Facebook 提出了一个基于神经网络的反编译框架,可将汇编语言转换为 C++ 等高级语言,便于开发者阅读和查找漏洞。该方法的性能优于传统的基于启发式的反编译器。
当源代码不可用时,反编译是分析和理解软件的强大技术。它是计算机安全领域的一个关键问题。随着神经机器翻译(NMT)的成功,与传统的反编译方法相比,基于神经网络的反编译器的研究取得了很好的效果。
反编译器可以将低级可执行代码(如汇编语言)转换为高级编程语言(如 C++),使得代码可读性更强。这种反编译程序对于检测计算机安全中的漏洞、异常以及取证都很有用。反编译器也可以用来发现潜在电脑病毒、调试程序、翻译废弃的代码、恢复丢失的源代码等。
之前,反编译程序是受人类专家启发手工设计的。因此,对于每一对编程语言(如 C++ 和汇编),领域专家会编写大量的规则,这是一个耗时的过程,需要花费数年的时间,在棘手的情况下需要投入更多的注意力,进行更仔细的操作。源语言的升级,例如从 C++ 03 升级到 C++ 11,维护工作也随之升级。
针对上述问题,Facebook AI、UCSD STABLE 实验室提出了一个基于神经的反编译框架 N-Bref,该框架可以提高传统反编译系统的准确率。该研究对基于神经的反编译器设计的每个组件如何影响跨不同数据集配置的程序恢复的整体准确率进行了全面分析。
![]()
N-Bref 完成了从数据集生成到神经网络训练和评估的设计流程自动化,不需要人类工程师的参与
。在实际的代码反编译任务中,这是首个重利用 SOTA 神经网络(如神经机器翻译中用到的 Transformer)来处理高度结构化的输入和输出数据的尝试。N-Bref 可处理汇编代码,该汇编代码来自于对 C++ 程序的编译,这些程序经常调用标准库(例如 < string.h>,<math.h>),以及简单的类似 codebase 的解决方案。
![]()
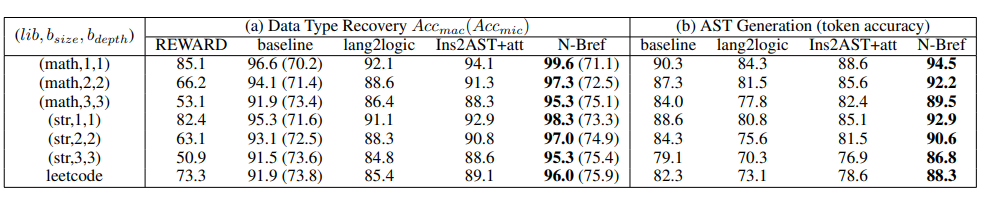
该表使用两个指标对 N-Bref 与之前方法的准确率进行比较:(a) 数据类型恢复;(b)AST 生成。Ins2AST 是基于神经的程序反编译器,没有使用 transformer;REWARD 是专家设计的类型恢复工具;Lang2logic 是序列到树的转换器。基线是只用一般 transformer 得到的结果。
N-Bref 的性能优于传统的反编译器 (如:REWARD [2]),尤其是输入程序很长且有复杂的控制流时。值得注意的是,该系统可以从标准 C 库 (e.g., <math.h>, <string.h>) 反编译真实的 C 代码以及人类为解决实际问题而编写的基础代码库。该研究对基于神经的反编译器设计的每个组件,如何影响跨不同数据集设置的程序恢复的总体准确率进行了全面的分析。
N-Bref 自动完成了从数据集生成到神经网络训练再到评估的设计流程。
首先,研究人员将输入汇编代码编码到图结构中,以便更好地表示不同指令之间的关系。
然后,使用现有的图嵌入工具 (GraphSage [1]) 对图结构进行编码,以获得汇编代码的表示。为了构建并迭代优化抽象语法树 (AST),对高级语义进行编码,研究人员使用内存增强 transformer 来处理高度结构化的汇编代码。
最后,研究人员将 AST 树转换为真实的高级语义语言,如 C。
为了收集训练数据,该研究还提供了一个生成和统一高级编程语言表示的工具,用于神经反编译器的研究。
![]()
据了解,这是端到端可训练代码反编译系统首次在广泛使用的编程语言(如 C++)中表现优越。这一进步使得该领域在可用于大型代码库的实际反编译系统上又前进了一步。研究团队还开发了第一个数据集生成工具,用于基于神经的反编译器开发和测试,生成的代码接近于人类程序员编写的代码,该工具同样适用于开发基于学习的方法。
https://ai.facebook.com/blog/introducing-n-bref-a-neural-based-decompiler-framework/
https://www.marktechpost.com/2021/01/28/facebook-ai-introduces-n-bref-a-neural-based-decompiler-framework/
报告内容涵盖人工智能顶会趋势分析、整体技术趋势发展结论、六大细分领域(自然语言处理、计算机视觉、机器人与自动化技术、机器学习、智能基础设施、数据智能技术、前沿智能技术)技术发展趋势数据与问卷结论详解,最后附有六大技术领域5年突破事件、Synced Indicator 完整数据。
识别下方二维码,立即购买报告。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com