清华、宾夕法尼亚大学和字节跳动联合提出:提升Single-Shot目标检测的 Consistent Optimization策略
点击上方“CVer”,选择"星标"和“置顶”
重磅干货,第一时间送达

前戏
最近出了很多论文,各种SOTA,CVer也立即跟进报道(点击可访问):
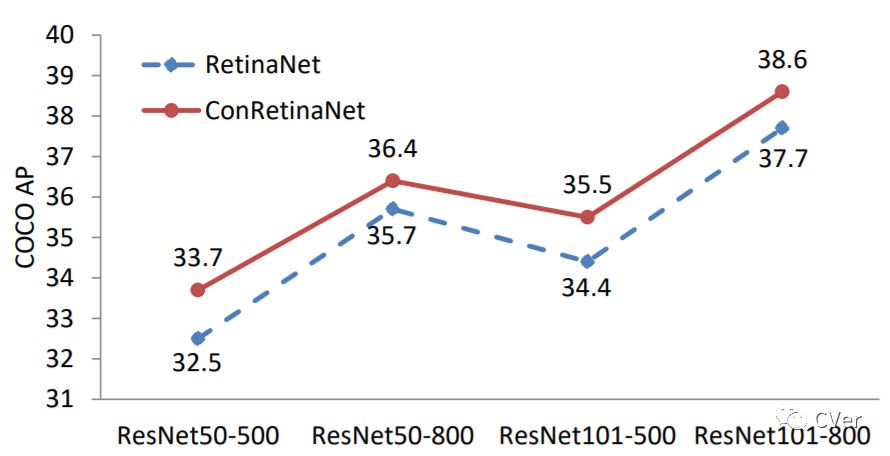
今天po的Consistent Optimization,主要是针对Single-Shot类目标检测算法进行的优化,比如对RetinaNet优化后的ConRetinaNet,其mAP足足提高了接近 1个point
简介
Consistent Optimization for Single-Shot Object Detection

arXiv: https://arxiv.org/abs/1901.06563
github: 近期会开源
作者团队:清华、宾夕法尼亚大学和字节跳动
注:2019年01月23日刚出炉的paper
下面附上论文第一作者:孔涛对论文的解读
链接(已获权转载和原创标识):
https://zhuanlan.zhihu.com/p/55416312
论文解读
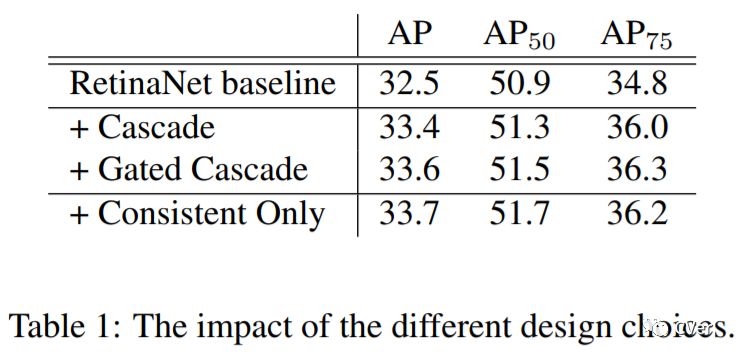
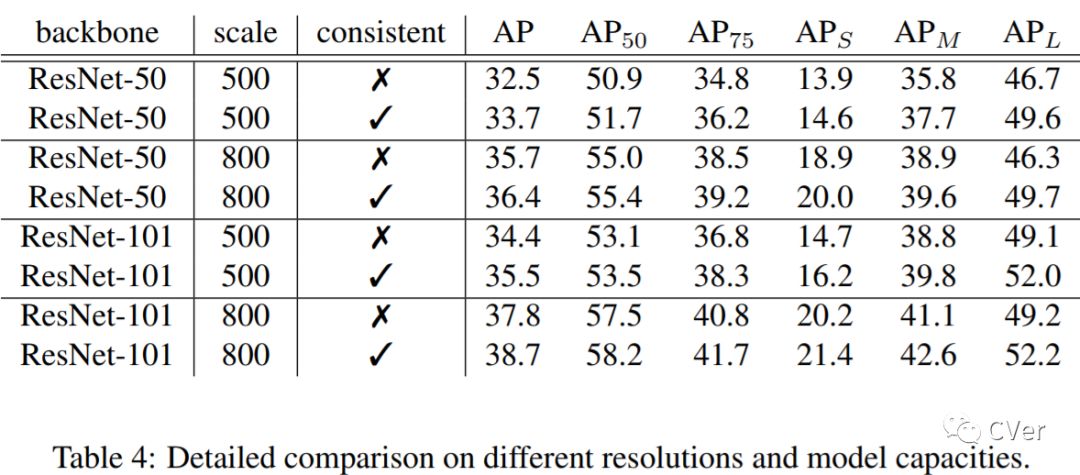
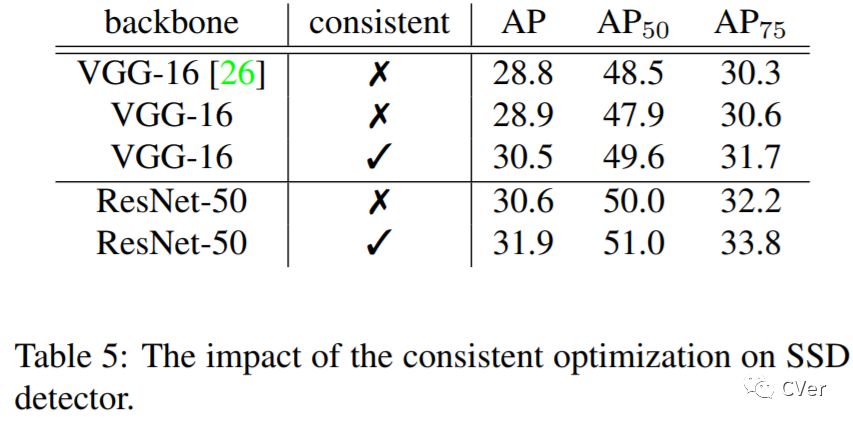
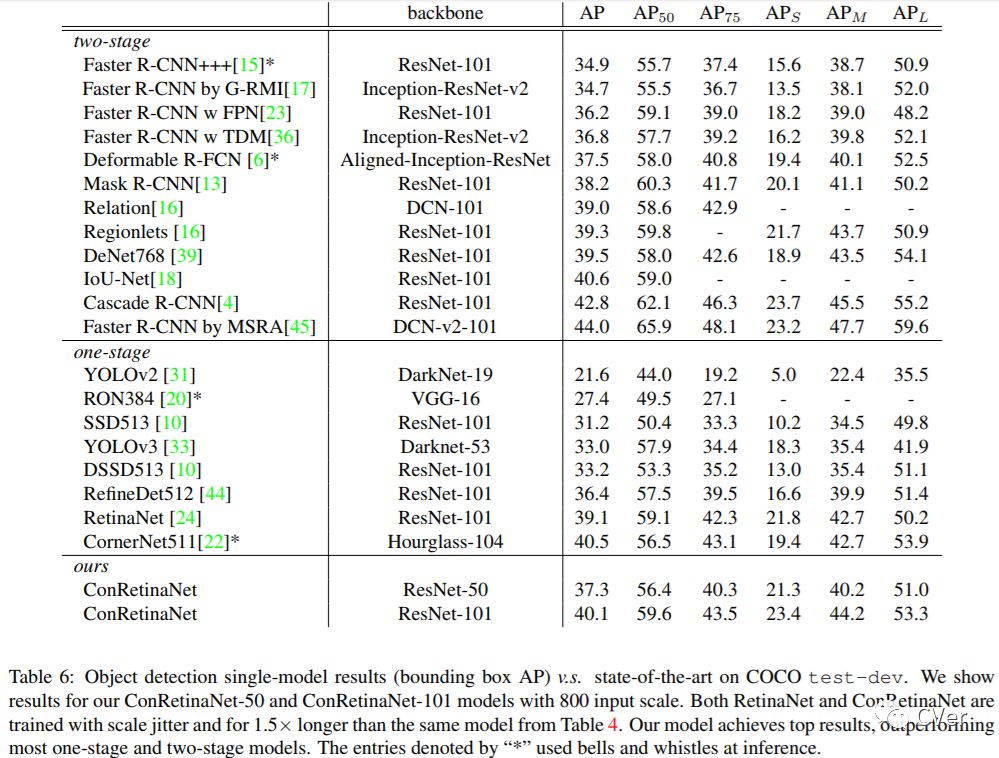
我的合作者和我都非常喜欢这个工作!在这个工作中,我们发现了Single-Stage Detector中普遍存在的训练和测试不一致的问题,然后用一个简单、有效、不改变原有结构的Consistent Optimization策略来解决它,加入Consistent Optimization的RetinaNet在COCO上用ResNet-101达到了40+AP,这是目前single-stage已知的在ResNet-101下最高的单模型单尺度的预测结果。代码会尽快release到github上。(不过因为方法非常简单直接,复现应该不难)。
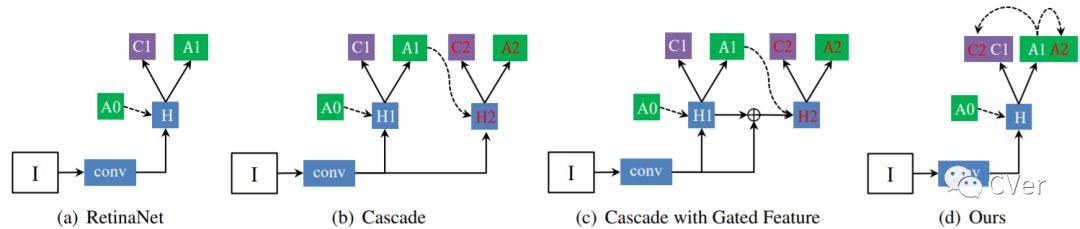
目前,大多数的Detector模型改进方法都集中在了two-stage阵营中,比如Cascade R-CNN、IoU-Net,One-Stage自从RetinaNet之后的工作就比较少了。相对于Two-Stage而言,One-Stage其实更难一些,因为它依赖于全卷积结构来对feature map上进行均匀采样的anchor进行分类和位置调整。怎样才能对现有的one-stage方法进行改进呢?在本文中我们对RetinaNet的结果进行了分析,并发现训练和测试的不一致是其中一个重要的原因。
1. 观察和分析
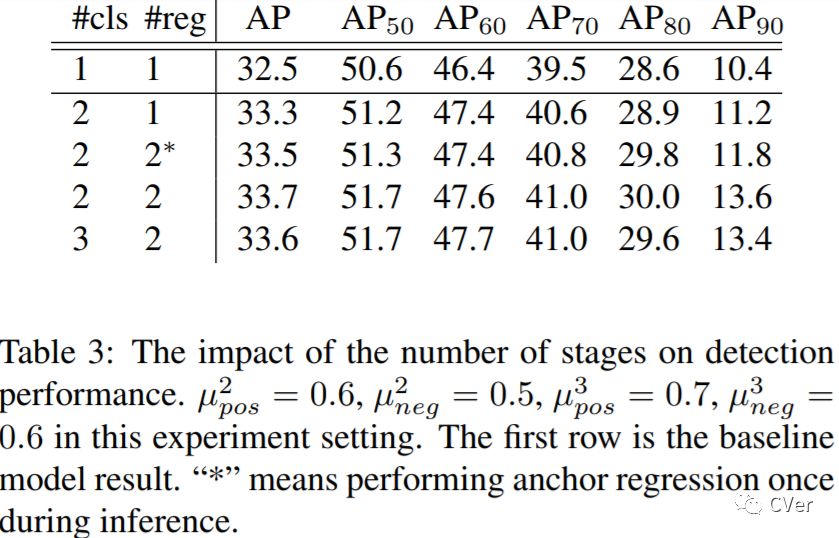
我们首先可视化了RetinaNet的regression分支的结果,发现anchor在regression之前和之后的定位性能的差别是非常大的。一个本身与ground-truth的IoU较小的anchor在回归之后依然可以与ground-truth的IoU变得较大。
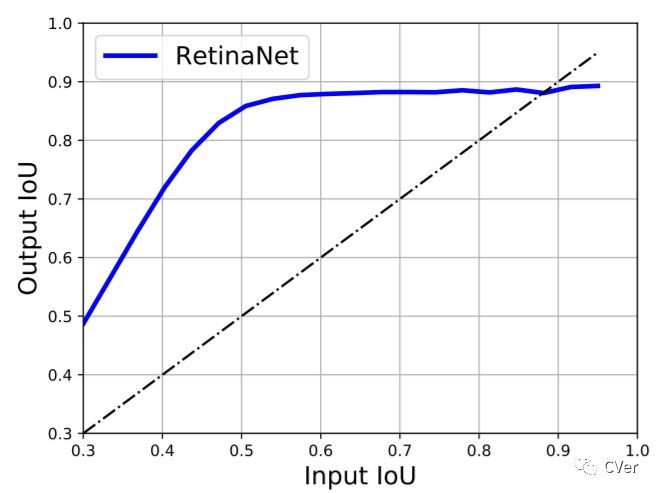
横坐标是输入anchor的IoU,纵坐标是对应的回归后的anchor的IoU
从另一个方面讲,classification分支是基于原始的anchor进行训练的,在标准的设置中,会将IoU>0.5的样本算作是正样本,IoU<0.4的设置为负样本,然后用focal loss训练。在测试中将原始anchor训练的得分赋给调整之后的anchor。因为anchor的定位性能在回归前和回归后是不同的,这必然导致classification分支得到的得分与回归后的anchor的定位能力表现不一致。为了进一步验证这个假设,我们可视化了anchor得分的分布
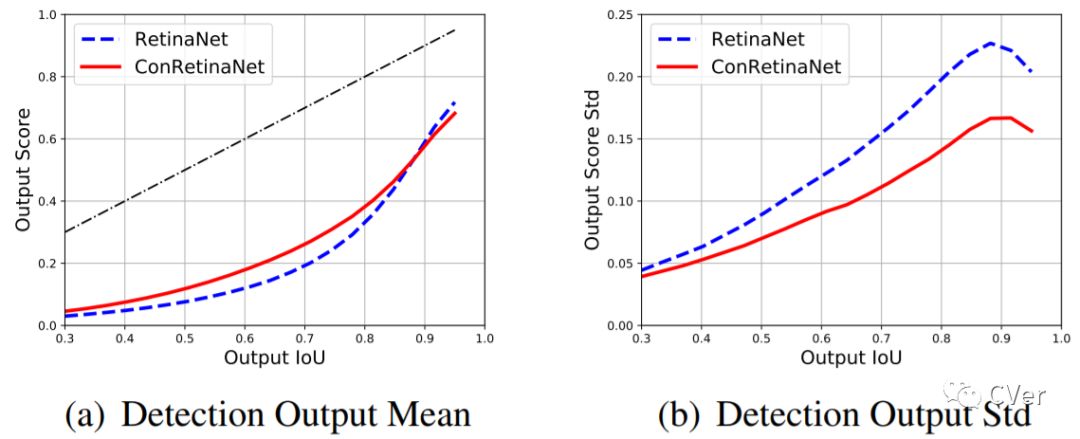
横坐标是调整后的Anchor的IoU,纵坐标是对应的得分的均值和方差,蓝色的虚线是RetinaNet的表现
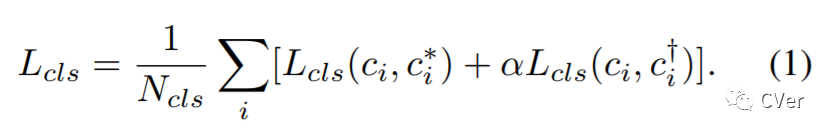
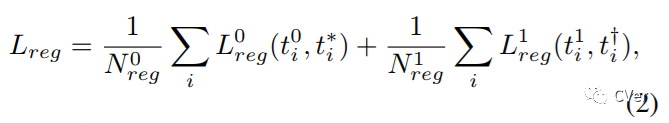
---End---
想要了解最新最快最好的论文速递、开源项目和干货资料,欢迎加入CVer学术交流群。涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、学术竞赛交流、Re-ID、风格迁移、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别和超分辨率等方向。

扫码进群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!

