论文浅尝 | DeCLUTR: 无监督文本表示的深度对比学习

Giorgi, J. M., O. Nitski, G. D. Bader and B. Wang (2020). "DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations." arXiv preprint arXiv:2006.03659.
原文链接:https://arxiv.org/pdf/2006.03659
GitHub项目地址:
https://github.com/JohnGiorgi/DeCLUTR
本文提出了一个简单并且易于实现的不对模型敏感的深度学习指标,并且该学习方法不需要任何标注的数据,损失函数为对比学习的损失函数加上MLM的损失函数。本文主要关注于对比学习在句子层面表征的应用。最近,受到CV领域的对比学习框架启发,本文提出了一个类似于BYOL利用正样本进行对比学习的NLP领域应用。这里注意的是编码器是共享权重,并非权值更新。
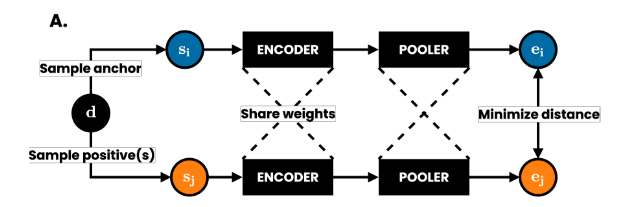
模型的流程如下:
1. 先从无标注的文档中以beta分布中抽样anchor片段,在从这一篇相同的文档以不同的beta分布抽样出positive样本对。
2. 之后分别将anchor片段

3. 再将token embedding进行pooler操作,即将所有的token embedding平均生成同一维度的sentence embedding。
4. 计算对比学习的损失函数。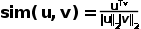
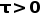
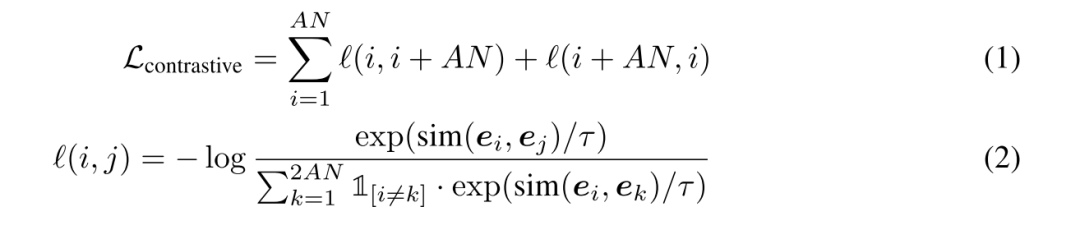
5. 在计算出对比学习的loss之后,再加入MLM的loss,对模型进行反向梯度传播更新参数。
数据集:OpenWebText corpus,有495243个至少长度为2048的文档。
SentEval:含有28个测试数据集,氛围Downstream和Probing。Downstream使用模型编码出的句子嵌入来作为分类器的feature进行分类,而Probing评估模型生成的句子嵌入所还有的语义信息,比如预测动词的时态等。
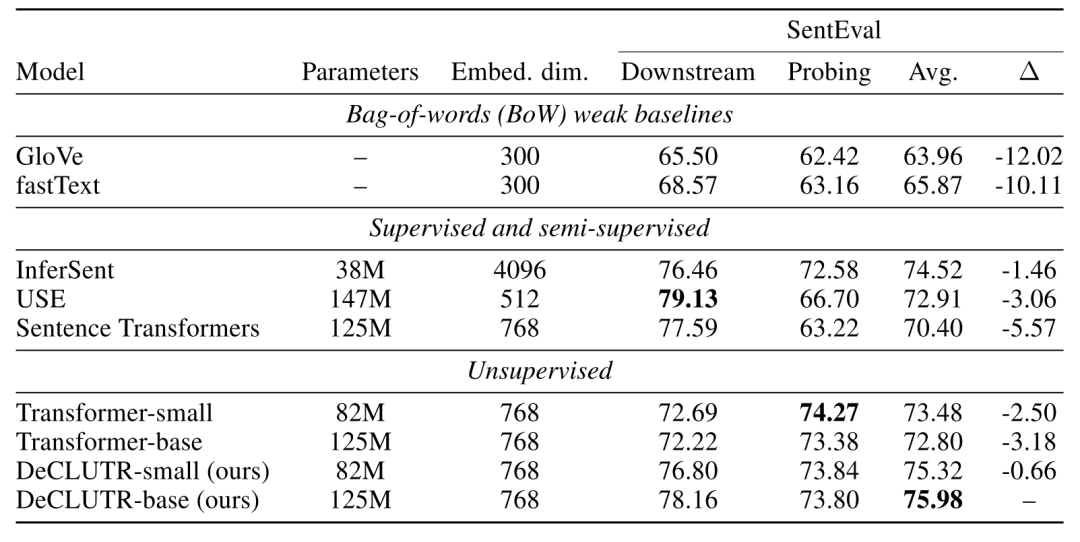
总而言之,本文提出了一种利用对比学习来帮助模型更好地学习句子层面的表征。并且本文的方法十分简单且易于实现,适用于很多模型。实验也表明对比学习在NLP领域句子表征层面上的可行性。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



