学界 | 如何用未标注样本解决单标注样本下的视频行人重识别问题?

AI 科技评论按:本文作者为悉尼科技大学博士生武宇(Yu Wu),他根据 CVPR 2018 录用论文 Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning 为 AI 科技评论撰写了独家解读稿件。
在这篇论文中,我们提出了通过逐渐利用未标注样本,来解决单标注样本(one-shot)情况下的视频行人重识别问题(video-based person re-ID)。这个方法很简单通用,在两个大型的视频行人重识别数据集上都达到了远超 state-of-the-art 的性能。
1. 为什么需要单标注样本问题?
目前大多行人重识别方法都依赖于完全的数据标注,即需要对每个训练集里的人在不同摄像头下的数据进行标注。然而对于实际的监控场景,如一个城市的监控视频来说,从多个摄像头里手工标注每段视频的行人标签的代价很大。因此我们尝试去只用单标注样本,让网络自己去学会利用那些未标注的样本。也就是说对于每个行人,我们只需要标注其中一段视频,其余的视频通过算法自己去探索。
对于这个任务,典型的做法是为未标注数据估计一个标签,然后用初始的标注数据和部分选定的带有假定标签 (pseudo-label) 的数据用来训练模型。
然而因为只用初始标注数据训练出来的模型性能太弱,可信的 pseudo-labeled 数据是很少的,这样选择数据注定会引入很多错误的训练样本。所以我们提出了 EUG(Exploit the Unknown Gradually)方法,迭代地去预测标签和更新模型,这样一步步地利用未标注数据。
另外,我们发现直接用分类器预测出来的标签是不可靠的,我们提出通过特征空间里面的最近邻 (Nearest neighbor) 分类方式,去给每个未标注数据分配 pseudo label。
2. 如何去利用未标注样本

如图,我们一开始用有标注的数据来初始化训练 CNN 模型,之后在每一次循环中我们(1)挑选可信的 pseudo-labeled 数据 2. 用标注数据和 pseudo-labeled 数据一起来更新 CNN 模型。我们通过逐步增大每次加入训练的 pseudo-labeled 数据量,从而逐渐去利用更难识别的,包含更多信息多样性的视频片段。
这里有两个值得注意的点:
(1)如何决定每次选取多少 pseudo-labeled 数据做训练
我们用一种动态测量,逐渐增加选取的样本。在开始的循环中,只有一小部分 pseudo-labeled 数据被选中,之后会有越来越多样本被加进来。我们发现增加样本容量的速度越慢,即每一步迭代比上一步增加的 pseudo-labeled 样本越少(对应需要的迭代次数更多),模型的性能越高。pseudo-labeled 样本量的增长速度对模型最终性能的影响十分显著。
(2)如何去给一个未标注数据分配 pseudo label 并量化其可信程度?
跟之前大部分 re-ID 的方法一样,我们的训练时采用的也是一个行人分类网络,因此对于未标注样本,网络分类的预测值(Classification score)是可以用来预测标签并判断标签置信度的。但是这样的分类层在样本量很少,特别是我们这种每个类只有一个样本的情况下的情况下是不太可靠的。
同时我们注意到行人重识别(re-ID)的测试过程是一个计算特征之间距离并进行检索的过程,所以我们从这个角度出发,也去计算未标注数据与标注数据之间的距离(Dissimilarity cost criterion)。对于每个未标注的样本,我们把离它最近的有标注样本的类别赋予它作为 pseudo label,并且将他们之间的距离作为标签估计的置信度,如下图所示。
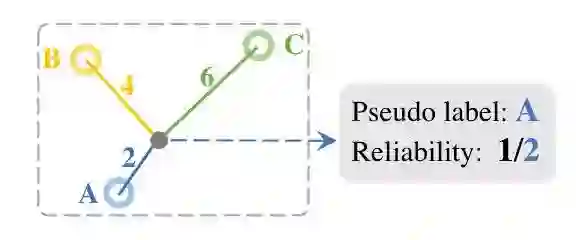
我们发现,这种用距离度量的方式选出来的 pseudo-labeled 数据要比分类层的预测要可靠很多。
3. 算法实际选出来的样本如何?
我们的方法在 MARS 和 DukeMTMC-VideoReID 这两个大规模的视频行人重识别数据集上都取得了极大的提高。下面我们展示一下算法选出来的 pseudo-labeled 样本。

这是一个算法运行时为左边这个行人选出来的 pseudo-labeled 样本,可以看到在第 0 次迭代时返回的样本都是和初始化视频很相似的正确数据。算法在第 1 次和第 2 次迭代时候开始返回了不同视角的正确数据,在第 5 到 7 次迭代时候返回了更难以分辨的正确样本(完全不同的视角、遮挡和严重摄像头色差)以及部分错误样本。没有被找到的这个视频片段几乎是全黑的。
Pytorch 代码实现参见:
https://github.com/Yu-Wu/Exploit-Unknown-Gradually
DukeMTMC-VideoReID 数据集介绍和 Baseline 代码:
https://github.com/Yu-Wu/DukeMTMC-VideoReID



