各种NLP操作难实现?谷歌开源序列建模框架Lingvo
机器之心编译
机器之心编辑部
自然语言处理在过去一年取得了很大进步,但直接关注 NLP 或序列建模的框架还很少。本文介绍了谷歌开源的 Lingvo,它是一种建立在 TensorFlow 上的序列建模框架。该框架重点关注协作实现与共享代码库,能极大提升代码复用与研究迭代速度,NLP 的今年就靠你了~
Lingvo 是世界语(Esperanto)中的一个单词,它表示「语言」的意思。这一命名展示了 Lingvo 框架的根源:它是由 TensorFlow 开发的通用深度学习框架,它重点关注自然语言处理相关的序列建模方法,包括机器翻译、语音识别和语音合成等。
项目地址:https://github.com/tensorflow/lingvo
在谷歌内部,Lingvo 框架非常有吸引力,使用它的研究人员越来越多。目前,有数十篇获得 SOTA 结果的论文都通过 Lingvo 框架得到了最优的复现,当然开源后将会有越来越多的新实现。从传统的 RNN 序列模型到目前流行的 Transformer,再到包含变分自编码器模块的前沿模型,Lingvo 支持的序列建模架构非常多。
为了支持研究社区并鼓励复现研究论文,谷歌开源了这项框架。他们表示以后谷歌发布的一些序列建模新研究也会尝试采用 Lingvo 框架,它的便捷性将提升 NLP 研究的速度。
Lingvo 主要支持大量研究团体在一个共享代码库中从事语音和自然语言处理相关问题的研究。它的设计原则如下:
单个代码块应该精细且模块化,它们会使用相同的接口,同时也容易扩展;
实验应该是共享的、可比较的、可复现的、可理解的和正确的;
性能应该可以高效地扩展到生产规模的数据集,或拥有数百个加速器的分布式训练系统;
当模型从研究转向产品时应该尽可能共享代码。
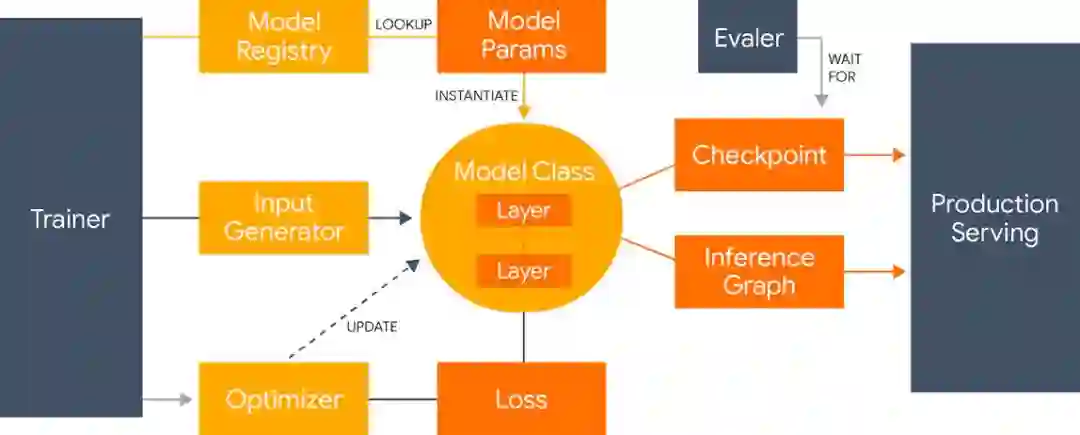
图 1:Lingvo 框架整体结构,它展示了模型如何进行实例化、训练、评估和部署。
Lingvo 是在考虑协作研究的基础上构建的,它主要通过在不同任务之间共享公共层的实现,从而提升代码的复用程度。此外,所有层都实现了相同的公共接口,并以相同的方式布局代码结构。这不仅会产生更简洁和易读的代码,同时其它任务上的改良也可以便捷地应用到我们的任务上。实现这种一致性代码确实会有更多的成本,例如更加规范和模板化的代码。但是 Lingvo 也在尝试减少这种成本,以确保更快地迭代研究成果。
协作的另一个方面是共享可复现的结果。Lingvo 为检查模型超参数配置提供了集中的地址,这不仅可以记录重要的实验,同时通过训练相同的模型,其它研究者可以更轻松地复现我们的研究成果。
def Task(cls):
p = model.AsrModel.Params()
p.name = 'librispeech'
# Initialize encoder params.
ep = p.encoder
# Data consists 240 dimensional frames (80 x 3 frames), which we
# re-interpret as individual 80 dimensional frames. See also,
# LibrispeechCommonAsrInputParams.
ep.input_shape = [None, None, 80, 1]
ep.lstm_cell_size = 1024
ep.num_lstm_layers = 4
ep.conv_filter_shapes = [(3, 3, 1, 32), (3, 3, 32, 32)]
ep.conv_filter_strides = [(2, 2), (2, 2)]
ep.cnn_tpl.params_init = py_utils.WeightInit.Gaussian(0.001)
# Disable conv LSTM layers.
ep.num_conv_lstm_layers = 0
# Initialize decoder params.
dp = p.decoder
dp.rnn_cell_dim = 1024
dp.rnn_layers = 2
dp.source_dim = 2048
# Use functional while based unrolling.
dp.use_while_loop_based_unrolling = False
tp = p.train
tp.learning_rate = 2.5e-4
tp.lr_schedule = lr_schedule.ContinuousLearningRateSchedule.Params().Set(
start_step=50000, half_life_steps=100000, min=0.01)
# Setting p.eval.samples_per_summary to a large value ensures that dev,
# devother, test, testother are evaluated completely (since num_samples for
# each of these sets is less than 5000), while train summaries will be
# computed on 5000 examples.
p.eval.samples_per_summary = 5000
p.eval.decoder_samples_per_summary = 0
# Use variational weight noise to prevent overfitting.
p.vn.global_vn = True
p.train.vn_std = 0.075
p.train.vn_start_step = 20000
return p
代码1:Lingvo 中的任务配置示例。每个实验的超参数都是在其所属的类中配置的,与构建网络和检查版本控制的代码不同。
虽然 Lingvo 一开始重点关注 NLP,但它本质上非常灵活。用于图像分割和点云分类任务的模型已经使用该框架成功实现。它还支持知识蒸馏、GAN 和多任务模型。同时,该框架没有因为便捷而牺牲速度,它具有优化的输入流程和快速的分布式训练。最后,Lingvo 还着眼于生产化,甚至有一条明确的路径来将模型移植到移动端。
论文:Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
论文地址:https://arxiv.org/abs/1902.08295
摘要:Lingvo 是一个能够为协作式深度学习研究提供完整解决方案的 Tensorflow 框架,尤其关注序列到序列模型。Lingvo 模型由模块化构件组成,这些构件灵活且易于扩展,实验配置集中且可定制。分布式训练和量化推理直接在框架内得到支持,框架内包含大量 utilities、辅助函数和最新研究思想的现有实现。过去两年里,Lingvo 已被数十个研究人员在 20 篇论文中协作使用。本文作为对框架各个部分的介绍,概述了 Lingvo 的基本设计,同时还提供了展示框架能力的高级功能示例。

参考链接:https://medium.com/tensorflow/lingvo-a-tensorflow-framework-for-sequence-modeling-8b1d6ffba5bb
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




