谷歌发布含 7 种语言的全新数据集:有效提升 BERT 等多语言模型任务精度高达 3 倍!

作者 | Yuan Zhang and Yinfei Yang
编辑 | 杨鲤萍
排版 | 唐里
原文标题:Releasing PAWS and PAWS-X: Two New Datasets to Improve Natural Language Understanding Models
近日,谷歌发布了包含 7 种语言释义对的全新数据集,即:PAWS 与 PAWS-X。BERT 通过该数据集的训练,在释义对问题上的精度实现了约为 3 倍的提升;其它先进的模型也能够利用该数据集将精度提高到 85-90%。谷歌希望这些数据集将有助于推动多语言模型的进一步发展,并发布了相关文章介绍了该数据集,记者将其整理编译如下。
背景环境
词序和句法结构对句子意义有很大影响,即使词序中的一点小改动也能完全改变句子的意思,例如下面的一组句子:
Flights from New York to Florida.(从纽约飞往佛罗里达州的航班)
Flights to Florida from New York.(从纽约出发到佛罗里达州的航班)
Flights from Florida to New York.(从佛罗里达州飞往纽约的航班)
尽管这三个词都有相同的词组;但是 1 和 2 具有相同的含义,我们将这样的一组句子对称为释义对(paraphrase pairs),而 1 和 3 有完全相反的含义,所以我们将其称为非释义对(non-paraphrase pairs)。识别一对句子是否为释义对的任务则被称为释义识别,这一任务对于许多实际应用中的自然语言理解(NLU)处理而言是非常重要的,例如:常见的问答任务等。
但令人惊讶的是,目前即使是最先进的模型,如:BERT,如果仅在现有的 NLU 数据集下进行训练,并不能正确地识别大部分非释义对(就像上面所列举的 1 与 3)之间的差异。其中很大的原因是由于在现有 NLU 数据集中,缺少诸如此类的训练数据。因此,即使现有的机器学习模型能够很好地理解复杂的上下文短语,它们依旧很难拥有对该类任务的判断能力。
PAWS 数据集与 PaWS-X 数据集
为了解决这一问题,我们发布了两个新的数据集,致力于帮助社区进行相关的研究。数据集包括:
支持英语的释义识别对抗性数据集 PAWS(Paraphrase Adversaries from Word Scrambling,https://arxiv.org/abs/1904.01130)
支持多语言的释义识别对抗性数据集 PaWS- X(https://arxiv.org/abs/1908.11828)
其中,PaWS-X 数据集则是在 PAWS 数据集基础上,扩展得到包含另外六种不同类型语言的释义识别对抗性数据集,支持的语言包括:法语、西班牙语、德语、汉语、日语和韩语。
这两个数据集都包含了格式良好、具有高度重叠词汇的句子对。其中大约有一半的句子对是释义对,另一些则不是,数据集也包含了最先进模型的训练数据。通过新数据的训练,该模型对释义识别任务的精度从 50% 提高到了 85-90%。
相比之前即使在有新的训练数据时,无法获得非本地上下文信息的模型仍然无法完成释义识别任务的情况;这一新数据集则为测量模型对语序和结构的敏感性提供了一个有效的工具。
数据集详情
PAWS 数据集共计包含了 108463 组由人工标记的句子对,这些数据来源于 Quora Question Pairs(QQP,https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs)以及维基百科页面。
PAWS-X 数据集则包含了 23659 组由人工判断而得的 PAWS 扩展句子对,以及 296406 组由机器翻译的训练对。下表给出了数据集的详细统计。
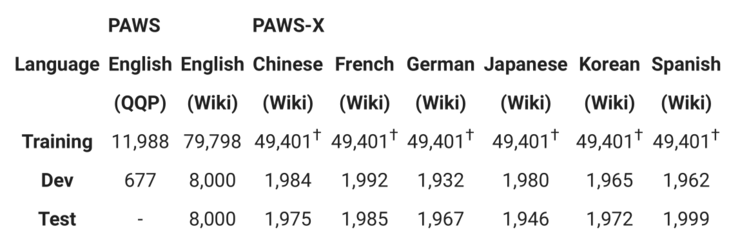
PAWS-X 的训练集是从 PAWS wiki 数据集的一个子集通过机器翻译而来的
支持英语的 PAWS 数据集
在「PAWS: Paraphrase Adversaries from Word Scrambling」一文中,我们介绍了在生成具有高度词重叠的且具有释义性的句子对的工作流程。
为了生成数据对,源语句首先被传递到一个专门的语言模型,该模型将创建具有语义的单词交换变体句,但无法保证生成句子与原句是否互为释义对的关系;接着再由人工评判员判断句子的语法是否正确,然后由其它人工评判员来判断它们是否互为释义句。
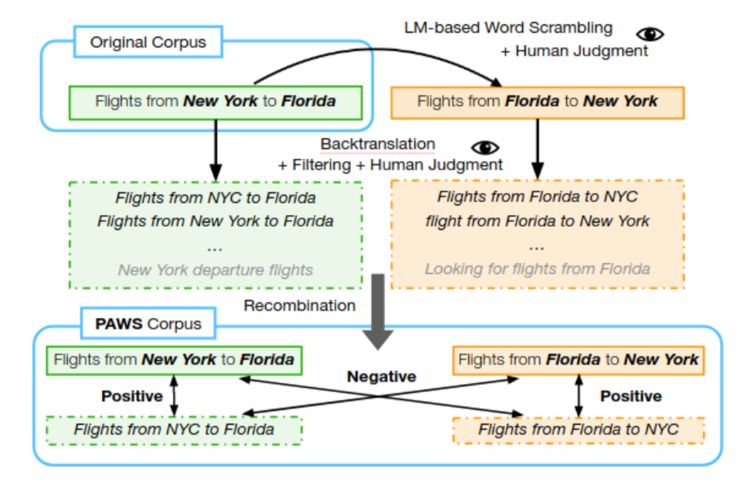
PAWS 语料库创建工作流
这种简单的单词交换策略存在的一个问题,即它往往会产生不符合常识的「释义句」,例如:「why do bad things happen to good people」和「why do good things happen to bad people」,尽管单词都相同,但「为什么坏事会发生在好人身上」的意义和「为什么好事会发生在坏人身上」完全不同。
因此,为了确保释义和非释义之间的平衡,我们增加了其他基于反译的数据信息。因为反译往往表现出与此类方法相反的倾向,它会选择优先保留句子意义,然后在这基础上改变词序和词语选择。这两种策略共同保证 PAWS 语料库总体的平衡,尤其是维基百科部分的数据。
多语言 PAWS-X 数据集的创建
在建立了 PAWS 数据集之后,我们将它扩展出了其它六种语言,包括:汉语、法语、德语、韩语、日语和西班牙语。在这过程中,我们采用了人工翻译来完成句子对的翻译扩展和测试集生成工作,并使用神经网络机器翻译(neural machine translation,NMT)服务来完成训练集的翻译。
我们从六个语言中(共计 48000 组翻译)的每一个 PAWS 扩展集上,随机抽取了 4000 个句子对进行人工翻译(翻译者所翻译语言均为母语)。每一组句子都是独立的,从而保证翻译不会受到语境的影响,然后再由第二个工作者验证随机抽样子集,最终使得数据集的字级错误率小于 5%。
注意,如果所得句子不完整或模棱两可,我们允许专业人士不翻译。平均只有不到 2% 的句子对没有被翻译,我们暂且将它们排除在外。最终的翻译对被分为新的扩展集和测试集,每个集合大约包含 2000 组句子对。
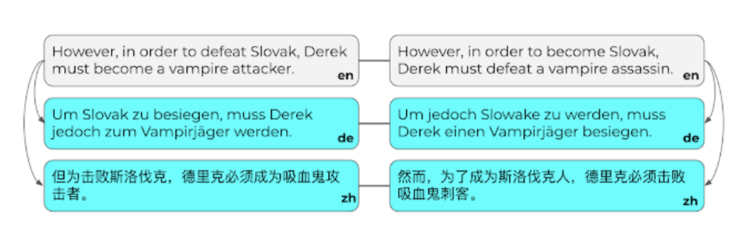
德语(DE)和汉语(ZH)的人工翻译句子对的例子
使用 PAWS 和 PAWS-X 来理解语言
我们在所创建的数据集上训练多个模型,并对评估集上的分类精度进行度量。当用 PAWS 训练强大的模型后,如 BERT 和 DIN,这些模型对现有 QQP 数据集进行训练时的表现会产生显著的改善。
如果在现有 QQP 上训练,BERT 仅获得 33.5 的精度,但是当给定 PAWS 训练实例时,即使用来自 QQP的 PAWS 数据(PAWS-QQP),它的精度将达到 83.1 。
不过与 BERT 不同,Bag-of-Words 模型无法从 PAWS 训练实例中进行学习,这也展示了它在捕捉非局部上下文信息方面的弱点。但总体来看,这些结果都表明了 PAWS 可以有效地度量模型对词序和结构的敏感性。
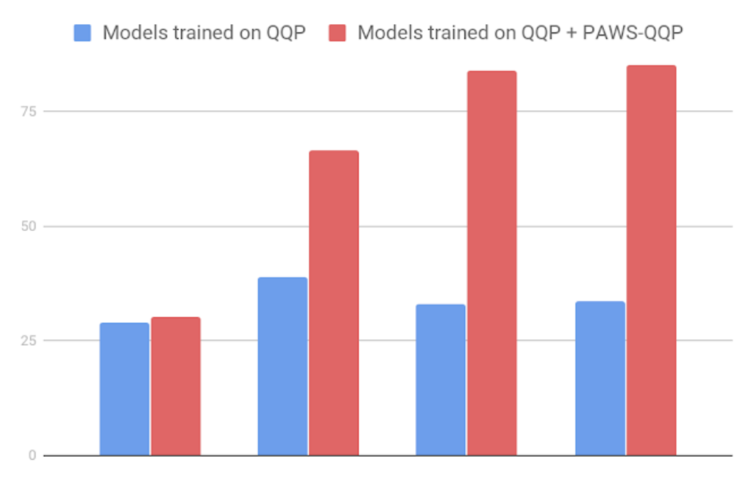
PAWS-QQP 精度评估设置(英文)
下图显示了主流的多语言 BERT 模型在 PAWS X 上使用几种常用方法所表现的性能,其中:
Zero Shot:该模型使用支持英语的 PAWS 数据集进行训练,然后直接评估所有其他翻译,这种方法不涉及机器翻译。(引申:Zero-Shot 翻译则是指在完成语言 A 到语言 B 的翻译训练之后,语言 A 到语言 C 的翻译不需要再经过任何学习,它能自动把之前的学习成果转化到翻译任意一门语言,即便工程师们从来没有进行过相关训练)
Translate Test(翻译测试):使用英语训练数据训练一个模型,并将所有测试用例翻译成英文进行评估。
Translate Train(翻译训练):英语训练数据被机器翻译成每种目标语言,以提供数据来训练每一个模型。
Merged(归并):在所有语言上训练多语言模型,包括原始英语对和所有其他语言的机器翻译数据。
结果表明,新数据集除了为跨语言的技术提供了帮助,同时也留下了很大的余地进而驱动多语种释义识别问题的研究。
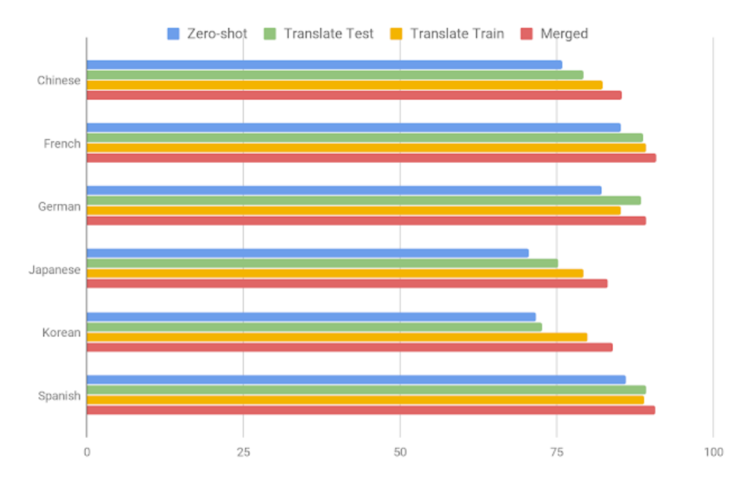
基于 BERT 模型的 PAWS-X 测试集的精度
数据集下载相关
PAWS-Wiki
该语料库包含从维基百科页面生成的句子对(可直接下载),包括:
PAWS-Wik 标记集(终版) 包含从单词交换和反译方法生成的句子对。所有的组别都有释义性和流畅性的人工判断,它们被分为训练/扩展/测试部分。
PAWS-Wik 标记集(仅交换) 包含没有反译对应项的句子对,因此该子集不包含在第一组中。但数据集质量很高,包含人工对释义性和流畅性的判断,可以作为辅助训练集。
-
PAWS-Wik 未标记集(终版) 包含从单词交换和反译方法生成的句子对。但该子集中有噪声标记但没有人工判断,也可用作辅助训练集。
PAWS-QQP
该语料库包含了从 QQP 语料库生成的对,但由于 QQP 的许可证,我们不能直接获得 PAWS-QQP 数据,因此必须通过下载最原始数据,然后运行脚本生成数据并附加标记来重建示例。
重建 PAWS-QQP 语料库,首先需要下载原始的 QQP 数据集,并将 tsv 文件保存到某个位置/path/to/original_qqp/data.tsv;然后从特定链接下载 PAWS-QQP 索引文件。
PAWS-X
该语料库包含六种不同语言的 PAWS 示例翻译,包含:法语、西班牙语、德语、汉语、日语和韩语。详情可通过这里查看(https://github.com/google-research-datasets/paws/tree/master/pawsx)。
需要注意的是,对于多语言实验,请使用 paws-x repo 中提供的 dev_2k.tsv 作为所有语言(包括英语)的扩展集。
数据集下载地址:
https://github.com/google-research-datasets/paws
原文链接:
https://ai.googleblog.com/2019/10/releasing-paws-and-paws-x-two-new.html


点击“阅读原文”查看 7篇 Visual/Video BERT 论文合集



