IROS 2021 | PTT:把Transformer应用到3D点云目标跟踪任务
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
PTT: Point-Track-Transformer Module for 3D Single Object Tracking in Point Clouds

论文已于今年六月份中稿机器人领域顶会IROS 2021。
论文地址:https://arxiv.org/abs/2108.06455
作者单位:东北大学(沈阳)
代码整理中,即将开源:
https://github.com/shanjiayao/PTT
实验视频链接:
bilibili: https://www.bilibili.com/video/BV1Uf4y157UE/
YouTube:https://www.youtube.com/watch?v=lttRtYXxUic
主要贡献:
一个针对基于点云三维单目标跟踪的Point-Track-Transformer (PTT)模块,可以在追踪过程中有效权衡点云特征以聚焦于更深层次的目标线索。
一个嵌入了PTT组件的PTT-NET网络,可进行端到端的训练。这是第一个基于点云应用transformer到三维目标跟踪任务的方法。(截止投稿时)
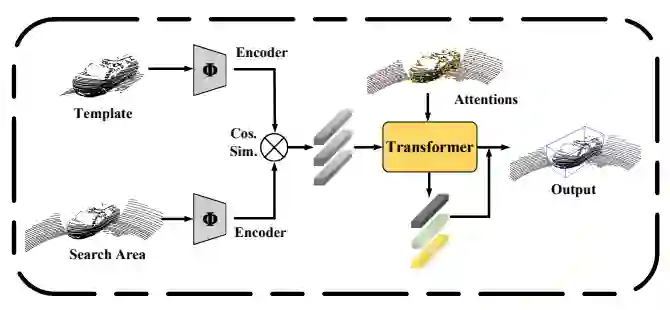
图1: 与现有的三维单目标跟踪方法相比,我们的PTT模块在计算相似度特征后根据特征的重要性对特征进行加权,以提高跟踪器的性能。
摘要:
三维单目标跟踪是机器人技术中的一个关键问题。本文提出了一种基于点云的三维单目标跟踪的transformer 模块:Point-Track-Transformer (PTT)。PTT模块包含特征嵌入、位置编码和自注意力三个模块特征计算。特征嵌入旨在将语义信息相似的特征在嵌入空间中放置得更近。位置编码用于将原始点云坐标编码为高维可分辨特征。自注意通过计算注意权重产生更细化的注意力特征。此外,我们将PTT模块嵌入到开源方法P2B中来构建PTT-NET。在KITTI数据集上的实验表明,我们的PTT-Net显著的超越了现有的基于点云的单目标跟踪方法(涨了10个点)。此外,PTT-Net还可以在 1080Ti GPU上实现实时性能(40fps)。我们的代码是面向机器人社区的开源代码,网址是https:https://github.com/shanjiayao/PTT。
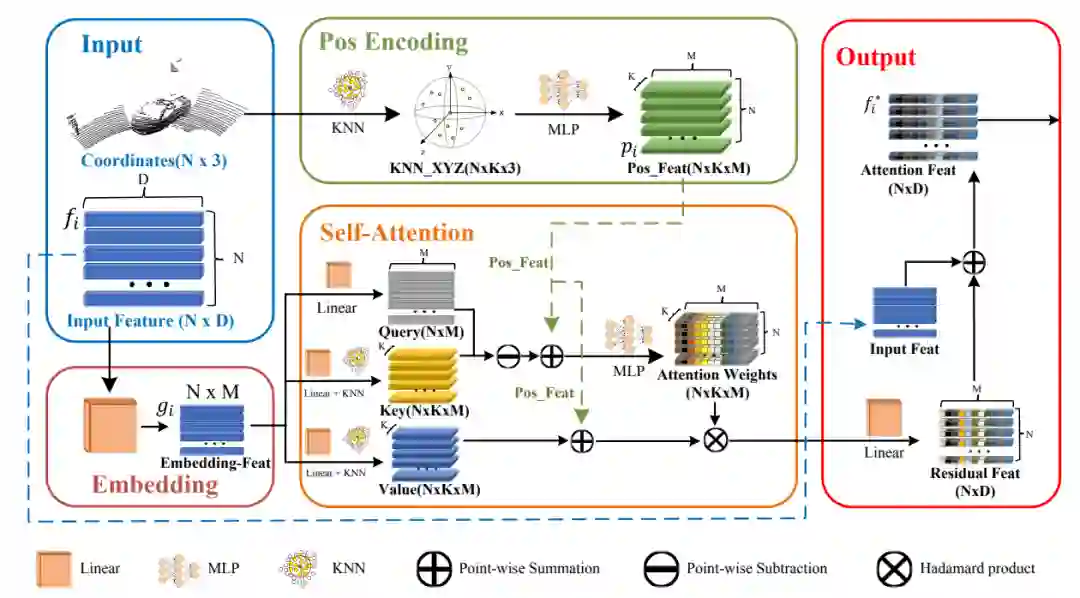
图2: PTT组件结构示意图
方法:
特征嵌入:该工作采用线性层完成特征嵌入操作,对输入点云特征进行映射;将点云特征从D维映射到M维,用于将语义信息相似的特征在嵌入空间中放置得更近。
位置编码:由于三维点云坐标本身自带位置属性,就是位置编码的自然输入。因此,我们直接利用输入的点云坐标作为位置编码模块的输入。此外,我们利用相对坐标使网络更好地捕捉点与点之间的空间相关性和局部几何形状信息。
自注意力:自注意力部分,我们采用vector attention的结构来计算对输入特征进行加权。公式如下:

PTT-Net:
为了证明我们的PTT组件的有效性,我们将我们的PTT组件嵌入到开源工作P2B中,构建了我们的PTT-Net网络。我们分别将PTT组件加在P2B网络的种子投票阶段和提议框生成阶段。具体如下图所示:
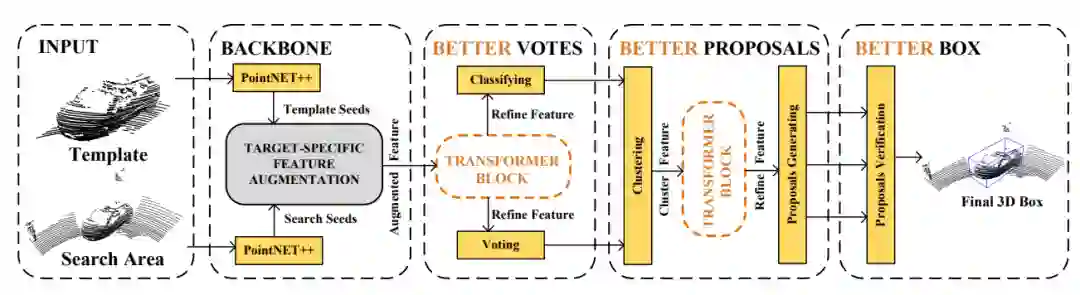
图3: PTT-Net网络结构示意图
定量实验结果:
表1:KITTI数据集上车辆类别跟踪结果
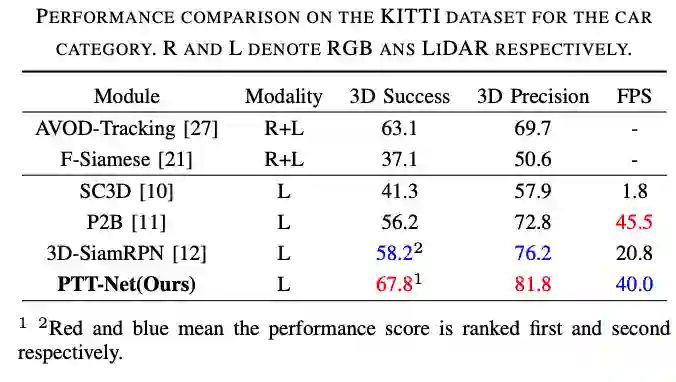
相较于baseline方法,涨了10个点。
定性实验结果:
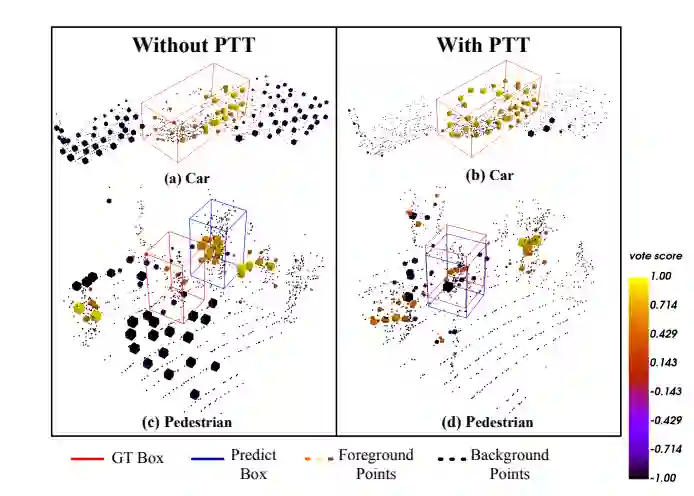
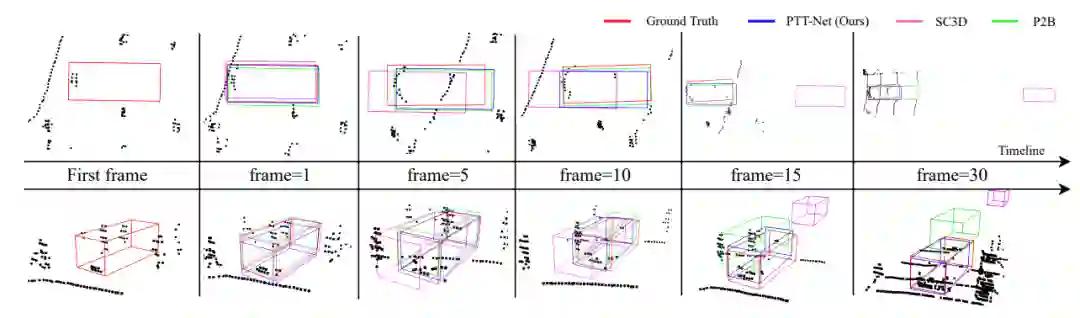
加入PTT组件后,算法在点云稀疏场景下,跟踪性能有显著提升。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号





