【导读】Transformer是当下流行的模型。牛津大学等学者发布首篇《Transformer多模态学习》综述论文,23页pdf涵盖310篇文献全面阐述MMT的理论与应用。

Transformer是一种很有前途的神经网络学习器,在各种机器学习任务中都取得了很大的成功。随着近年来多模态应用和大数据的普及,基于Transformer 的多模态学习已成为人工智能研究的热点。本文介绍了面向多模态数据的Transformer 技术的全面综述。本次综述的主要内容包括:(1)多模态学习、Transformer 生态系统和多模态大数据时代的背景,(2)从几何拓扑的角度对Vanilla Transformer、Vision Transformer和多模态Transformer 进行理论回顾,(3)通过两个重要的范式,即多模态预训练和具体的多模态任务,对多模态Transformer 的应用进行回顾。(4)多模态Transformer 模型和应用共享的共同挑战和设计的总结,以及(5)对社区的开放问题和潜在研究方向的讨论。
https://www.zhuanzhi.ai/paper/0da69832c8fd261e9badec8449f6fe80
人工智能(AI)的最初灵感是模仿人类的感知,如视觉、听觉、触觉、嗅觉。通常情况下,一个模态通常与创建独特通信通道的特定传感器相关联,例如视觉和语言[1]。对于人类来说,我们感官感知的一个基本机制是,为了在动态的、不受约束的环境下恰当地参与世界,我们能够共同利用多种感知数据模式,每一种模式都是具有不同统计特性的独特信息源。例如,一幅图像通过数千个像素给出了“大象在水中玩耍”场景的视觉外观,而相应的文本则用一个使用离散单词的句子描述了这一时刻。从根本上说,多模态人工智能系统需要摄取、解释和推理多模态信息源,以实现类似人类水平的感知能力。多模态学习(MML)是一种构建人工智能模型的通用方法,可以从多模态数据[1]中提取和关联信息。
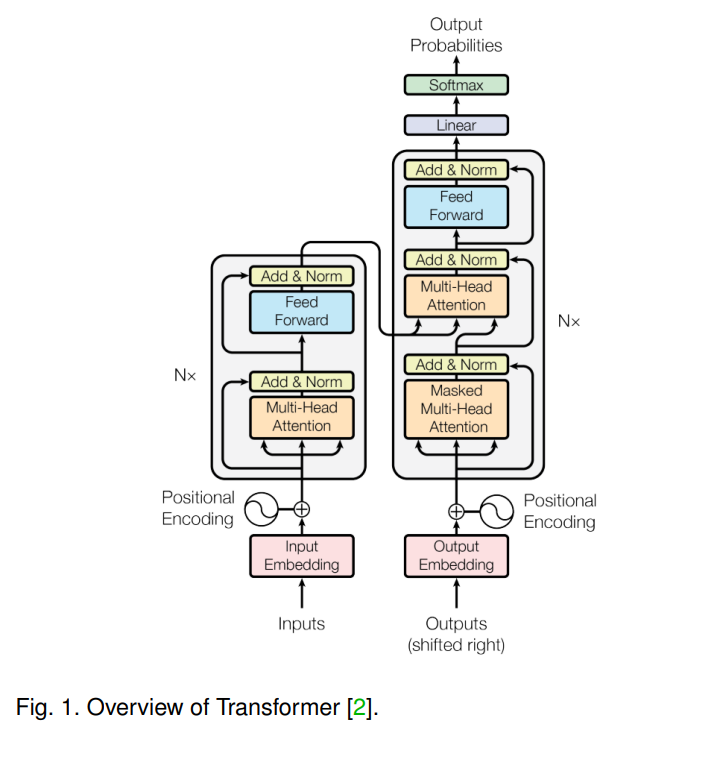
本综述聚焦于使用Transformers[2]进行多模态学习(如图1所示),其灵感来自于它们在建模不同模态(例如,语言、视觉、听觉)和任务(例如,语言翻译、图像识别、语音识别)方面的内在优势和可扩展性,并且使用较少的模态特定架构假设(例如,翻译不变性和视觉中的局部网格注意偏差)[3]。具体地说,Transformer的输入可以包含一个或多个令牌序列,以及每个序列的属性(例如,形态标签、顺序),自然地允许在不修改架构的情况下使用MML[4]。此外,学习每模态特异性和多模态相关性可以简单地通过控制自注意力的输入模式来实现。关键的是,最近在不同学科探索Transformer架构的研究尝试和活动激增,导致近年来开发了大量新颖的MML方法,以及在[4]、[5]、[6]、[7]、[8]等不同领域取得了显著和多样的进展。这就需要对具有代表性的研究方法进行及时的回顾和总结,以使研究人员能够理解MML领域各相关学科的全局图景,更重要的是能够获得当前研究成果和主要挑战的整体结构图。
为了提高不同学科之间的可读性和可达性,本文采用了一种两层的结构化分类法,分别基于应用维度和挑战维度。这有几个好处:(1)在特定应用领域具有专长的研究人员可以在连接到其他相关领域之前找到适合自己研究领域的应用。(2)将不同领域发展的相似模型设计和体系结构归纳在一个抽象的、公式驱动的视角下,使不同应用中形成的各种模型的数学思想在共同点上相互关联和对比,跨越特定领域的限制。至关重要的是,我们的分类法提供了一个有趣的立体视角,个人作品在应用特异性和配方普遍性的见解。希望这有助于打破领域界限,促进更有效的理念沟通和跨模式交流。通过使用提示建模策略[9]作为研究的基础,我们还包括了经典的分类问题(例如图像分类)——通常被认为是传统MML综述中的单一模态学习应用——[1],[10],[11]——作为特殊的MML应用。
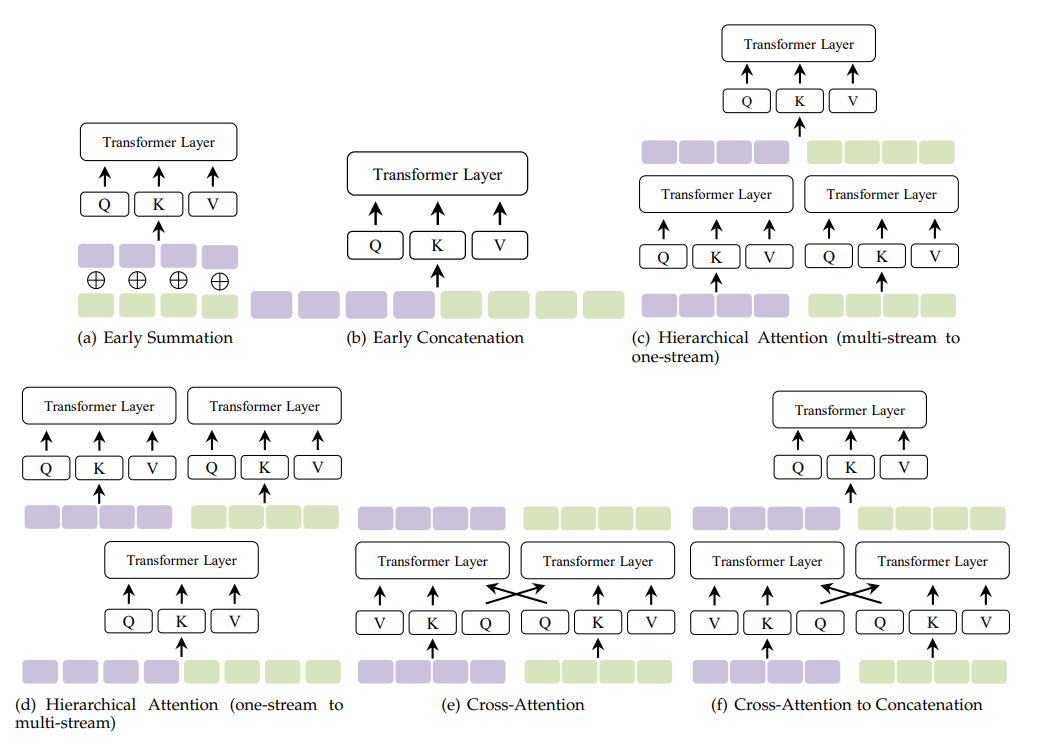
本综述将讨论Transformer架构的多模态具体设计,包括但不限于以下几种模态:RGB图像[5],深度图像[13],视频[7],音频/语音/音乐[13],[14],[15],表[16],场景图/布局[17],[18],[19],姿势骨架[20],SQL[21],[22],菜谱[23],编程语言[24],手语[25],[26],[27],点云[28],符号知识(图)[29],[30],多模式知识图谱[31],草图绘制[32],[33],[34],[35],3D对象/场景[36],[37],[38],文档[39],[40],[41],[42],编程代码[43]和抽象语法树(AST)——一类图[44]、光流[45]、医学知识(如诊断代码本体[46])。注意,本综述将不讨论多模态论文,其中Transformer只是作为特征提取器使用,而没有多模态设计。据我们所知,这是第一个全面回顾基于Transformer的多模态机器学习的状态。
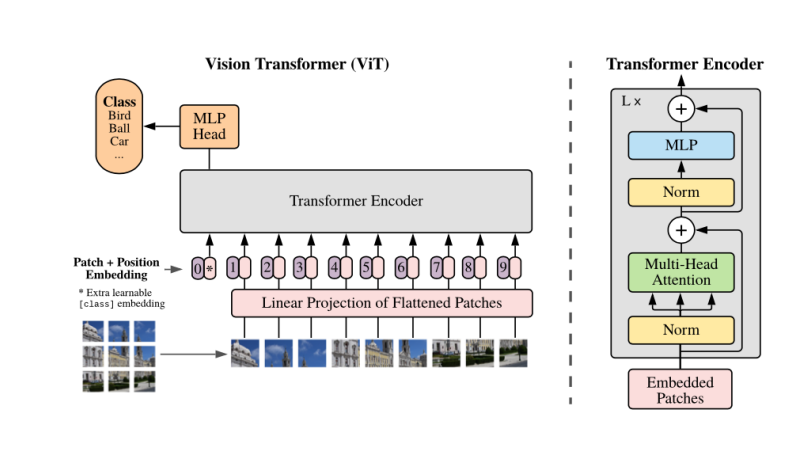
这项综述的主要特点包括:(1)我们强调Transformer的优势是它们可以以一种模式无关的方式工作。因此,它们与各种模态(以及模态的组合)兼容。为了支持这一观点,我们首次从几何拓扑的角度对多模态环境下Transformer的内在特征进行了理解。我们建议将自注意视为一种图风格的建模,它将输入序列(包括单模态和多模态)建模为一个全连接图。具体地说,自注意模型将任意模态中的任意标记嵌入为一个图节点。(2) 我们在多模态环境中尽可能以数学的方式讨论Transformer的关键部件。(3)基于Transformer,跨模态交互(如融合、对齐)本质上是由自注意及其变体处理的。在本文中,我们从自注意力设计的角度,提取了基于MML实践的Transformer的数学本质和公式。在介绍了我们对多模态学习、Transformer生态系统和多模态大数据时代的综述之后,我们总结了我们的主要贡献如下。(1)我们从几何拓扑的角度对Vanilla Transformer、视觉Transformer和多模态Transformer进行了理论回顾。(2)我们从两个互补的角度对基于Transformer的MML进行了分类,即基于应用和基于挑战。在第4节中,我们通过两个重要的范例,即多模态预训练和具体的多模态任务,对多模态Transformer的应用进行了回顾。在第5节中,我们进行总结各种多模态Transformer 模型和应用所共享的共同挑战和设计。(3)讨论了基于Transformer 的MML技术目前的瓶颈、存在的问题和潜在的研究方向。