一文解读聚类中的两种流行算法
原作:Anuja Nagpal
谢阳 编译自 Medium
量子位 出品 | 公众号 QbitAI
在这篇文章中,Nagpal以简明易懂的语言解释了无监督学习中的聚类(Clustering)问题,量子位将全文编译整理,与大家分享。
何为聚类?
“聚类”顾名思义,就是将相似样本聚合在一起,属于机器学习中的无监督学习问题。聚类的目标是找到相近的数据点,并将相近的数据点聚合在一起。
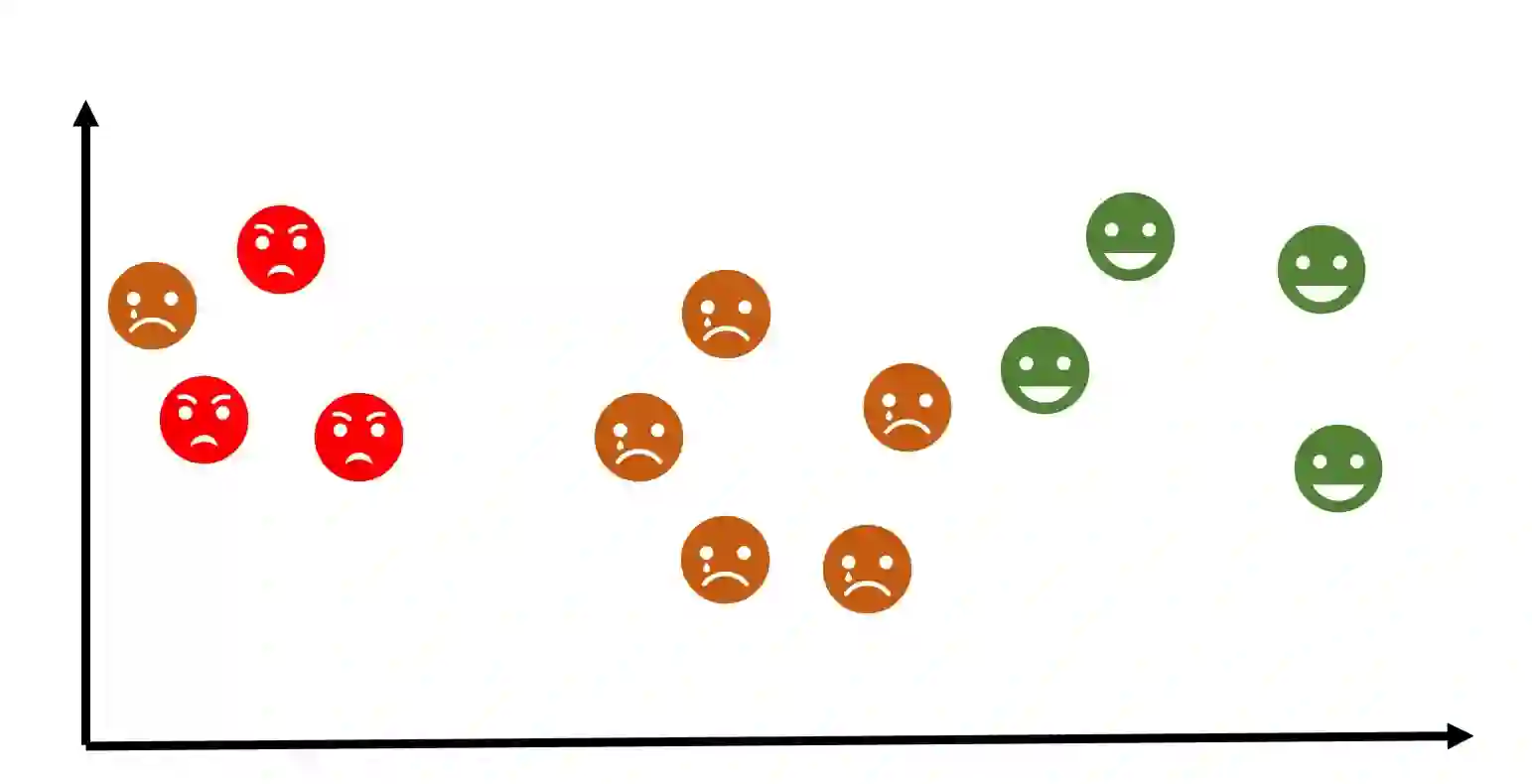
为什么选择聚类?
将相似的实体聚合有助于刻画不同类别的属性。换句话说,这将让我们深入了解不同类别的潜在模式。目前,有很多对未标记数据分类的应用,比如可以根据聚类将客户分为几类,之后对没类客户使用不同的算法使商家收益最大化。再比如,将相似话题的document分到一起。当数据维度较高时,可以采用聚类降维。
聚类算法是如何工作的?
有很多算法是为了实现聚类而开发的,我们挑出两个最流行且应用最广泛的两个来看看。
1.K-均值聚类算法
2.层次聚类
K-均值聚类
1.以你想要的簇的数量K作为输入,随机初始化每个簇的中心。
2.现在,在数据点和中心点的欧氏距离,将每个数据点分配给离它最近的簇。
3.将第二步中每个簇数据点的均值作为新的聚类中心。
4.重复步骤2和步骤3直到聚类中心不再发生变化。
你可能会问,如何在第一步中决定K值?
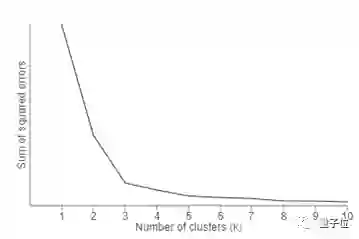
一种“肘部法则”(Elbow Method)可以用来确定最佳聚类数。你可以在K值范围内运行K-均值聚类,并在Y轴上绘制“可解释方差的比例”,在X轴上绘制K值。
在下面这张图片中可以注意到,当簇扩大到三个以上时,就不能对数据很好建模了。第一个簇增加了很多信息,但某些时候,边际收益将开始下降。
层次聚类
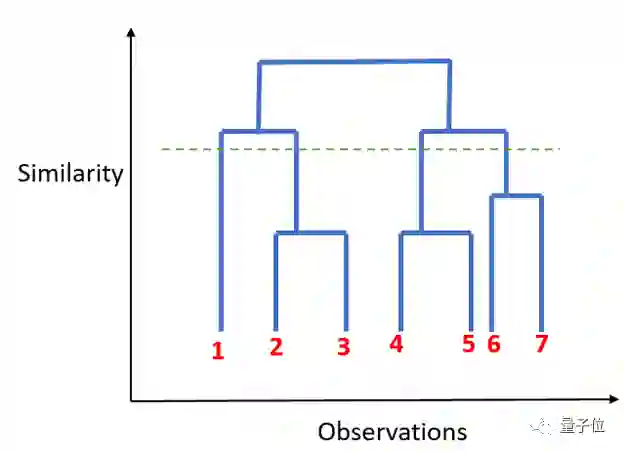
与K-均值聚类不同的是,层次聚类中每个数据点都属于一类。顾名思义,它构建层次结构,在下一步中,它将两个最近的数据点合并在一起,并将其合并到一个簇中。
1.将每个数据点分配给它自己的簇。
2.使用欧氏距离找到最接近的一组簇,并将它们合并为一个簇中。
3.计算两个最近的簇之间的距离,并结合起来,直到所有簇都聚集在一起。
K值的选取由下图中平行于X轴的虚线确定,从而确定最优簇数量。
总结下来,使用聚类算法时需要注意:
聚类需遵守一个原则,即每一类数据点的数量规模最好相差不大,因为计算距离很重要。
在形成簇之前处理特异值数据,因为它可以影响数据点之间的距离。
最后,附文章原文链接:
https://towardsdatascience.com/clustering-unsupervised-learning-788b215b074b
— 完 —
加入社群
量子位AI社群11群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




