北大AI公开课!京东何晓冬:自然语言与多模态交互前沿技术

本文由 AI 前线(ID:ai-front)独家整理首发,未经授权请勿转载

课程导师:雷鸣, 天使投资人,百度创始七剑客之一,酷我音乐创始人,北大信科人工智能创新中心主任,2000 年获得北京大学计算机硕士学位,2005 年获得斯坦福商学院 MBA 学位。

特邀讲者:何晓冬博士,现任京东 AI 研究院常务副院长,深度学习及语音和语言实验室主任,并任华盛顿大学(西雅图)电子与计算机工程系兼职教授。何晓冬博士是 IEEE Fellow。他的研究方向主要聚焦在人工智能领域,包括深度学习、自然语言处理、语音识别、计算机视觉及多模态智能。
以下为何晓冬老师课程内容(略有删减)
今天的主题是自然语言与多模态交互的一些前沿技术,下面我会进行一些具体的展示。
深度学习可简单认为是深层的神经网络模型。回到多年前,大概在七八十年代,那时是单层的感知机和浅层的神经网络。理论上多层神经网络拥有非常强的分类能力,能拟合任意分类边界。80 年代,学术界技术界对神经网络期望是非常高的,但是很快在 90 年代的时候,大家发现神经网络由于各种原因,如数据不足,训练很困难,在很多任务上做的不如简单的模型好,大家对它的期望就降下来了。但即便在这个低谷时期,还是有科学家坚持把这个领域往前推动。
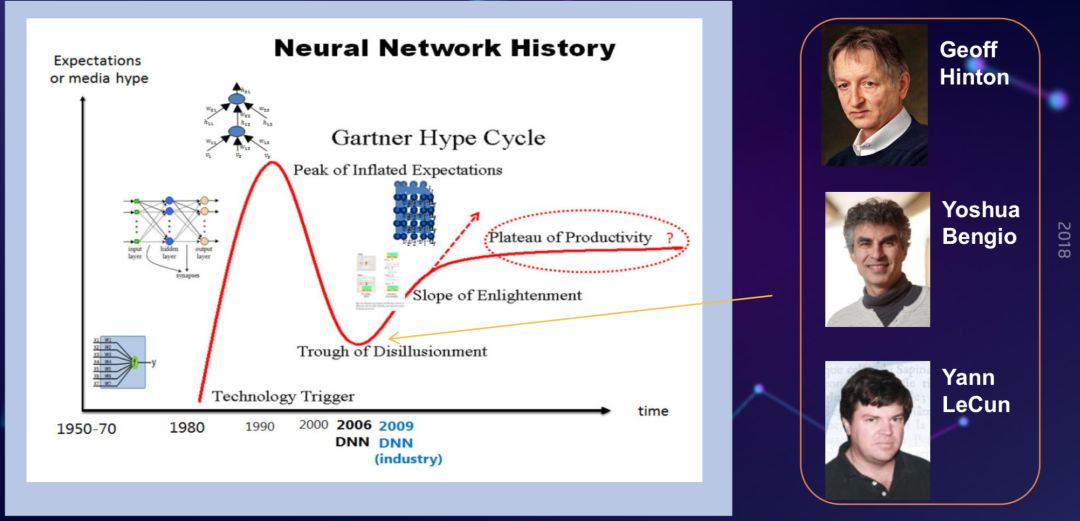
2006 年以后,Geoff Hinton,现在被认为是深度学习之父,提出 RBM 和分层训练方法,开始使训练深层的神经网络成为可能,在 2010 年左右,Hinton 教授跟微软研究院等合作在大规模的语音识别上取得很大的进展。大家重新对深度神经网络产生信心,从那时候开始,大家开始推进对深度神经网络的研究。此后,基于深度学习新的突破,带来了很多 AI 技术的突破,以及产业上的突破,特别是产业界提供了大量的计算力量,提供了真实的场景,进一步促进了 AI 的技术进步。
在语音识别上,会看到深度学习有非常明显的影响力。这个图大概是过去几十年,语音识别核心领域的进展,语音识别是个非常经典的人工智能问题。
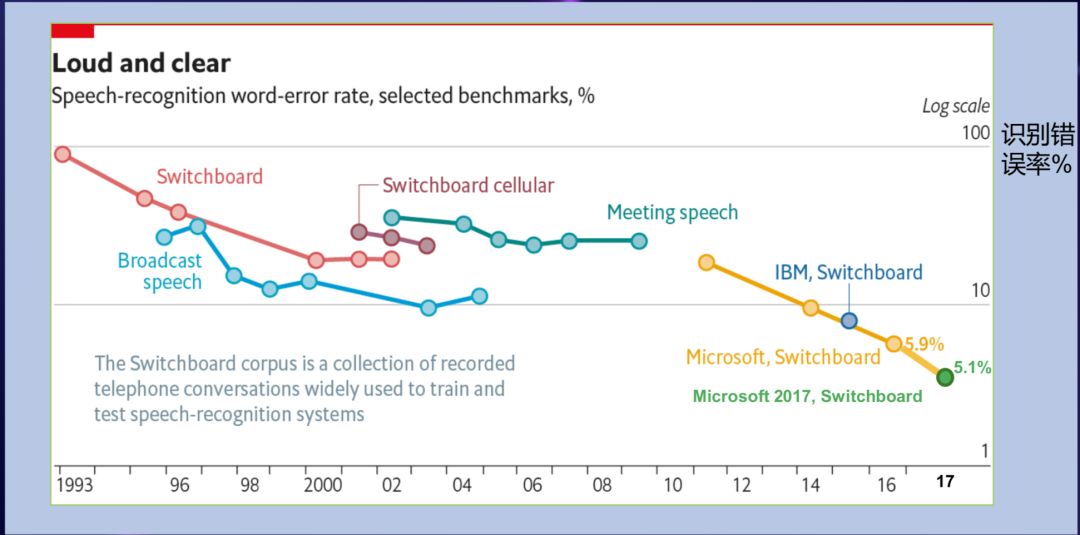
从 90 年代初到 2000 年,在 Swidthboard 这个很挑战的数据集上,语音识别的错误率在以倍数下降。但到了 2000 年左右,从 2000 年到 2010 年之间,尽管研究人员做了很多工作,比如说做区别性训练,自适应技术,迁移学习,但是始终没有得到一个特别好的突破,这十年大概可以认为语音识别的技术是比较停顿的,一直到 2010 年,微软研究院跟 Hinton 教授等合作将学术界的深度学习的思想和工业界场景及大规模的数据及处理能力等结合在一起,得到了很多新的突破。
2010 年底,深度学习在大规模语音识别核心问题上得到了突破,此后,语音识别错误率迅速往下降,一直最近在 switchboard 测试集上降到了 5% 左右。
在过去几年,我们见证了之前想象不到的一些技术的进步,比如语音翻译,在之前,我们认为语音翻译是基本不可能的问题,因为语音识别错误率就很高,翻译错误率也很高,但现在很多大厂都开始有了同传翻译的产品了,这都得益于深度学习的进展。
在过去几年,基于深度学习的进步,图像识别也取得极大的成功,比如在 2010 年,李飞飞教授提出的 ImageNet 数据库,定义了一个一千类的物体识别问题,但是在那时候,基于 SVM 等传统模型在这个测试集上的错误率超过 25%。
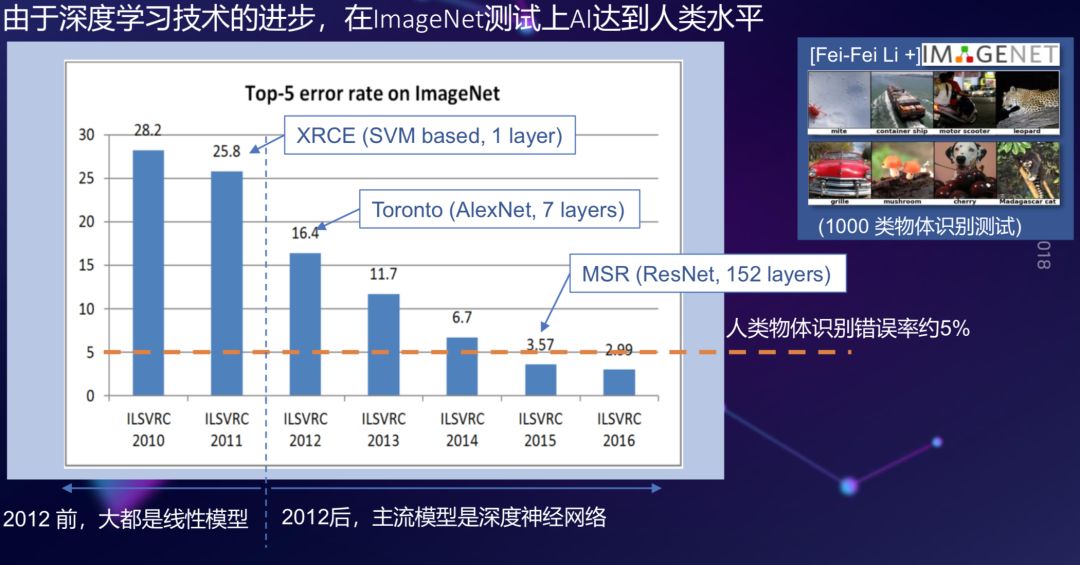
2012 年,Hinton 教授和他的学生提出用一个 7 层的深度卷积神经网络做这个任务,一下子把错误率从 25% 降到 16%,当时数据刚刚出来的时候,很多研究员都认为这个数据是不真实的,训练集和测试集在中间过程很可能被污染了,但经过仔细检查,发现这个数据就是真实的结果,而且,此后这个错误率每年又降了 30% 左右,持续到 2015 年,在这个数据集上的错误率降到了 3.57%,这是什么概念?让一个学生去做这个测试,一般人眼不会百分之百对,人往往会很多错误,人的错误率在 5% 左右,你可以认为,在 2015 年,基于深度学习的图像识别已经超过了人的水平。
下面我们说到自然语言处理,我个人认为 AI 突破最难的方向是自然语言理解,语言是人类特有的智能,我们知道,很多高等动物也能把视觉和听觉做得很好,但是语言智能却是人类独有的高级智能。
自然语言处理大概分为两类,一是让 AI 理解人类,人和人是通过自然语言交流的,我们希望 AI 系统能够理解我们的意图,解析我们的语义,甚至从文字中看到我们的情绪,能够做些推荐搜索上的工作。
另外一大类是让 AI 能被人类理解,也就是让计算机生成文本、生成对话,生成人能理解接受的内容,这是比理解内容更加难的问题。在过去几年,基于深度学习模型的进步,越来越多的工作放在了这方面,怎么样让 AI 能够生成人类的自然语言,比如说生成摘要,生成新的内容,生成崭新的话题,甚至生成带有情感的对话,在过去几年发展得非常快。
回顾这几年的发展之后,我想再展望一下未来几年 NLP 可能突破的一些方向。
我认为在以下几个方面:
多模态智能,综合文字、语音、图像、知识图谱等信息来获取智能;
复杂内容的创作,比如人工智能写作长文章;
情感智能,不只识别人的情感,还能像人一样表达情感和风格;
多轮人机对话,理解语境、常识、语言,生成逻辑严谨的有情感的对话服务于人。
下文中我们将用实例来解释这几点。

如果我们用深度学习来看上图,会生成这么一句话:一个棒球运动员在扔一个球。为什么会生成这么一句话?比如,我们发现模型“看”成这个图片的时候,它实际上先是注意力集中在棒球手套这个地方,这是一个特征表明这是一个棒球运动。随后当计算机注意到跟广的区域的时候,它会提出这是个运动员。再往下,当 AI 模型注意到一个大腿扭曲的姿态的时候,它会认为这是一个人的动作,凭这些,计算机会认为这是一个人扔球的动作,虽然这个球的占的整面积非常小,但是因为语言模型在语义上的驱动,使得这个球也能够被识别出来,最后形成一句完整的有意义的话。这就是跨越视觉和语言两个模态,从图片到文本描述生成的过程。
那么,是否可以反过来?说一句话,能不能生成一个图片?比如你想生成这么一句话:一只红羽毛白肚子的短咀小鸟,如果把这个作为输入,我们能不能生成相应的图片?答案是可以的。
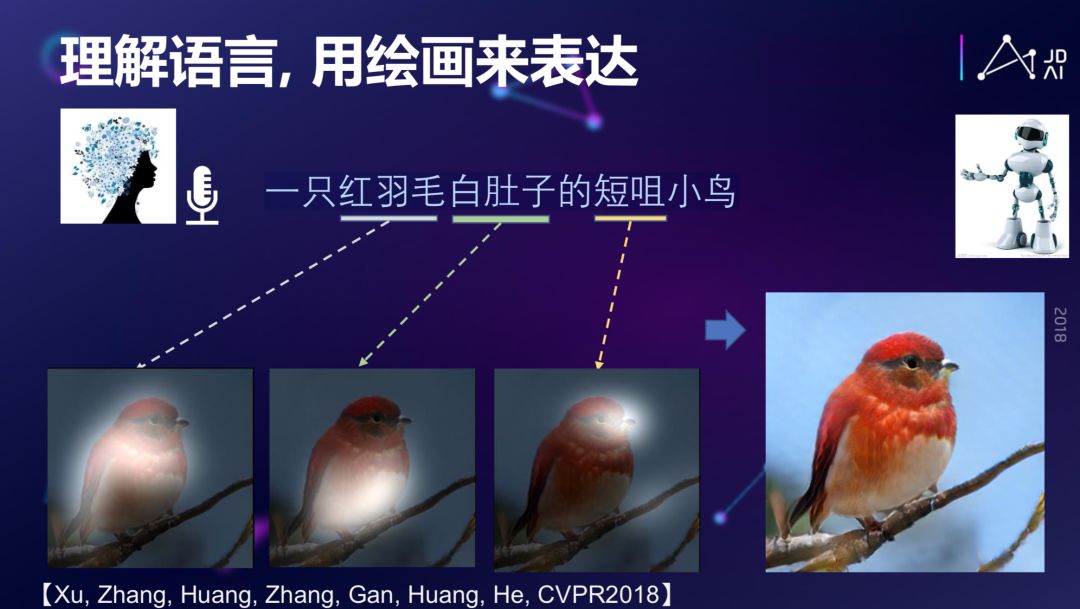
这是完全从无到有的生成,它创造了一个图像,这只鸟也许在这个世界上根本就不存在。这是最近发展很迅速的一个领域,也是语言和视觉跨模态的 AI 模型。当然,它也可以做更多其他的有趣的事情,我们在这里就不一一举例了。

上面是从图片到文字,文字到图片的实例,那么还有一种情况:在图片和文字之间做一些推理和综合问答。

如果你问 AI 系统,上图中两把蓝色的椅子之间是什么东西?最后它会告诉你,这是一把伞。模型的实现过程是:第一步,有一个 question model,先在语言上理解这个问题是什么,同时需要有一个 Image Model,对这个图片本身做一些理解,同时还有更重要的 multi-level attention model,就是负责在图片的信息和文字信息之间做多层 attention 的推理,最后得到这个答案,这称为视觉 - 语言多模态推理问答。
最新的多模态 AI 任务还包括语言和视觉多模态导航等。比如现实中的 Boston Dynamics 机器人能做后空翻、跑步。但我们希望它能进一步听懂你的要求,并按照你的要求在房间里走来走去,到指定的地方,这里面就用了一个视觉信号和语言理解联合的推理功能,这也是多模态智能的应用。
随着模型和数据越来越多,我们不再满足于 AI 模型只理解人类语言的意图,我们希望模型能够创作语言,比如怎么样创作一些很长的文章、诗歌等文学作品。此时,我们需要设计新的模型,比如现有的文本生成模型缺乏“规划”,我们应先产生初略的高层主题规划,然后再对主题和子主题展开成文。
人机对话本身其实是最难的,我个人认为人机对话是人工智能皇冠上的一颗明珠,也是最难的一颗明珠。
回到当年图灵提出图灵测试时候,他提到判断一个机器是不是有智能,可以通过人和机器之间的自然语言对话来做判断。从图灵在 60 多年前提出这个问题以来,人机对话发展到今天,其实已经发展出很多主流的对话框架来了。
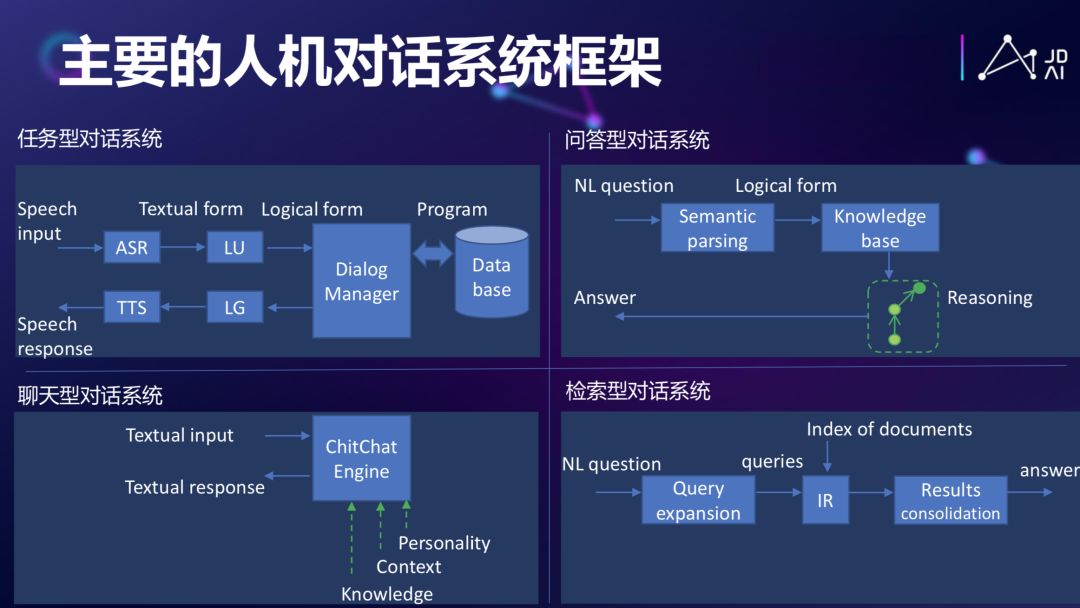
比如有任务型的对话系统、基于知识图谱的问答式对话、聊天型的机器人,如 Eliza、小冰,基于信息检索的系统,甚至可以认为百度本身就是一个对话系统,每次一输进去一个 Request,它会给你一个 document 作为它的 response。
去年年初的时候,我们在一篇《从Eliza到小冰,社交对话机器人的机遇和挑战》的论文里回顾了从最早的第一个对话机器人 Eliza 到现代的小冰的一些进展,认为机器人一方面要满足任务的需求,另一方面希望能够对人在情感方面的需求做一些满足。我们比较乐观,如果这个趋势走下去,也许随后几年我们会看到越来越多的机器人,不管是虚拟的还是实体的,这些机器人会成为我们生活的一部分。
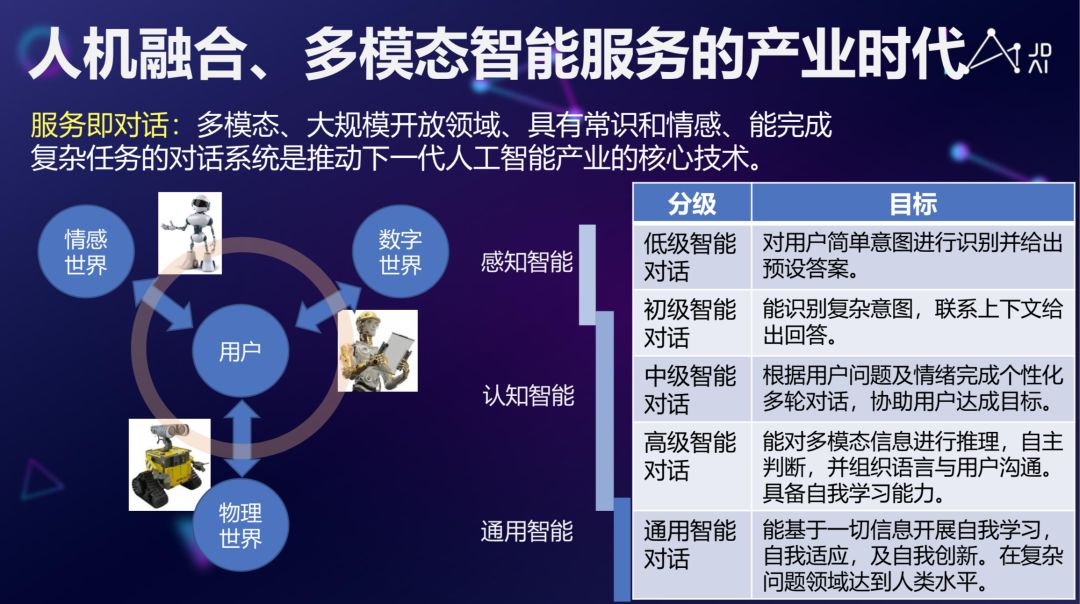
从 AI 角度来说,传统人力密集型产业具有广阔自动化、智能化的空间,但随着 AI 技术、IOT 技术的创新,各种各样的市场迅速成长,如 TOB 的市场、TO C 的市场,多模态技术、具有常识和情感、能完成复杂任务的智能人机交互技术在整个智能服务产业还是有很大的市场和机会的。
总的来说,随着 AI 技术的发展,特别是人机对话、文本生成、情感智能技术的提升,我们开始逐渐进入到人机融合、多模态智能的产业时代,通过大规模多模态交互与对话技术,我们能够对数字世界,比如银行帐号、各种各样的数字资产进行管理,甚至还能通过 AI 更好的在情感世界和物理世界进行沟通,希望随着人工智能尤其是 NLP 和其他多模态智能的发展,我们可以真正做到人机融合。
雷鸣:前段时间 OpenAI 推出的 NLP 模型 GPT 2.0 在业界引起了热议,它对 Transformer 模型参数进行扩容,参数规模达到了 15 亿,并使用更海量的数据进行训练,最终刷新了 7 大数据集基准,并且能在未经预训练的情况下,完成阅读理解、问答、机器翻译等多项不同的语言建模任务。作为 NLP 领域的专家,您怎么看待像 GPT 2.0 这样的暴力求解派?
何晓冬: 我个人对暴力美学并不反感,能解决问题就是进步,算法很重要,算法是整个工作的核心,但是光有算法还不够,还需很多迭代、学习,AI 跟产业界是紧密结合的,大量的数据,能支持大规模训练的算力,虽然听起来很简单暴力,但绝对是好事情,它把整个 AI 的技术门槛降低了。
另一方面,我想强调算法还是很重要,因为算法是灵魂,举个例子,为什么深度学习能起来?深度学习模型有足够的容量,使得效果能够起来,随着数据和算力的成长,深度算法模型能充分利用算力和数据带来的好处。如果是传统的线型模型,你就是给它再多的数据、GPU,线性模型也没办法 take the benefit,所以我认为算法是灵魂,但算力和数据是模型长大的物质基础。
雷鸣:那我们尝试把这个问题再往前推进探讨一下。业界可能会有一种说法是,模型越大、数据越多,可能效果就会越好。我们现在有了一个 15 亿参数的模型,如果未来我们有了 50 亿、100 亿的参数,会不会在一些方面上实现更多突破?如果能实现,会是在哪些方面?
何晓冬: 这是另外一个有趣的问题,随着任务越来越大,这个任务复杂度本身是组合爆炸式的。比如开始生成整个文章的时候,它的组合很多,你不可能看到所有的组合,换句话说,这个组合爆炸会超过计算机算力和数据的成长,所以我们一定要提出更加有效的算法,特别是 compositional 的算法,能处理这种组合性的算法,要有充分的解释性,有充分的模块化,才能真正解决爆炸式的问题,所以说只有 50 亿的模型还不够的,算法和底层的进步才能解决更高层次智能的问题。
雷鸣:在 AI 商业落地这块,您认为 AI 的哪些技术是可以落地?
何晓冬: 上文说的那些技术在很多场景都是可以落地的,比如评论理解,推荐、数据挖掘可以用来理解用户的偏好,给他推荐更合适的商品,这是很成熟的落地技术,再比如情感客服,我们不但要服务这个用户的需求,同时还能安抚情绪,让满意度得到提高。还有智能音箱,现在很多大厂要为什么亏钱做这件事情,因为智能音箱只是一个入口,重要的是它背后引入的服务。
雷鸣:对想学 AI 的语言学学生来说,您建议选择哪个方向?
何晓冬: 就 NLP 领域发展而言,语言学还是很重要的,语言是组合爆炸的问题,对语言结构理解之后,才能更游刃有余地处理这些问题,所以如果你对语言有更多的了解的话,那么它可以帮助你设计更好的符合这个语言特性的结构化模型,对你获得一个人工智能的职位是有益的。
图书推荐:

《Python深度学习》
原版豆瓣评分9.3,深度学习领域力作
Keras之父François Chollet著作
作者:弗朗索瓦•肖莱
译者:张亮(hysic)
本书详尽介绍了用 Python 和 Keras 进行深度学习的探索实践,包括计算机视觉、自然语言处理、产生式模型等应用,示例步骤讲解详细透彻。学习本书后,读者将具备搭建自己的深度学习环境、建立图像识别模型、生成图像和文字等能力。

《卷积神经网络的Python实现》
零基础学习深度学习,
基于NumPy的Python语言实现卷积神经网络
作者:单建华
本书用极少的数学知识,深入浅出地介绍了机器学习、卷积神经网络的相关概念以及实践中特别重要的数据预处理。首先简单介绍了机器学习的基本概念,详细讲解了线性模型、神经网络和卷积神经网络模型,然后介绍了基于梯度下降法的优化方法和梯度反向传播算法,接着介绍了训练网络前的准备工作、神经网络实战、卷积神经网络的应用及其发展。针对每个关键知识点,书中给出了基于NumPy 的代码实现,以及完整的神经网络和卷积神经网络代码实现,方便读者训练网络和查阅代码。
题图来源:Freepik.com
☟ 【阅读原文】查看深度学习书单





