【干货】谷歌一个模型解决所有问题《One Model to Learn Them All》 论文深度解读
【导读】Google于2017发布论文《One Model to Learn Them All》(一个模型解决所有),文章一问世立刻引发各方关注。除了标题劲爆之外,谷歌研究人员提出了一个多模式适用的架构 MultiModel,用单一的一个深度学习模型,学会文本、图像和翻译这些不同领域的 8 种不同任务,“一个模型解决所有问题”的野心和气魄令人惊叹。本博文对该模型做了详细解释。专知内容组编辑整理。

One model to learn them all
几乎可以肯定地说,每个人的脑海中都有一个关于香蕉的抽象概念。
假设你问我是否想要吃点什么。我可以说“香蕉”这个词(比如你听到这个词的发音),或者给你发一条短信,让你看到(并阅读)“香蕉”这个词,或者给你看一张香蕉的照片,等等。所有这些不同的数据模式(声波,文字,视觉图像)都与相同的概念相联系 - 它们是“输入”香蕉概念的不同方式。你对香蕉的理解与你大脑中的想法是独立的。同样,作为一个“输出”,我可以要求你说出香蕉这个词,写下香蕉这个词,或者画一个香蕉的图片,等等。我们能够独立于输入和输出的形式来推理这些抽象概念。而且我们似乎能够在许多不同的环境下(即跨越许多不同的任务)重复使用我们对香蕉的概念性知识。
深度神经网络通常是针对手头具体的问题而设计和调整的。而泛化操作有助于这样的网络在以前没有见过的具有相同问题的新的实例上有比较好的表现,并且迁移学习有时候通过重用例如来自同一个域内的学习特征表示来给我们提供支持。确实存在多任务模型,“但是所有这些模型都是在同一领域的不同任务上进行训练的:比如翻译任务与类似的其他语言翻译任务一起训练,视觉任务与其他视觉任务一起,语音任务和其他语音任务一起训练。” 虽然我们有一个关于“香蕉”这个单词的文本概念,另一个关于香蕉的图像概念,还有一个关于“香蕉”的发音概念 - 但是这些概念并没有任何联系。在今天选择的这篇论文中的核心问题是:
“我们能否创建一个统一的深度学习模型来解决跨多个领域(文本,图像,语音)的任务?”
为了做到这一点,我们需要什么?我们需要能够支持不同的输入和输出模式(根据手头具体任务的需要),我们需要一个在所有模式之间共享的所学知识的通用数据表示,并且我们需要足够的'设备',使得需要特定功能(例如注意力)的任务能够利用它。 “一个统一模型(One model to rule them all)”引入了一个完全具有这些特征的多模型架构,并且它的表现非常出色。
多模型体系结构的一个实例基于以下数据集同时在八个不同的任务上进行训练:
1. WSJ语音语料库
2. ImageNet数据集
3. COCO图说生成数据集
4. WSJ语义解析数据集
5. WMT英-德翻译语料库
6. 与5相反:德-英翻译语料库
7. WMT英-法翻译语料库
8. 与7相反:德-法翻译语料库(这篇文章这里说的“德-法”并不是与“英-法”相反的,看起来这像一个粘贴错误?)
以下是执行各种不同任务的单一训练模型的一些示例:
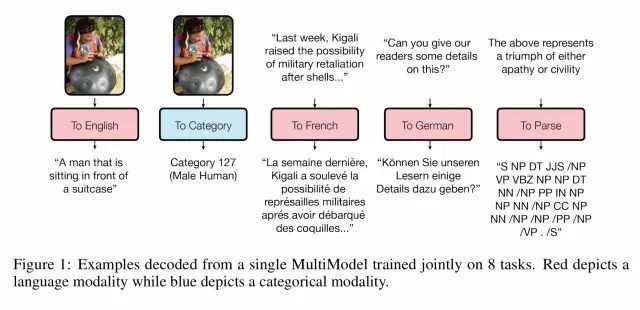
图1:一个单一的多模型在8个任务上的联合训练的例子(从模型直接解码)。红色描绘了语言模态(与语言相关的任务),而蓝色描绘了分类模态(与分类相关的任务)
从上图很明显得看出,MultiModel可以生成图像说明,为图像分类,实现法语德语的翻译,并构建解析树。
▌遮罩下的多模态(MultiModel under the hood)
在高层次上,多模态架构如下所示:
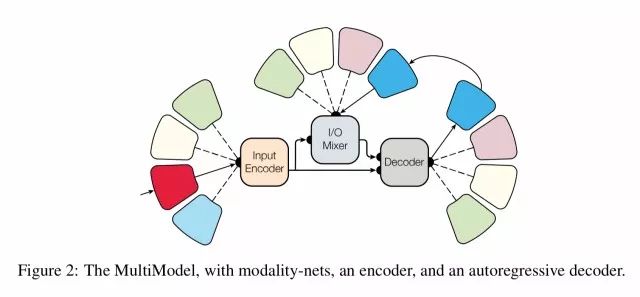
图2:多模态,包含模态网,一个编码器和一个自回归的解码器
有一些小型的,特定模态的子网络可以转换为一个统一的表示并能转换回来。
我们把这些子网络称为模态网络因为他们对于每个模态是特定的(图像,语音,文本)并定义这些外部区域和统一表示之间的转换。我们设计的模态网络在计算上是最小的,大幅提升了特征提取并确保大部分的计算在模型中的不可知域中进行。
相同领域的不同任务(例如,不同的语音任务)共享相同的模态网络。我们没有为每个任务都设计一个模态网,仅仅一个模态对应一个模态网。另外一个重要的设计决策是允许统一的表示在尺寸上是可变的(而不是可能造成瓶颈和限制性能的固定尺寸的表示)。
模态网络的输出称为共享编码器的输入,其创建一个统一的表示。一个I/O混合器将编码过的输入和先前的输出结合起来(多模态是自回归的,它使用先前的输出值来帮助预测下一个输出),一个解码器处理输入和这种混合来生成新的输出。
为了让解码器即使在相同模态下的不同的任务也能产生输出,我们使用一个命令标记来开始解码,例如"To-English"或者"To-Parse-Tree"。我们在训练时学习一个对应于每个标记的表示向量。
正如我们前面所发现的,为了确保各种任务的良好性能,多模态需要需要使用正确的设备来处理。多模态整合了来自多个领域的构建模块包括可分离的卷积(在图像问题的背景下首先引入)和注意力机制,以及稀疏门控的混合专家层(在自然语言处理中首先引入)。
我们发现,这些机制中的每一个对于引入它的领域都是至关重要的。例如,注意力机制在语言相关任务中的重要性远大于在图像相关的任务。然而,有趣的是,添加这些计算模块并不会损害性能,即使在没有特定机制设计的任务上也是如此。事实上,我们发现注意力机制和混合专家层都略微提高了ImageNet在多模态上的性能,即使这个任务不怎么需要他们。
把所有这些东西放在一起,我们最终会看到这样的架构:
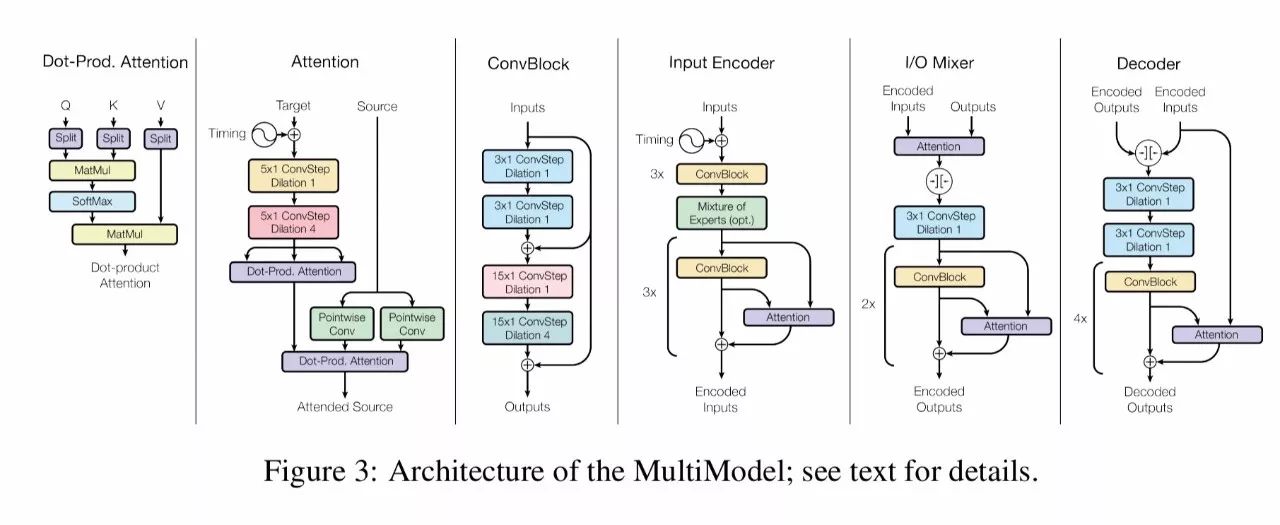
图3:MultiModel的结构:阅读文本来了解细节
编码器,混合器和解码器在结构上类似于以前的全卷积序列模型,但是使用了不同的计算单元。编码器含有6个重复的卷积块,中间是混合专家层。混合器含有一个注意力模块和4个卷积模块。解码器有4个卷积和注意力模块,中间是混合专家层。
▌在运行中的MultiModal (MultiModel in action)
在同时完成8个训练任务的训练之后,作者开始确定:
1、MultiModal与每个任务的最新结果有多接近
2、如何对同时训练8个任务和每个任务分别训练进行比较
3、不同的计算模块怎样影响不同的任务
MultiModal取得的结果与和没有进行大量调整的特定任务模型相似(例如,我们去年报道的在扩展的神经GPU改进的英法翻译)。由于在MultiModal上没有太多的调整,所以期望差距进一步接近是合理的。

表1:将MultiModal和[28]和[21]中最新的方法进行比较
联合训练的模型和单独训练的模型在含有大规模数据的任务上的表现相似。但是更有趣的是,对于可用数据比较少的任务上(例如语法分析),它的表现会更好,甚至好得多。
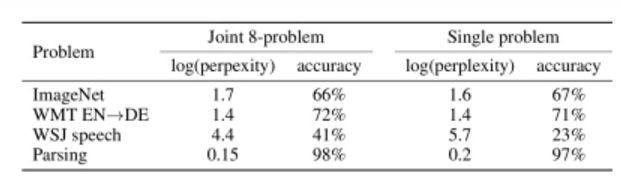
表2:将在8个任务上联合训练好的Multimodal和在每个任务上分别训练的模型进行比较
进一步的调研显示:
似乎计算基元在不同的任务之间共享允许一些迁移学习甚至在ImageNet和语法分析等一些看起来无关的任务中。
这种可以从大规模可用数据中进行学习和提高少量数据可用任务的表现的能力似乎有着很大的潜力。
关于第三个问题,通过包含或排除不同的模块类型来理解他们的影响是可能的。注意力机制和混合专家机制都是为机器翻译而设计的,从理论上来说,ImageNet是从这些模块中收益最少的问题。但是结果表明,即使在ImageNet任务中,这种模块的存在也不会影响性能,甚至可能略微改善。
这导致我们得出结论:混合不同的计算模块实际上是一个提升许多不同任务性能的好方法。

表4:从MultiModal中去除混合专家层和注意力机制
▌最后的结语
我们首次证明,单一的深度学习模型可以共同学习多个领域的大规模任务。成功的关键在于设计一个多模态结构,其中尽可能多的参数是共享的,以及使用不同领域的计算模块。我们相信,这将走向一个关于有趣的关于未来更加普遍的深度学习架构的工作,特别是由于我们的模型展示了从大规模可用数据的任务到数据有限的任务进行迁移学习。
原文链接:
https://blog.acolyer.org/2018/01/12/one-model-to-learn-them-all/
▌相关论文
论文题目:One Model To Learn Them All
论文链接:Kaiser et al., arXiv 2017(https://arxiv.org/abs/1706.05137)

摘要:深度学习在许多领域都获得了很好的成果,从语音识别、图像识别到机器翻译。但在每个问题上,深度学习模型都需要进行长时间的架构研究和调整。我们提出了一个单一模型,它在多个不同领域的任务中都产生了良好结果。这种单一模型同时在 ImageNet、多个翻译任务、图像抓取(COCO 数据集)、一个语音识别语料库和一个英文解析任务中获得训练。该模型架构整合了多个领域的组件。它包含卷基层、注意力机制和 sparsely-gated 层,其中的每个组件对于特定任务都是非常重要的,我们观察到添加这些组件并不会影响模型性能——在大多数情况下,它反而会改善任务中的表现。我们还展示了多个任务联合训练会让仅含少量数据的任务收益颇丰,而大型任务的表现仅有少量性能衰减。
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!




