解读二PREFRONTAL CORTEX AS A META-REINFORCEMENT LEARNING SYSTEM
关于多巴胺和前额皮质的故事:
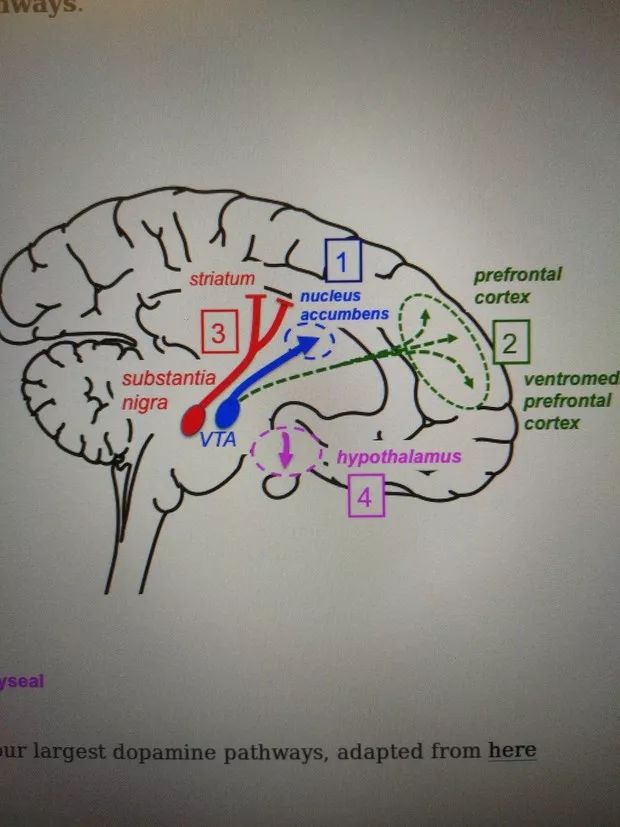
观察人的大脑,有两个重要部分:
1. 基底神经节(或蜥蜴脑),其中包含VTA和黑质,其中产生多巴胺。
这一块会被激活,在得到的奖励比预估的更多时;
这一块会保持在基准线,在得到的奖励就是预估的情况时;
这一块被会抑制,当得到的奖励比预测的奖励少时。于是这种机制就被成为奖励预测误差(Dopamine reward prediction error )。
由这个机制建模的算法就是无模型强化学习,其中对应于奖励预测误差的就是一个算法就是A2C。
remain at baseline activity for fully predicted rewards,
and show depressed activity with less reward than predicted (negative prediction error).”
- Wolfram Schultz, Dopamine reward prediction error coding
2.前额皮质(大脑皮层的一部分),对比多巴胺,它是“理性决策者试图让你做你的工作”。
这种新的学习算法独立于原始算法,并且在适合任务环境的方式上有所不同。
这种学习的主要作用是通过多巴胺的驱使去调整其循环连接来塑造前额网络的动态,使它有了记忆和推理能力。
前期大量训练,逐渐网络从探索转向开发,在更困难的问题中使这种转变更加缓慢。
通过两个部分的合作,完成的功效,就使我们明白了所谓model base 算法,从另一个维度或者另一种眼光去看待它,不过就是由多巴胺机制的无模型算法去调控前额皮质功能的元学习。
衔接之前介绍的第四个实验:two step task.
这个任务本质上:设计了一种在结构相同的两个不同任务中随机切换的任务情况,它想通过论文中架构,用多巴胺和前额皮质的关系的眼光去看待它,于是通过这种元学习的方式,使model free的算法框架有了model based 功效。无模型算法只关心与环境交互得到的奖励大小,而通过论文中算法它可以学到这个得到的奖励来自于common还是uncommon的transition.
该算法的学习速率比控制基于DA的RL算法的学习速率大一个数量级,该算法在训练期间调整了前额网络的权重(设定为0.00005)。因此,结果提供了具体说明,即由meta-RL产生的学习算法可以与最初的产生它的算法不同。
结果还使我们能够强调这一原理的一个重要推论,即meta-RL产生适用于任务环境的前额学习算法。在在本案例中,这种适应表现在学习率对任务波动的响应方式。以前的研究已经提出了解释学习率动态变化的专用机制
率。Meta-RL将这些转变解释为一种涌现效应,源于一系列非常普遍的条件。此外,动态学习率只是一种可能的专业化形式。当元RL出现在具有不同结构的环境中时,将出现本质上不同的学习规则。
重点 下面开始讲第5个实验:Harlow task

由这个心理学实验改装而来:
1一个猩猩,左右两个遮盖的物体
2猩猩选一个,一个物体有食物,另一物体没有,这成为一个trial.
3接下来重复6次选择,即6个trial,称为一个episode.在这个episode的每个trial,物体都会左右随机交换位置,但是物理对应有没有食物不变的。
4.经历大概几百个episode后,猩猩学会了在一个episode开始的时候随便选一个,即使没选对,下一个trial它就能选对,因为猩猩已经学到这个更高级的模式,并且把食物与物体本身联系到一起,而不左右位置。
其实算法架构与two step task基本一样,就一个地方有区别,这正是其神奇的地方:同样都是一个RNN结构,或者同样都是某个数学公式,从不同的观点或眼光去看待它,可以映射到许多的不同是事物中,于是可以解决或者描述看似完全无关的事物,给出一个架构,它们的内涵可以是无限的,black box is magic 。
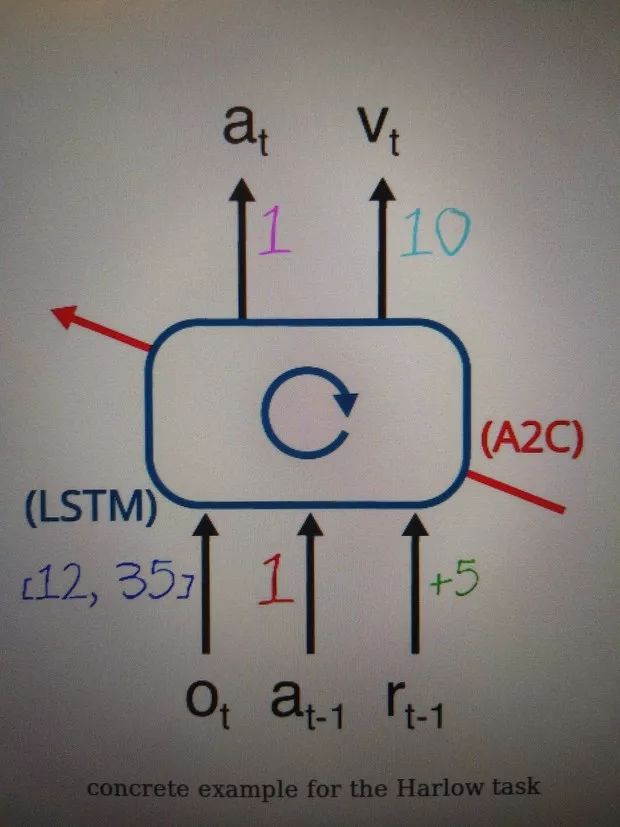
架构如上图:
1 我们用40个图片换来换去作为物体,也是用1到40能代表这40个object 。 于是输入的observation改为 o_t=[id_object1, id_object2]
2 上一个trial我们选了action=1(向右),得到reward 5.
3 有了这些输入,循环网络训练好的权重,因为在这个trial。我们的模型估计出最好的动作还是1,因为这个有奖励的object还是在右边。
通过此实验的领悟:
1 与传统的机器学习算法不同,使用元增强学习,算法在前8-12k集中保持0%的性能。因此,您可能花费无数小时(CPU上的两步任务> 4小时)停留在0%性能,而不知道模型是否正在学习。
我的建议:a)问问自己“我的实验是否出错,我的错误是什么?”b)尽可能准确地记录实验的详细信息(日期,时间,目标,原因可能不是 工作,估计的培训时间等)
2 就像小孩学东西一样,要嘛不懂,要嘛就懂了。很贴合意识产生的过程,一种无意识到意识的涌现,而且是基于平常的条件。
3 调整超参数。只使用一个线程,一个48单位LSTM和一个非常简单的输入进行实验。最终,我们获得的平均奖励达到了约10(约为最高性能的一半,参见“结果”)。我们最好的猜测是48个单位不足以学习任务,但也许它是我们的代码中的单线程或其他东西。简而言之,总是一次改变一个超参数,否则你最终根本不知道为什么你的模型不是在学习。
另外:论文里还提到了对LSTM的理解,我觉得不错:
在标准的非门控递归神经网络中,时间步骤t的状态是时间步骤t-1的状态的线性投影,然后是非线性。这种“香草”RNN可能对于具有远程时间依赖性的有困难,因为它必须学习非常精确的映射,只是为了将信息从一个时间状态复制到下一个时间状态。另一方面,LSTM的工作原理是
将其内部状态(称为“单元状态”)从每个时间步骤复制到下一个时间步骤。它不是必须学习如何记住,而是默认记得。但是,它也可以选择忘记,使用“忘记”(或维护)门,并使用“输入”选择允许新信息进入门”。因为它可能不想在每个时间步输出其整个存储器内容,所以也存在
一个“输出门”来控制输出什么。这些门中的每一个都由学习函数调制网络的状态。
到此结束,欢迎提问题交流,wechat : Leslie27ch


