【数学基础】机器学习中的几个熵
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要7分钟
跟随小博主,每天进步一丢丢


来自:天宏NLP
信息量
信息熵
相对熵(KL散度/KL divergence)
-
KL散度不对称, 。 -
KL散度不满足三角不等式。
交叉熵
几个熵之间的关系
JS散度
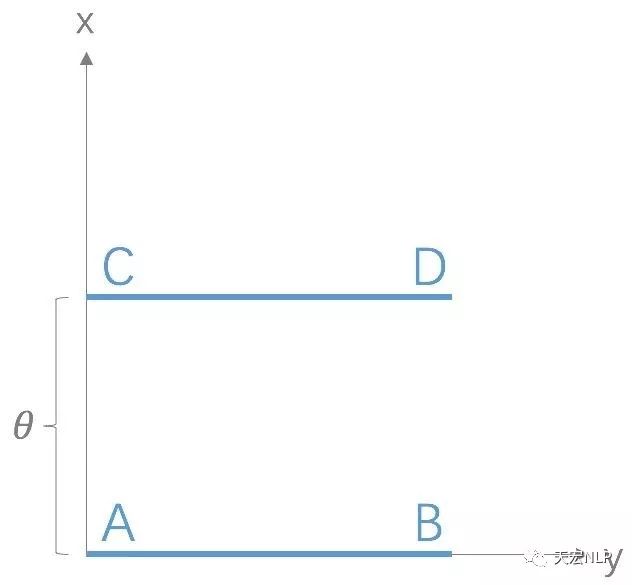
Wasserstein距离
总结
目前分类损失函数为何多用交叉熵,而不是KL散度?



登录查看更多
相关内容

专知会员服务
20+阅读 · 2020年1月7日
Arxiv
5+阅读 · 2018年8月6日



相关VIP内容
专知会员服务
20+阅读 · 2020年1月7日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年8月6日