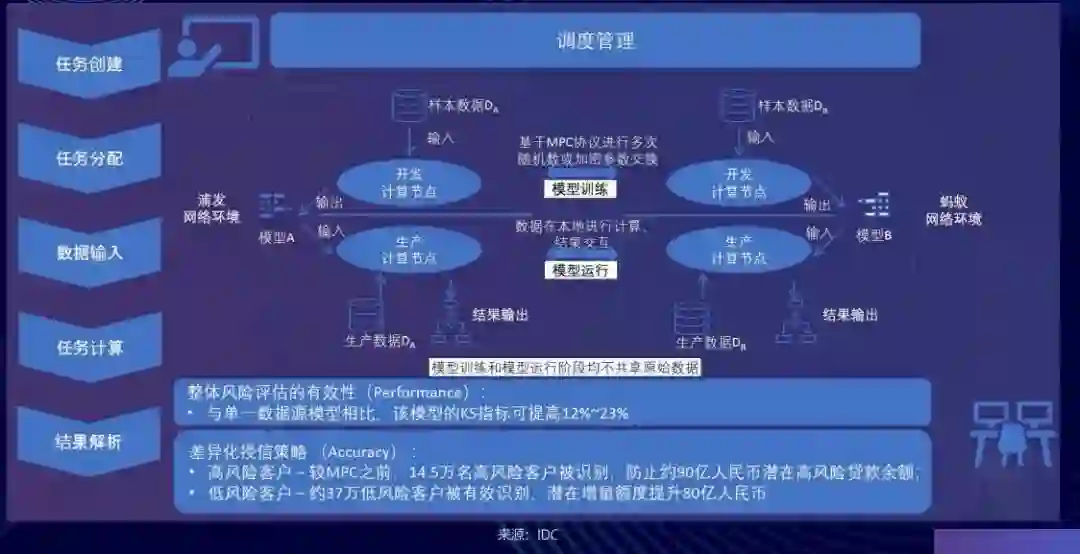
基于这样的隐私保护技术,我们跟浦发银行做了联合风控的应用。我们在已经授权的数据上进行了尝试,使得模型训练和模型运行阶段均不共享原始数据。与单方面运算相比,联合运算的模式能够更好地提升模型的性能指标(比如将 KS 指标提升 12%~23%)。将模型产出的结果运用到风控场景中,我们能比较好地实现差异化的授信策略,防止潜在高风险贷款,从而将合适的贷款给到合适的人,真正实现防范金融风险的目的。
![]()
同时,我们也将这样的技术应用到了联合分析和知识融合等场景 [9]。其核心技术可以概括为:基于云计算和可信隐私计算技术,通过模型梯度和参数安全共享来实现价值的流通,这可以应用于机构内部的运营优化和机构之间安全共享信息。比如我们可以通过隐私保护知识图谱等技术,实现机构之间领域知识融合,提升实体识别准确率,助力保险疾病、证券分析等应用。
![]()
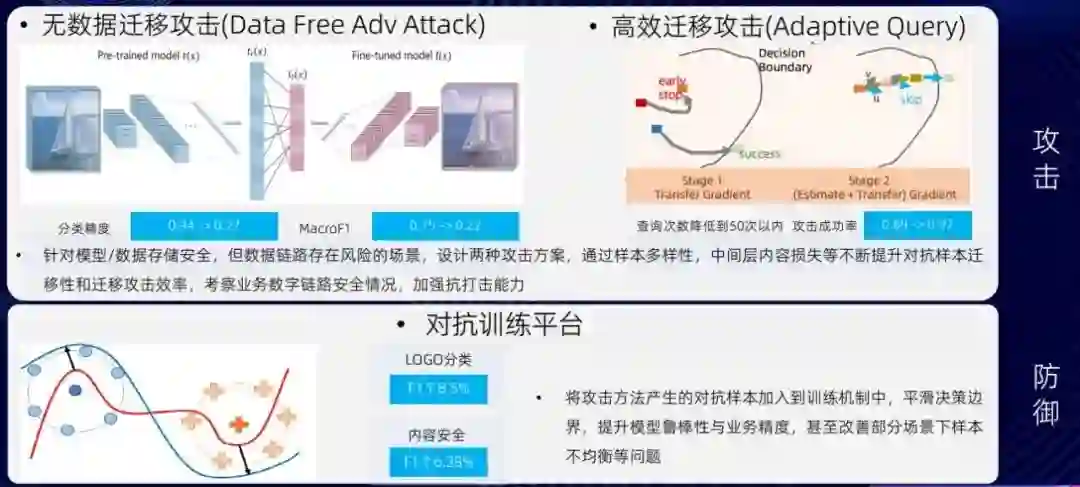
在对抗机器学习中,我们主要采用的是左右手互搏的方式,即假定我们对模型本身没有太多的了解,基于这样一个假定去攻击我们的系统(黑盒攻击)。我们设计了两种攻击方式(如下图)。通过这样的一些攻击方案以及样本的多样性,我们希望不断提升样本的迁移性和迁移攻击效率,以此来考察业务当中数字链路的安全情况,增强抗打击能力。同时,我们将对抗攻击中产生的样本也放到了机器学习训练的平台里面。我们搭建了一个对抗训练的平台,将前面攻击方法所产生的样本融合到训练机制中,使得决策边界从红线变到蓝线,相应来说会更平滑,更平滑意味着通用性会变得更好,能够提升模型的鲁棒性,甚至在某些情况下能够改善样本不均衡的问题,从而带来业务精度的提升 [10] 。
![]()
前面我们总结了很多可信 AI 在数字经济当中的落地和实践,从包容性到可解释隐私保护到对抗学习。我们也发现,企业 AI 的每一小步的应用都意味着我们离智能未来的梦想更近了一点。
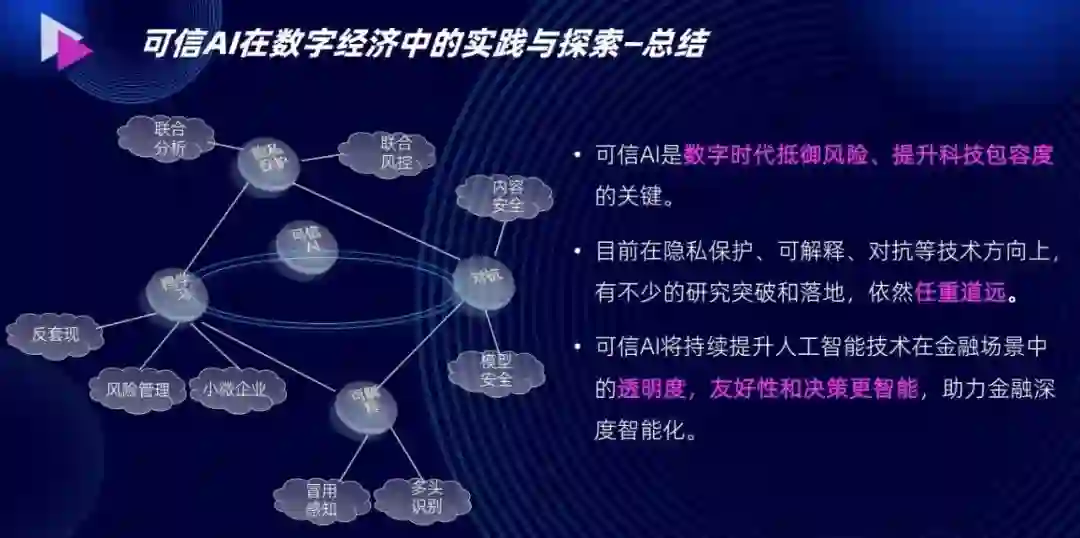
在实践和探索可信 AI 的过程中,我们也发现,业界虽然有一些可信 AI 的落地案例和研究,但这个方向依然任重而道远。虽然已经有不少的突破,但目前大部分的突破还聚集在点状的场景上面。
我们也坚信,可信 AI 技术能够持续提升人工智能技术在金融场景中的透明度、友好性,会使得决策更智能。由于目前的 AI 还处于高速发展的阶段,我们今天分享的实践和落地可能离最终的可信 AI 还有些距离,我们也希望通过今天分享的我们在工业界中的研究、实践、踩坑经验和不成熟的尝试,能够让更多的同行去深入思考,能够真真正正地做到通过可信 AI 抵御数字时代的风险,提升科技包容度。
![]()
[1] Zhang D, Huang X, Liu Z, et al. AGL: a scalable system for industrial-purpose graph machine learning[J]. Proceedings of the VLDB Endowment, 2020, 13(12): 3125-3137.
[2] Yang S, Zhang Z, Zhou J, et al. Financial Risk Analysis for SMEs with Graph-based Supply Chain Mining[C]//IJCAI. 2020: 4661-4667
[3] Yang S, Hu B, Zhang Z, et al. Inductive Link Prediction with Interactive Structure Learning on Attributed Graph[C]//Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, Cham, 2021: 383-398.
[4] Yu L, Pei S, Zhang C, et al. Self-supervised smoothing graph neural networks[C]. AAAI 2022, accepted.
[5] Bo D, Hu B B, Wang X, et al. Regularizing Graph Neural Networks via Consistency-Diversity Graph Augmentations[C]. AAAI 2022, accepted.
[6] Zhang M, Wang X, Zhu M, et al. Robust Heterogeneous Graph Neural Networks against Adversarial Attacks[C]. AAAI 2022, accepted.
[7] Fang J P, Zhou J, Cui Q, et al. Interpreting Model Predictions with Constrained Perturbation and Counterfactual Instances[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2021: 2251001.
[8] Chen C, Zhou J, Wang L, et al. When homomorphic encryption marries secret sharing: Secure large-scale sparse logistic regression and applications in risk control[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 2652-2662.
[9] Chen C, Wu B, Wang L, et al. Nebula: A Scalable Privacy-Preserving Machine Learning System in Ant Financial[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 3369-3372.
[10] Huan Z, Wang Y, Zhang X, et al. Data-free adversarial perturbations for practical black-box attack[C]//Pacific-Asia conference on knowledge discovery and data mining. Springer, Cham, 2020: 127-138.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com