「目标检测算法」连连看:从 Faster R-CNN 、 R-FCN 到 FPN

本文为雷锋字幕组编译的技术博客,原标题What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?,作者为Jonathan Hui。
翻译 | 唐青 李振 整理 | 凡江

在这个系列中,我们将对目标检测算法进行全面探讨。 第1部分,我们介绍常见的基于区域的目标检测器,包括Fast R-CNN,Faster R-CNN,R-FCN和FPN。 第2部分,我们介绍单步检测器(single shoot dectors, SSD)。第3部分,我们探讨算法性能和一些具体的例子。通过在相同的环境研究这些算法,我们研究哪些部分在其作用,哪些部分是重要的,可以在哪些部分进一步改进。希望通过对算法如何发展到今天的研究,会给我们未来的研究提供方向。
第1部分:我们从基于区域的目标检测器中学到了什么(Faster R-CNN,R-FCN,FPN)?
第2部分:我们从单步检测器中学到了什么(SSD,YOLO),FPN和Focal loss?
第3部分:目标检测的设计选型,经验教训和发展趋势?
滑动窗口检测器(Sliding-window detectors)
自从AlexNet赢得了2012年ILSVRC挑战的冠军,使用CNN进行分类成为领域的主导。一种用于目标检测的简单粗暴的方法是将滑动窗口从左到右,从上到下滑动使用分类来识别目标。为了区分在不同视觉距离下的目标类型,我们使用了不同尺寸和高宽比的窗口。

我们按照滑动窗口从图片中剪切出部分图像块。由于通常分类器都采用固定的图像大小,所以图像块需要进行形变。然而,这对分类精度并没有什么影响,应为分类器训练时也使用了形变的图像。

形变的图像块被送进CNN分类器中提取4096个特征。然后,我们用一个SVM分类器进行分类,用一个线性回归器得到边界框。
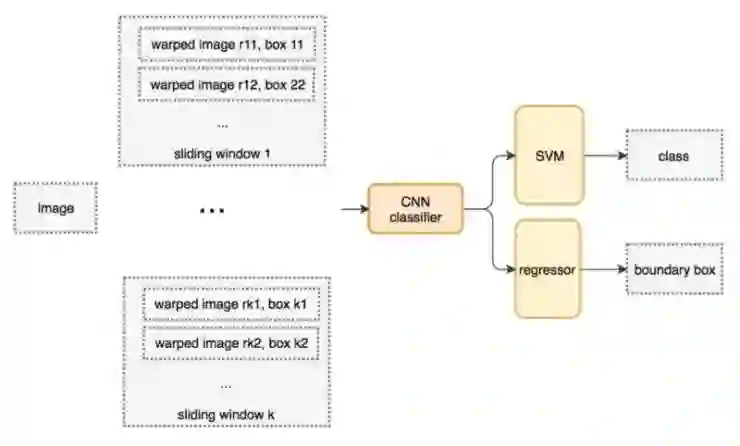
以下是伪代码。 我们生成了很多窗口来检测不同位置、不同形状的目标。 为了提高性能,减少窗口数量是一个显而易见的解决方案。

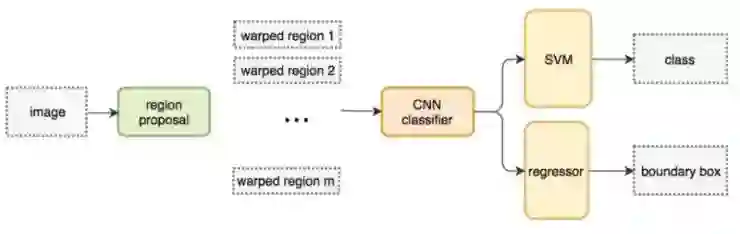
选择性搜索(Selective Search)
不再用简单粗暴的方法,我们用区域提议方法(region proposal method)生成感兴趣区域(regins of interest, ROIs)来进行目标检测。在选择性搜索算法(Selective Search, SS)中,我们让每个独立像素作为一个起始的组。然后,计算每个组的纹理,合并最接近的两个组。为了避免一个区域吞所有,我们优先合并较小的组。持续进行合并,直到所有可能合并的区域均完成合并。下图中,第一行展示了如何进行区域生长。第二行展示了在合并过程中所有可能的ROIs。

R-CNN
R-CNN利用区域提议方法(region proposal method)生成了约2000个感兴趣区域(regins of interest, ROIs)。这些图像块进行形变到固定的大小,分别送入到一个CNN网络中。然后,经过全连接层,进行目标分类和边界框提取。
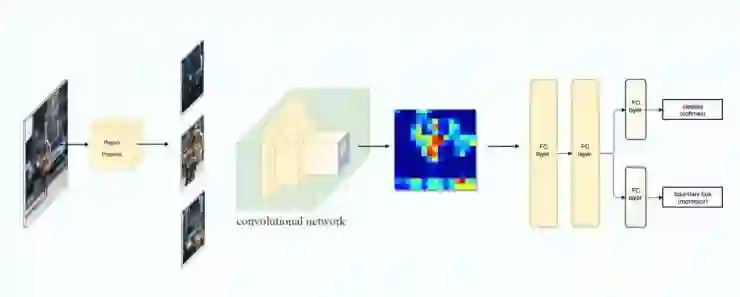
以下是系统的工作流。
利用数量更少,但质量更高的ROIs,R-CNN比滑动窗口的方法运行的更快、更准确。

边界框回归器(Boundary box regressor)
区域提议方法的计算量很大。为了加速这个过程,我们常采用一个简易版的区域提议网络来生成ROIs,然后,接线性回归器(使用全连接层)来提取边界框。

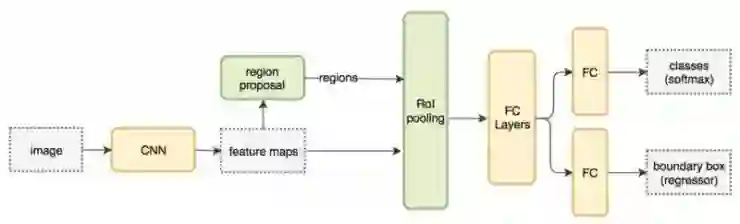
Fast R-CNN
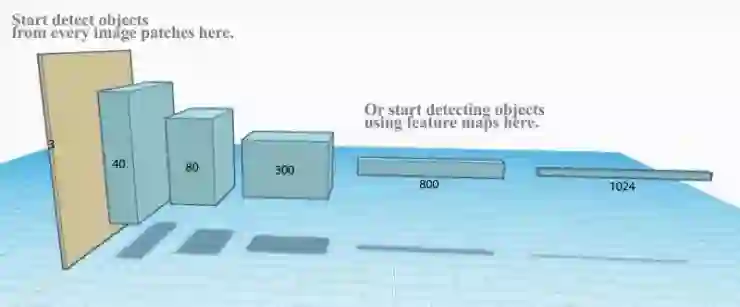
R-CNN需要足够多的提议区域才能保证准确度, 而很多区域是相互重叠的。R-CNN的训练和推理过程都很缓慢。例如,我们生成了2000个的区域提议,每个区域提议分别进入CNN。换句话说,我们对不同的ROIs重复了进行了2000次的提取特征。
CNN中的特征映射表达了一个更紧密的空间中的空间特征。我们能否利用这些特征映射来进行目标检测,而不是原始图像?

我们不再为每个图像块重新提取特征,而是在开始时采用一个特征提取器(一个CNN网络)为整个图像提取特征。然后,直接在特征映射上应用区域提议方法。例如,Fast R-CNN选择VGG16的卷积层conv5来生成待合并ROIs来进行目标检测,其中,包括了与相应特征的映射。我们利用ROI Pooling对图像块进行形变转换成固定大小,然后将其输入到全连接层进行分类和定位(检测出目标的位置)。由于不重复特征提取,Fast R-CNN显著的缩短了处理时间。
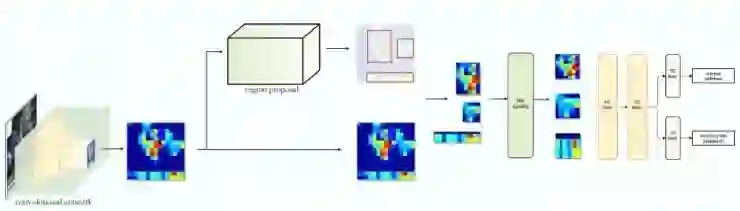
以下是网络工作流:
在下面的伪代码中,计算量很大的特征提取操作被移出了for循环。由于同时为2000个ROIs提取特征,速度有显著的提升。Fast R-CNN比R-CNN的训练速度快10倍,推理速度快150倍。

Fast R-CNN的一个主要特点是整个网络(特征提取器,分类器和边界框回归器)可以通过多任务损失multi-task losses(分类损失和定位损失)进行端到端的训练。这样的设计提高了准确性。
ROI Pooling
由于Fast R-CNN使用了全连接层,因此我们应用ROI Pooling将不同大小的ROIs转换为预定义大小形状。
举个例子,我们将8×8特征映射转换为预定义的2×2大小。
左上:特征映射图。
右上:ROI(蓝色)与特征映射图重叠。
左下:我们将ROI分成目标维度。 例如,我们的目标大小是2×2,我们将ROI分为4个大小相似或相等的部分。
右下:取每个部分的最大值,结果是特征映射转换后的结果。
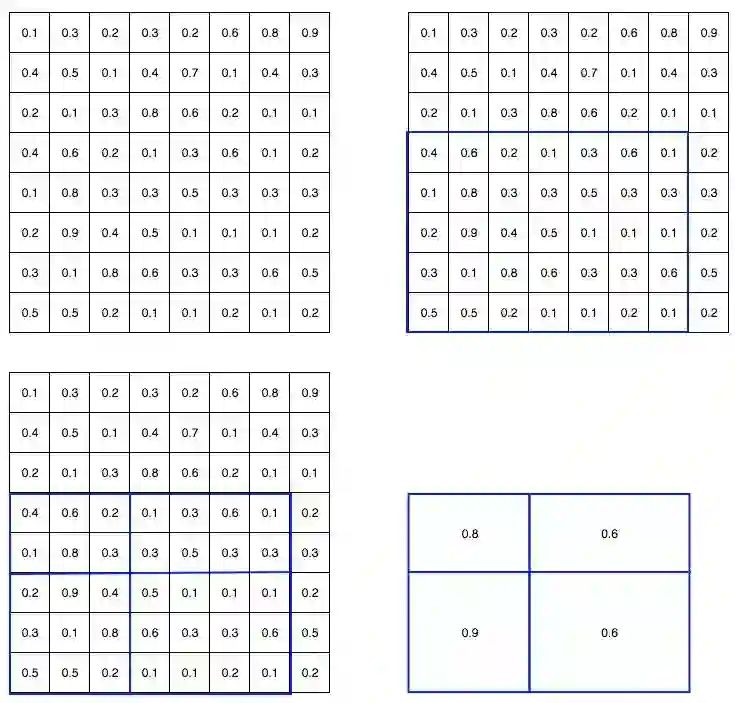
结果,得到了一个2×2的特征块,我们可以将它输入到分类器和边界框回归器中。
Faster R-CNN
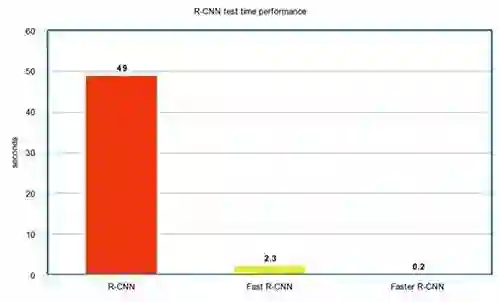
Fast R-CNN采用类似选择性搜索(Selective Search)这样额外的区域提议方法。 但是,这些算法在CPU上运行,且速度很慢。测试时,Fast R-CNN需要2.3秒进行预测,而其中2秒花费在生成2000个ROIs上。

Faster R-CNN采用与Fast R-CNN相似的设计,不同之处在于它通过内部深度网络取代区域提议方法。 新的区域提议网络(Region Proposal Network, RPN)效率更高。单副图像生成ROIs只需要10ms。
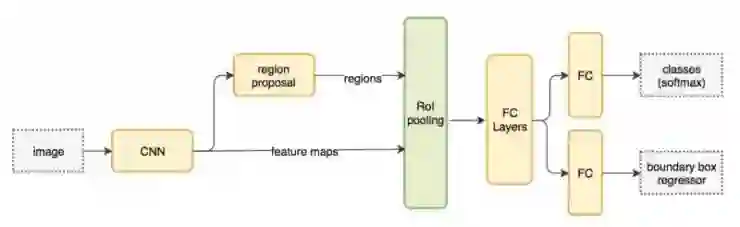
网络工作流。区域提议方法被新的卷积网络(RPN)取代。
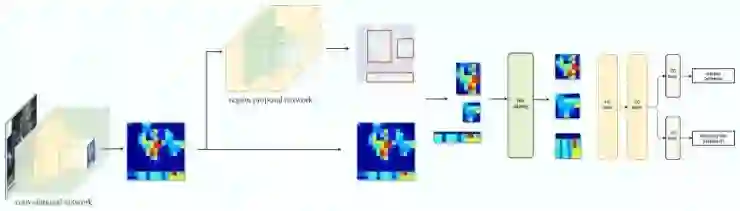
区域提议网络(Region proposal network)
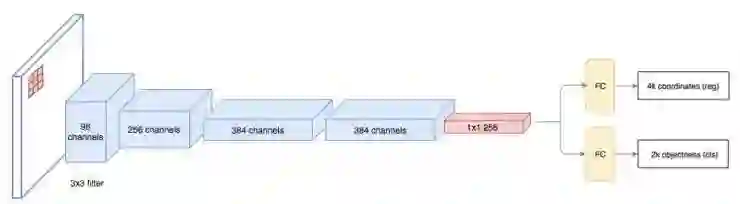
区域提议网络(RPN)用第一个卷积网络输出的特征图作为输入。在特征图上用3×3的滤波器进行滑动(滤波),采用诸如ZF网络(如下图)的卷积网络来得到未知类的建议区域。其他如VGG或者ResNet可以被用来提取更全面的特征,但需以速度为代价。ZF网络输出的256个值分别被送入两个不一样的全连接层来预测边界框和对象性分数(2 objectness score)。对象性描述了框内是否包含有一个物体。我们可以用回归器来计算单个物体的分数,但是为了简单起见,Faster R-CNN使用了一个分类器分类出两种可能的类别:“存在物体”类和“不存在物体/背景”类。
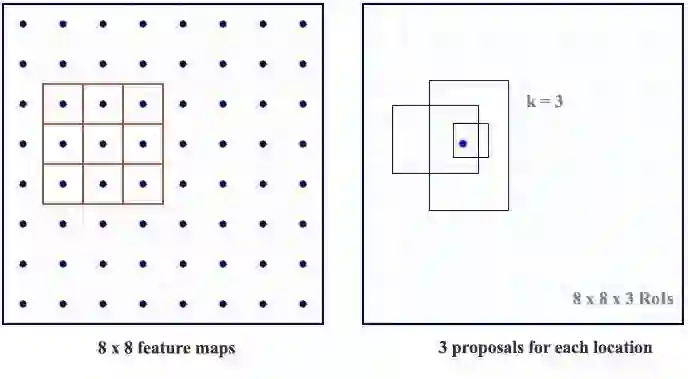
RPN对特征图里的每个位置(像素点)做了K次猜测。因此RPN在每个位置都输出4×k个坐标和2×k个分数。以下图例演示了一个使用3*3过滤器的8*8特征图,它一共输出8×8×3个兴趣区(ROI)(当k=3时)。右侧图例展示了在单个位置得到的3个提议区域。
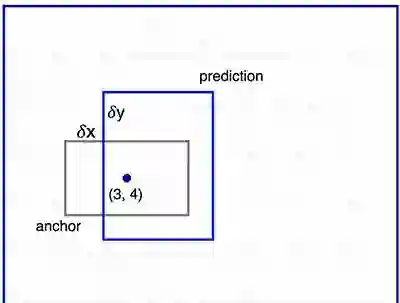
我们现在有3个猜测,随后我们也会逐渐改善我们的猜想。因为我们最终只需要一个正确的猜测,所以我们使用不同形状和大小的的初始猜测会更好。因此,Faster R-CNN不是随机的选择提议边界框。而是预测了相对于一些被称为锚的参考框的左上角的偏移量,比如 ?x, ?y 。因为我们约束了偏移量,所以我们的猜测仍然类似与锚。
为了对每个位置都进行k次预测,我们需要在每个位置中心放置k个锚。每次预测都和不同位置但是相同形状的特定锚相关。

这些锚都是精心预选好的,所以它们多种多样,同时非常合理的覆盖了不同尺度和不同长宽比的现实生活中的物体。这使了初始训练将具有更好的猜测,同时允许每次预测都有特定、不同的形状。这种方式使早期的训练更加稳定和容易。
Faster R-CNN使用了更多的锚。Faster R-CNN在一个位置上使用了9个锚: 3种不同尺度并使用三种长宽比。在每个位置使用9种锚,所以对于每个位置,它一共产生了2*9个对象性分数和4×9个坐标。
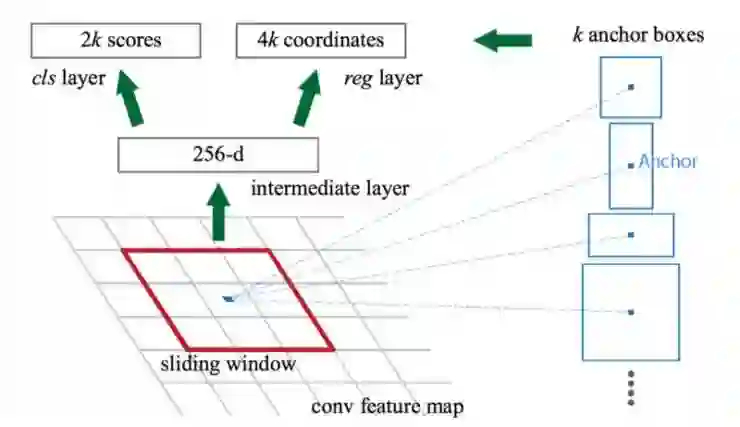
锚在不同的论文中也被称为先验或者默认边界框。
R-CNN的性能
如下图,Faster R-CNN要快得多。
基于区域的全卷积网络
假设我们只有一张特诊图用来检测脸上的右眼。我们是否可以用此来决定脸的位置呢?是可以的。因为右眼应该位于一张面部图像的左上角,我们也可以用此信息来确定脸的位置。

如果我们有另外的特诊图专门用来分别检测左眼,鼻子,嘴,我们可以将这些结果结合在一起使对脸部的定位更准确。
那为什么我们要如此麻烦呢?在Faster R-CNN里,检测器使用多个全连接层来做预测,有2000多个ROI,这消耗很高。

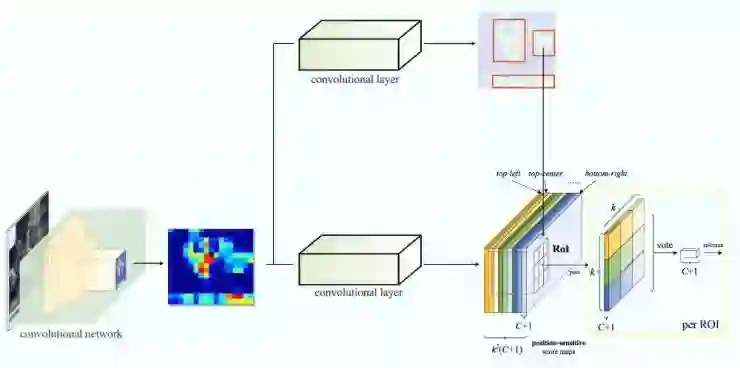
R-FCN通过减少每个ROI需要的工作总量来提高速度,以上基于区域的特诊图独立于ROIs,同时可以在每一个ROI的外部进行计算。接下来的工作就更简单了,因此R-FCN比Faster R-CNN要快。

我们可以想想一下这种情况,M是一个5*5大小,有一个蓝色的正方形物体在其中的特征图,我们将方形物体平均分割成3*3的区域。现在我们从M中创建一个新的特诊图并只用其来检测方形区域的左上角。这个新的特征图如下右图,只有黄色网格单元被激活。
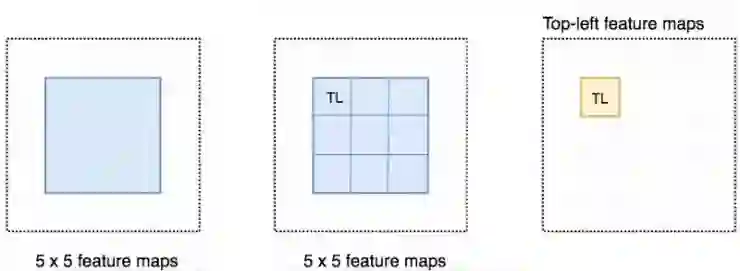
因为我们将方形分为了9个部分,我们可以创建9张特征图分别来检测对应的物体区域。因为每张图检测的是目标物体的子区域,所以这些特征图被称为位置敏感分数图(position-sensitive score maps)。
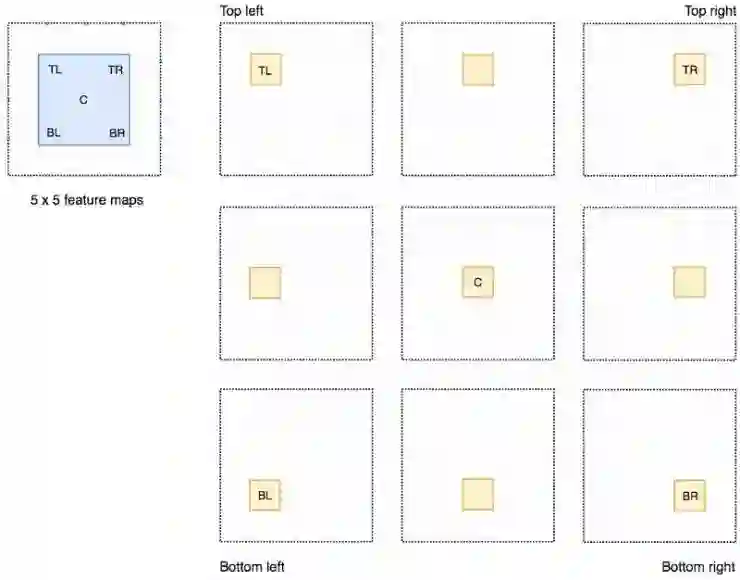
比如,我们可以说,下图由虚线所画的红色矩形是被提议的ROIs。我们将其分为3*3区域并得出每个区域可能包含其对应的物体部分的可能性。例如,ROIs的左上区域中存在左眼的可能性。我们将此结果储存在3*3的投票阵列(如下右图)中。比如,投票阵列[0][0]中数值的意义是在此找到方形目标左上区域的可能性。
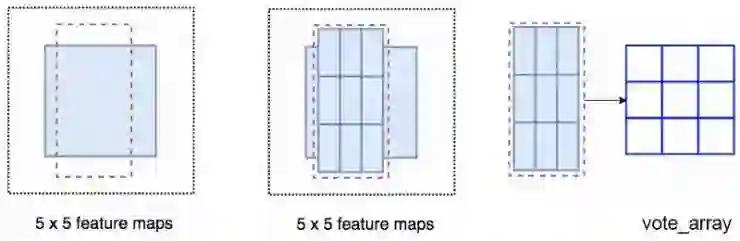
将分数图和ROIs映射到投票阵列的过程叫做位置敏感ROI池化(position-sensitive ROI-pool)。这个过程和我们之前提到的ROI pool非常相似。这里不会更深入的去讲解它,但是你可以参考以后的章节来获取更多信息。

在计算完位置敏感ROI池化所有的值之后,分类的得分就是所有它元素的平均值。
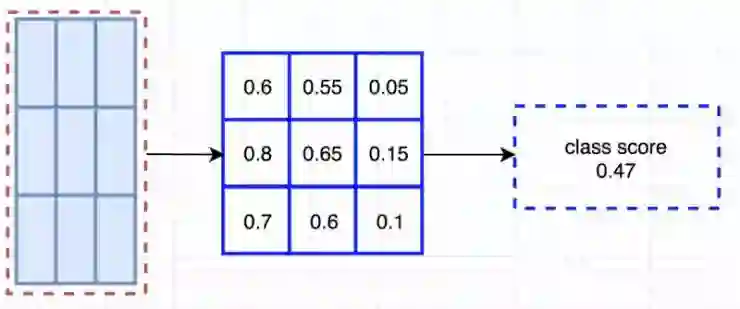
如果说我们有C类物体需要检测。我们将使用C+1个类,因为其中多包括了一个背景(无目标物体)类。每类都分别有一个3×3分数图,因此一共有(C+1)×3×3张分数图。通过使用自己类别的那组分数图,我们可以预测出每一类的分数。然后我们使用softmax来操作这些分数从而计算出每一类的概率。
接下来是数据流(图),比如我们的例子中,k=3。
至今为止我们的历程
我们从最基础的滑动窗口算法开始。

然后我们尝试减少窗口数,并尽可能的将可以移出for-loop的操作移出。

在第二部分里,我们更加完全的移除了for-loop。单次检测器(single shot detectors)使物体检测能一次性完成,而不需要额外的区域提议步骤。
RPN,R-FCN,Mask R-CNN的延伸阅读
FPN和R-FCN都要比我们在这里所描述的更加复杂,如果您想进一步学习,请参考如下:
https://medium.com/@jonathan_hui/understanding-feature-pyramid-networks-for-object-detection-fpn-45b227b9106c
https://medium.com/@jonathan_hui/understanding-region-based-fully-convolutional-networks-r-fcn-for-object-detection-828316f07c99
博客原址:
https://medium.com/@jonathan_hui/what-do-we-learn-from-region-based-object-detectors-faster-r-cnn-r-fcn-fpn-7e354377a7c9

从Python入门-如何成为AI工程师
BAT资深算法工程师独家研发课程
最贴近生活与工作的好玩实操项目
班级管理助学搭配专业的助教答疑
学以致用拿offer,学完即推荐就业

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
基于深度学习的目标检测算法综述
▼▼▼


