【强化学习】【元学习】强化学习存在基础性缺陷,研究重点也许要转变,人类的智慧正是强化学习和元学习的结合
原创:
编者按:前段时间,OpenAI的游戏机器人在Dota2的比赛中赢了人类的5人小组,取得了团队胜利,是强化学习攻克的又一游戏里程碑。但是本文作者Andrey Kurenkov却表示,强化学习解决的任务也许没有看起来那么复杂,深究起来是有缺陷的。以下是论智带来的编译。
在这篇文章中,我们来讨论讨论AI核心领域——强化学习的缺陷。我们先从一个有趣的比喻开始,之后会关注一个重要因素——先验知识,接着我们会对深度学习进行介绍,最后进行总结。
首先我们将对强化学习是什么进行介绍,以及它为什么有基础性缺陷(或者至少某个版本,我们称为“纯粹的强化学习”)。如果你是AI专业人才,可以跳过这部分简介。
棋盘游戏
假设你的一位朋友给你介绍了一款你从未听说过的游戏,并且你之前从来没玩过任何游戏。你朋友告诉你怎样算有效的移动,但是却不告诉你这样做的意义是什么,也不告诉你游戏怎么计分。在这种情况下你开始参与游戏,没有任何问题,也不会有任何解释。结果就是不断地输……慢慢地你发现了输局的某些规律,虽然之后还是会输,但起码能坚持玩一段时间了。经过几周后,甚至几千盘对抗后,你甚至能赢下一局。
听起来很傻,为什么不在一开始就问游戏的目标以及应该怎样获胜呢?总之,上面的场景是当下大多数强化学习方法的做法。
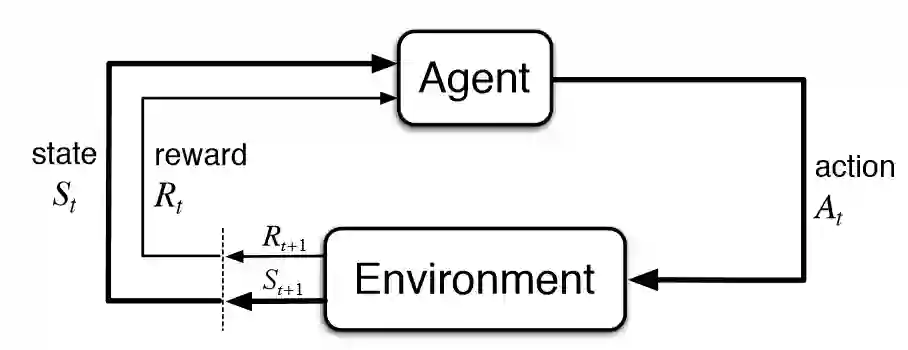
强化学习(RL)是AI的一个基础子领域,在强化学习的框架中,智能体(agent)在与环境的交互中学习应该在特定状态下做出哪些动作从而使长期奖励最大化。这也就是说在上述棋盘游戏中,玩家在棋盘中学习怎么走能让最后的分数最高。
在强化学习的典型模型中,智能体最初只知道它可以做哪些动作,除此之外对环境一无所知,人们希望它能在与环境的交互中,以及在收到奖励后学会该做什么动作。缺少先验知识的意思是,智能体从零开始学习,我们将这种从零开始的方法称为“纯粹的强化学习”。纯强化学习可以用到西洋棋或者围棋中,也可以应用到机器人等其他领域。

最近很多强化学习受到了深度学习的启发,但基础模型没怎么改变。毕竟这种从零开始学习的方法是强化学习的开端,并且在大多数基础等式中都有表现。
所以这里有个基本问题:如果纯强化学习的过程特别不合常理,那么在此基础上设计的AI模型能有多可靠?如果我们认为让人类通过纯强化学习全新的棋盘游戏很荒唐,那么这个框架对智能体来说也是有缺陷的呢?仅仅通过奖励信号而不借助先验知识和高水平指导,就开始学习一项新技能真的有意义吗?
先验知识和高水平指导在经典强化学习中是不存在的,隐式或显式地改变这些方法可能对所有用于训练强化学习的算法有很大影响,所以这是个非常大的问题,要回答它需要两部分:
第一部分即本文,我们将从展示纯强化学习的主要成果开始,这些成果可能不会像你想象得那样重要。接着,我们会展示一些更复杂的成果,它们在纯强化学习下可能无法完成,因为智能体会受到多种限制。
在第二部分中,我们将浏览各种能解决上述限制的方法(主要是元学习和zero-shot学习)。最后,我们会总结基于这种方法的令人激动的成果并进行总结。
纯强化学习真的有道理吗?
看到这个问题,大多数人可能会说
当然了,AI智能体不是人类,不会像我们一样学习,纯强化学习已经能解决很多复杂任务了。
但是我不同意。根据定义,AI研究指的是让机器做只有动物和人类目前能做的事,因此,将机器和人类智慧相比是不恰当的。至于纯强化学习已经解决的问题,人们常常忽视了重要的一点:这些问题通常看起来并不那么复杂。
这听起来可能很惊讶,因为很多大型研究机构都努力地用强化学习做出各种成果。这些成果确实很棒,但是我仍然认为这些任务并不像他们看起来那么复杂。在深入解释之前,我列举了一些成就,并且指出它们为什么值得人们研究:
DQN:这项由DeepMind推出的项目在五年前引起了人们对强化学习极大的兴趣,该项目展示了将深度学习和纯强化学习结合后,可以解决比此前更复杂的问题。虽然DQN只包含少量的创新,但对于让深度强化学习变得更实用是很重要的。

AlphaGo Zero和AlphaZero:这种纯强化学习模型已经超越了人类最佳水平。最初的AlphaGo是监督学习和强化学习结合的产物,而AlphaGo Zero是完全通过强化学习和自我对抗实现的。因此,它是最接近纯强化学习方法的产物,虽然它仍然有提供游戏规则的模型。

在与人类对战获胜后,AlphaGo Zero被很多人看作是一种游戏颠覆者。接着一种更通用的版本——AlphaZero出现了,它不仅能玩围棋,还能下国际象棋和日本将棋,这是第一次有一种算法可以完成两种棋类比赛。所以AlphaGo Zero和AlphaZero是非常了不起的成就。

OpenAI可以打Dota的机器人:深度强化学习能够在Dota2中多人模式中击败人类了。去年,OpenAI的机器人在1v1对抗中击败了人类就已经令人印象深刻了,这次是更加困难的5v5。它同样不需要先验知识,并且也是通过自我对抗训练的。

这种在复杂游戏中的团队模式中获胜的成绩比此前的雅达利游戏和围棋对抗更惊艳。另外,这一模型还没有进行主要的算法更新,完全依靠大量计算和已有的纯强化学习算法和深度学习进行的。
所以,纯强化学习已经做出了很多成绩。但是就像我之前说的,他们有些地方可能被高估了。
首先从DQN开始。
它可以超越人类水平玩很多雅达利游戏,但也并不是全部。一般来说,它适合玩灵活度较高的、不需要推理和记忆的游戏。即使五年之后,也不会有纯强化学习攻下推理和记忆游戏。相反,能完成这些游戏的都经过了指导和示范。
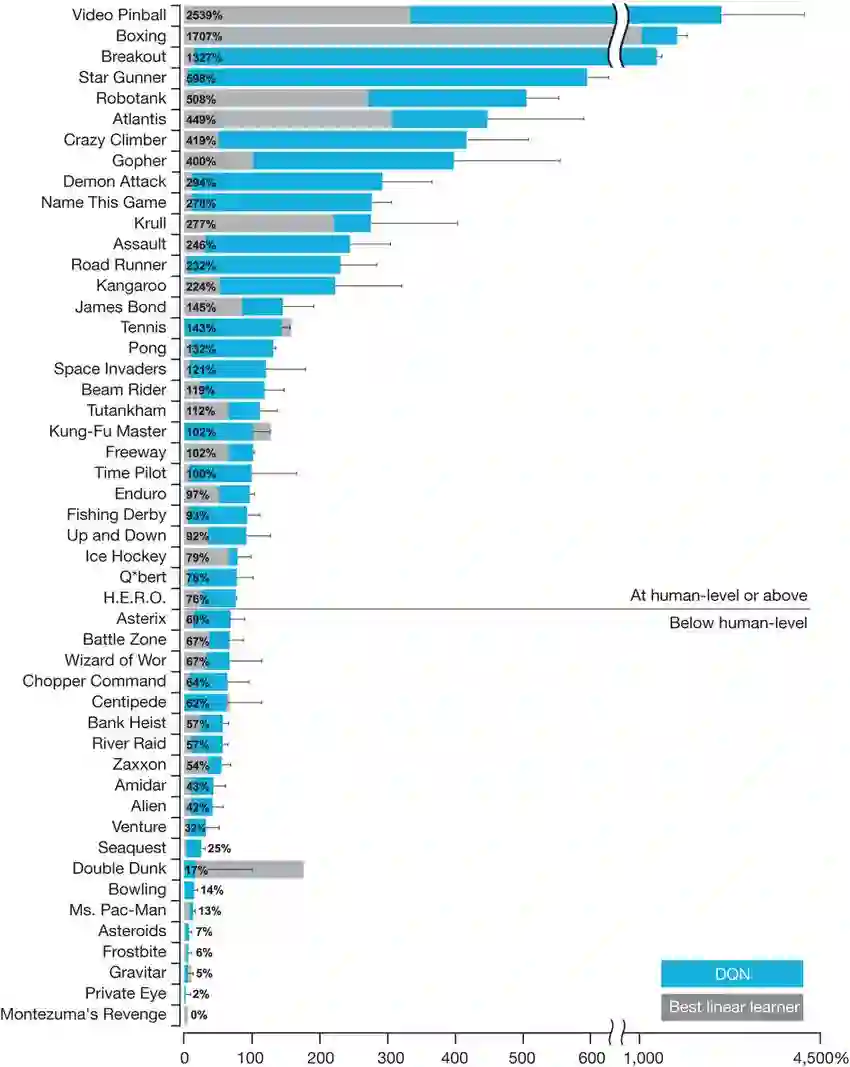
即使在DQN表现良好的游戏中,它也需要非常大量的时间和经验去学习。
同样的限制在AlphaGo Zero和AlphaZero上都有体现。围棋的很多性质都能让学习任务变得简单,例如它是必然的、完全可观测的、单一智能体等等。但唯独一件事让围棋变得麻烦:它的分支因数太多了。
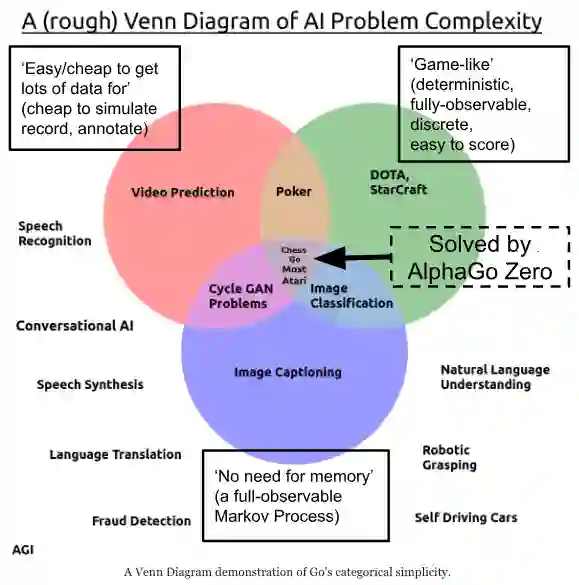
所以,围棋可能是变数最多的简易游戏。有人说强人工智能(AGI)因为AlphaGo的成功即将到来,这种说法不攻自破。多数研究者认为,真实的世界比一个简单游戏复杂得多,尽管AlphaGo的成功令人赞赏,但是它和它所有的变体从根本上和“深蓝”是相似的:它只是一套昂贵的系统罢了。
说到Dota,它的确比围棋更复杂,并且是非静止的、多人的游戏。但是它仍然是可以用灵活的API操控的游戏,并且成本巨大。
所以,尽管这些成就很伟大,我们仍需要对它们的本质进行了解,同时要思考,纯强化学习难道不能成为获取这些成就的最佳方法吗?
纯强化学习的基础缺陷——从零开始
有没有更好的方法让智能体下围棋、玩dota呢?AlphaGo Zero的名字来源正是暗示它是从零开始学习的模型,但是让我们回到文章开头说的那个小故事,如果让你从零开始学习下围棋,不给任何解释,听起来很荒谬对吗?所以为什么要把这定为AI的目标呢?
事实上,如果你正在学的那个棋盘游戏是围棋,你会怎么开始?可能你会先读一遍规则,学一些高级策略,回忆一下之前的对战,总结经验……确实,让AlphaGo Zero和Dota机器人从零开始学习是有点不公平的,它们只依靠更多数量的游戏经验和运用比人类大得多的计算力。

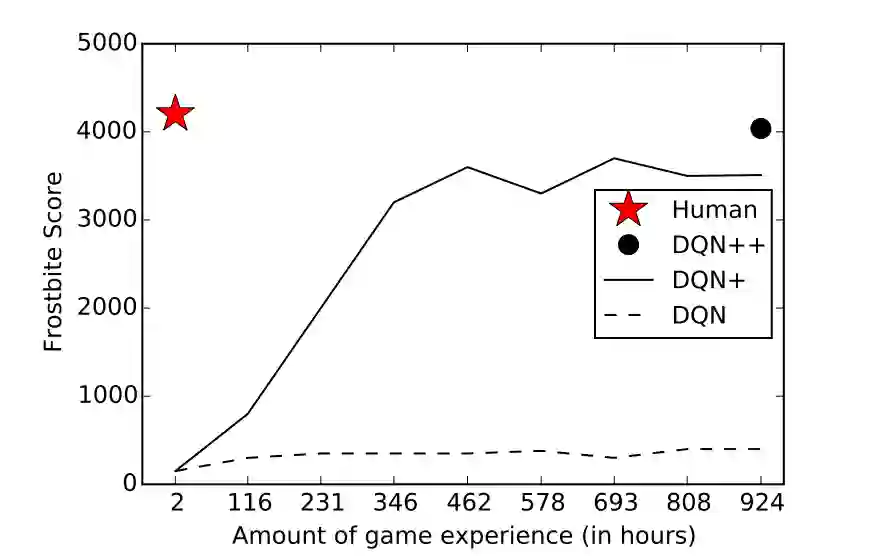
AlphaGo Zero技能增长曲线,注意,它花了一整天的时间和好几千局游戏才达到人类最低水平
实际上,纯强化学习技术可以在更“窄”的任务中应用,例如连续控制或是像dota和星际争霸这样的复杂游戏。然而随着深度学习的成功,AI研究者正尝试解决更复杂的问题例如汽车驾驶和对话。
所以,纯强化学习,或者从零开始的学习方法,是解决复杂任务的正确方法吗?
是否应该坚持纯强化学习?
答案可能如下:
当然,纯强化学习是除了围棋和dota之外的其他问题的正确解决方法。虽然在棋盘类游戏中有点讲不通,但是在通用事物的学习上还是可以说得通的。另外,就算不受人类的启发,智能体在没有先验知识的条件下也能表现得更好。
让我们先说最后一点,不考虑人类的启发,从零开始的典型做法就是另一种方法会限制模型的精确度,将人类的想法编码到模型上是很困难的,甚至会降低性能。这种观点在深度学习的成功之后成为了主流,即用百万级参数学习端到端模型,并在大量数据上训练,同时有一些内在先验知识。
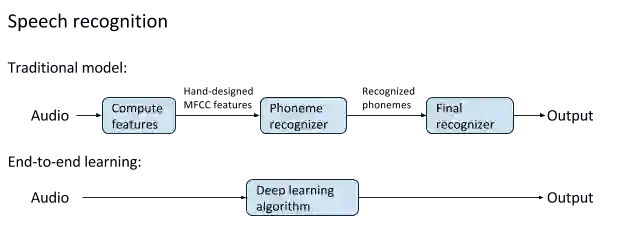
但问题时,加入先验知识和知道并不会将人类知觉中含有的有限结构加入到智能体上。换句话说,我们可以教会智能体或模型关于怎样执行任务,而不会添加对其能力有限制的因素。
对大多数AI问题来说,不从零开始就不会限制智能体学习的方式。目前还没有确切的原因解释,为什么AlphaGo Zero如此执着于“从零开始”,事实上它可以借助人类知识表现得更好。
那么纯强化学习是最佳解决办法吗?这个答案曾经很简单,在无梯度优化领域,纯强化学习是你可以选择的最可靠的方法。但是最近的一些论文质疑了这一说法,并认为更简单的基于演化策略的方法能达到相似效果。具体论文:
Simple random search provides a competitive approach to reinforcement learning
Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning

Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Towards Generalization and Simplicity in Continuous Control
Ben Recht,是理论和实际优化算法的顶尖研究者,也是Simple random search provides a competitive approach to reinforcement learning一文的作者之一,他准确地总结了以上观点:
我们看到,随机搜索在简单线性问题上表现良好,并且比一些强化方法,例如策略梯度表现得更好。但是当我们提出更难的问题时,随机搜索崩溃了吗?不好意思,没有。
所以,将纯强化学习用来从零开始学习不一定是正确的方法。但是回到人类从零开始学习的问题,人们会在具备一些技巧,却没有指示信息的情况下开始学习吗?不会的。
也许在一些通用基础问题上,纯强化学习可能有用,因为这些问题很广泛。但是在AI中,很大部分的问题是否适合强化学习还并不清楚。事实上,之所以选择从零开始,是因为目前的AI和强化学习都有着很多缺陷:
目前的AI非常需要数据。很多项目都需要大量的数据进行计算,而从零学习只需要高效的采样方法即可。
目前的AI是不透明的。也就是“黑箱”问题,很多时候我们只能从较高层次了解AI算法的学习和工作流程。
目前的AI应用范围有限。很多模型一次只能执行一种任务,而且很容易崩溃。
现有AI很脆弱。只有在大量数据训练的基础上,模型才可能对从未见过的输入生成较好结果。即使如此也经常崩溃。
所以,我们到底想让AI智能体学会什么?如果智能体是个人类,我们可以对任务进行解释或提供一些经验。但它们不是人类,我们又应该做什么呢?具体做法将在明天的文章中详细介绍。
原文地址:https://thegradient.pub/why-rl-is-flawed/
面对强化学习的基础性缺陷,研究重点也许要转变
在上一篇文章里,我们提到了棋盘游戏的比喻和纯强化学习技术的缺陷(斯坦福学者冷思考:强化学习存在基础性缺陷)。在这一部分中,我们会列举一些添加先验知识的方法,同时会对深度学习进行介绍,并且展示对最近的成果进行调查。
那么,为什么不跳出纯强化学习的圈子呢?
你可能会想:
我们不能越过纯强化学习来模仿人类的学习——纯强化学习是严格制定的方法,我们用来训练AI智能体的算法是基于此的。尽管从零开始学习不如多提供些信息,但是我们没有那样做。
的确,加入先验知识或任务指导会比严格意义上的纯强化学习更复杂,但是事实上,我们有一种方法既能保证从零开始学习,又能更接近人类学习的方法。
首先,我们先明确地解释,人类学习和纯强化学习有什么区别。当开始学习一种新技能,我们主要做两件事:猜想大概的操作方法是什么,或者读说明书。一开始,我们就了解了这一技能要达到的目标和大致使用方法,并且从未从低端的奖励信号开始反向生成这些东西。

UC Berkeley的研究者最近发现,人类的学习速度比纯强化学习在某些时候更快,因为人类用了先验知识
使用先验知识和说明书
这种想法在AI研究中有类似的成果:
解决“学习如何学习”的元学习方法:让强化学习智能体更快速地学会一种新技术已经有类似的技巧了,而学习如何学习正是我们需要利用先验知识超越纯强化学习的方法。

MAML是先进的元学习算法。智能体可以在元学习少次迭代后学会向前和向后跑动
迁移学习:顾名思义,就是将在一种问题上学到的方法应用到另一种潜在问题上。关于迁移学习,DeepMind的CEO是这样说的。
我认为(迁移学习)是强人工智能的关键,而人类可以熟练地使用这种技能。例如,我现在已经玩过很多棋盘类游戏了,如果有人再教我另一种棋类游戏,我可能不会那么陌生,我会把在其他游戏上学到的启发性方法用到这一游戏上,但是现在机器还做不到……所以我想这是强人工智能所面临的重大挑战。
零次学习(Zero-shot learning):它的目的也是掌握新技能,但是却不用新技能进行任何尝试,智能体只需从新任务接收“指令”,即使没有执行过新的任务也能一次性表现的很好。
一次学习(one-shot learning)和少次学习(few-shot learning):这两类是研究的热门区域,他们和零次学习不同,因为它们会用到即将学习的技巧做示范,或者只需要少量迭代。
终身学习(life long learning)和自监督学习(self supervised learning):也就是长时间不在人类的指导下学习。

这些都是除了从零学习之外的强化学习方法。特别是元学习和零次学习体现了人在学习一种新技能时更有可能的做法,与纯强化学习有差别。一个元学习智能体会利用先验知识快速学习棋类游戏,尽管它不明白游戏规则。另一方面,一个零次学习智能体会询问游戏规则,但是不会做任何学习上的尝试。一次学习和少次学习方法相似,但是只知道如何运用技能,也就是说智能体会观察其他人如何玩游戏,但不会要求解释游戏规则。

最近一种混合了一次学习和元学习的方法。来自One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
元学习和零次学习(或少次学习)的一般概念正是棋类游戏中合理的部分,然而更好的是,将零次学习(或少次学习)和元学习结合起来就更接近人类学习的方法了。它们利用先验经验、说明指导和试错形成最初对技能的假设。之后,智能体亲自尝试了这一技巧并且依靠奖励信号进行测试和微调,从而做出比最初假设更优秀的技能。
这也解释了为什么纯强化学习方法目前仍是主流,针对元学习和零次学习的研究不太受关注。有一部分原因可能是因为强化学习的基础概念并未经受过多质疑,元学习和零次学习的概念也并没有大规模应用到基础原理的实现中。在所有运用了强化学习的代替方法的研究中,也许最符合我们希望的就是DeepMind于2015年提出的Universal Value Function Approximators,其中Richard Sutton提出了“通用价值函数(general value function)”。这篇论文的摘要是这样写的:
价值函数是强化学习系统中的核心要素。主要思想就是建立一个单一函数近似器V(s;θ),通过参数θ来估计任意状态s的长期奖励。在这篇论文中,我们提出了通用价值函数近似器(UVFAs)V(s, g;θ),不仅能生成状态s的奖励值,还能生成目标g的奖励值。

将UVFA应用到实际中
这种严格的数学方法将目标看作是基础的、必须的输入。智能体被告知应该做什么,就像在零次学习和人类学习中一样。
现在距论文发表已经三年,但只有极少数人对论文的结果表示欣喜(作者统计了下只有72人)。据谷歌学术的数据,DeepMind同年发表的Human-level control through deep RL一文已经有了2906次引用;2016年发表的Mastering the game of Go with deep neural networks and tree search已经获得了2882次引用。
所以,的确有研究者朝着结合元学习和零次学习的方向努力,但是根据引用次数,这一方向仍然不清楚。关键问题是:为什么人们不把这种结合的方法看作是默认方法呢?
答案很明显,因为太难了。AI研究倾向于解决独立的、定义明确的问题,以更好地做出进步,所以除了纯强化学习以及从零学习之外,很少有研究能做到,因为它们难以定义。但是,这一答案似乎还不够令人满意:深度学习让研究人员创造了混合方法,例如包含NLP和CV两种任务的模型,或者原始AlphaGo加入了深度学习等等。事实上,DeepMind最近的论文Relational inductive biases, deep learning, and graph networks也提到了这一点:
我们认为,通向强人工智能的关键方法就是将结合生成作为第一要义,我们支持运用多种方法达到目标。生物学也并不是单纯的自然和后期培养相对立,它是将二者结合,创造了更有效的结果。我们也认为,架构和灵活性之间并非对立的,而是互补的。通过最近的一些基于结构的方法和深度学习混合的案例,我们看到了结合技术的巨大前景。
最近元学习(或零次学习)的成果
现在我们可以得出结论:
受上篇棋盘游戏比喻的激励,以及DeepMind通用价值函数的提出,我们应该重新考虑强化学习的基础,或者至少更加关注这一领域。
虽然现有成果并未流行,但我们仍能发现一些令人激动的成果:
Hindsight Experience Replay
Zero-shot Task Generalization with Multi-Task Deep Reinforcement Learning

Representation Learning for Grounded Spatial Reasoning
Deep Transfer in Reinforcement Learning by Language Grounding

Cross-Domain Perceptual Reward Functions
Learning Goal-Directed Behaviour
上述论文都是结合了各种方法、或者以目标为导向的方法。而更令人激动的是最近有一些作品研究了本能激励和好奇心驱使的学习方法:
Kickstarting Deep Reinforcement Learning
Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning
Meta-Reinforcement Learning of Structured Exploration Strategies

Learning Robust Rewards with Adversarial Inverse Reinforcement Learning
Curiosity-driven Exploration by Self-supervised Prediction
Learning by Playing - Solving Sparse Reward Tasks from Scratch
Learning to Play with Intrinsically-Motivated Self-Aware Agents
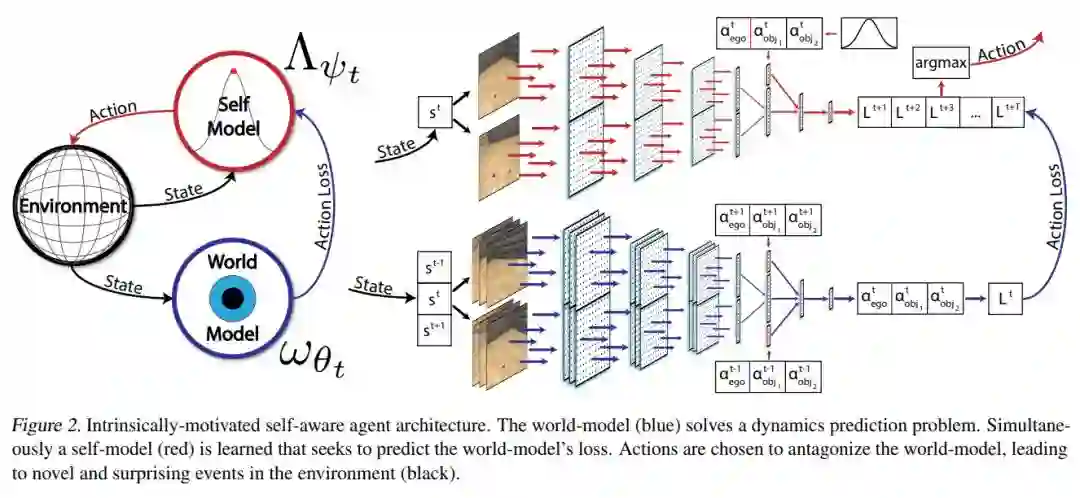
Unsupervised Predictive Memory in a Goal-Directed Agent
World Models
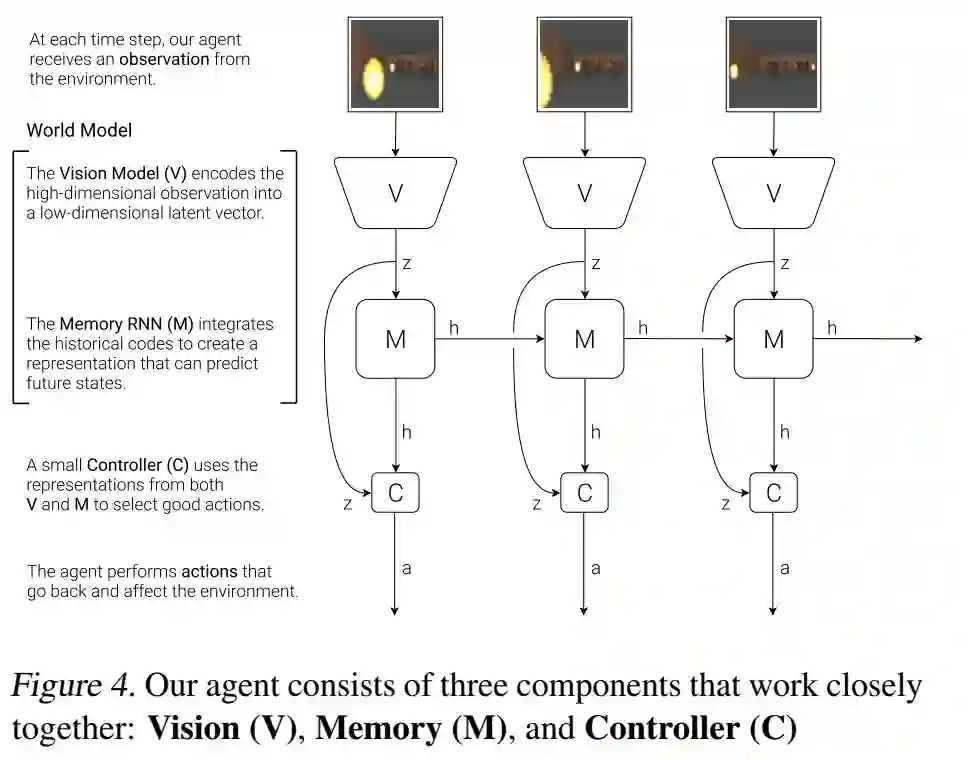
接着,我们还可以从人类的学习中获得灵感,也就是直接学习。事实上,过去和现在的神经科学研究直接表明,人类和动物的学习可以用强化学习和元学习共同表示。
Meta-Learning in Reinforcement Learning
Prefrontal cortex as a meta-reinforcement learning system
最后一篇论文的结果和我们的结论相同,论智此前曾报道过这篇:DeepMind论文:多巴胺不只负责快乐,还能帮助强化学习。从根本上讲,人们可以认为,人类的智慧正是强化学习和元学习的结合——元强化学习的成果。如果真的是这种情况,我们是否也该对AI做同样的事呢?
结语
强化学习的经典基础性缺陷可能限制它解决很多复杂问题,像本文提到的很多论文中都提到,不采用从零学习的方法也不是必须有手工编写或者严格的规则。元强化学习让智能体通过高水平的指导、经验、案例更好地学习。
目前的时机已经成熟到可以展开上述工作,将注意力从纯强化学习的身上移开,多多关注从人类身上学到的学习方法。但是针对纯强化学习的工作不应该立即停止,而是应该作为其他工作的补充。基于元学习、零次学习、少次学习、迁移学习及它们的结合的方法应该成为默认方法,我很愿意为此贡献自己的力量。
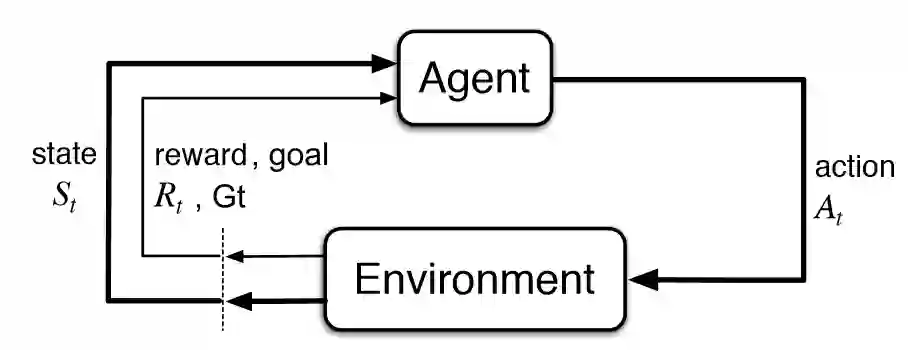
原文地址:thegradient.pub/how-to-fix-rl/
多巴胺不只负责快乐,还能帮助强化学习
编者按:在过去的20年中,基于奖励学习的神经科学研究已经发展成了典型的模型,在这一模型中,神经递质多巴胺通过调节神经元之间突触连接的强度了解场景、行为和奖励之间的联系。然而,最近大量的研究使得这类标准模型渐渐“失宠”。
基于最近人工智能的发展,DeepMind的研究人员发现了一种有关基于奖励的学习的新理论。在这篇论文中,他们让多巴胺系统训练大脑的前额叶皮质层,使其学会独立学习。这一新观点不仅契合标准模型,更激发了新的发现,同时还有助于未来的研究。以下是论智对DeepMind博客的编译。

论文地址:arxiv.org/abs/1611.05763
最近,AI系统已经会玩许多电子游戏了,比如经典的雅达利游戏Breakout和Pong。虽然表现出色,AI仍然需要依赖数千小时的游戏训练才能达到甚至超越人类水平。相反,我们只需要几分钟就能学会一款新游戏的基本操作。
大脑为什么能在短时间具备这些能力即是元学习理论,或者说是“学习如何学习”的过程。一直以来,科学家认为我们在学习时遵循两个尺度:短期内,我们关注的重点在学习具体的例子上,长期来看,我们学习的是完成一项任务所需要的抽象技巧或规则。这两种学习方法的结合帮助我们高效地学习,并将这些知识快速、灵活地应用到新任务中。之后我们证明,在AI系统中创建这种元学习结构,对于让智能体具备快速、一次性成功的学习是非常有效的。然而,这种发生在大脑中的处理机制仍然很难完全用神经科学解释清楚。
在我们新发表在《Nature》上的论文中,我们利用元强化学习框架,探究大脑中多巴胺在帮助我们学习时所起的作用,从而应用于AI上。
多巴胺,通常被人们看作是是大脑愉悦的信号,研究人员经常将其类比成强化学习算法中的“奖励”。这些算法通过不断试错、在奖励的激励下学习某种动作。我们认为,多巴胺的角色不仅仅是使用奖励学习之前的动作,而是有更内在的功能,尤其在大脑的前额叶皮质区,能让我们更快、更高效、更灵活地学习新任务。
多巴胺结构
为了测试我们的理论,我们重建了六个虚拟的神经科学元学习实验,每个实验都需要智能体用到相同的基础规则(或技能),但是它们在某些维度上是不同的。我们用标准的深度强化学习技术(模拟多巴胺的作用)训练了一个循环神经网络(表示前额叶皮质区),然后将循环神经网络生成的动态活动与在神经科学实验中得到的真实数据相对比。循环神经网络是元学习一个很好地代理,因为它们可以内化过去的行为和所观察到的动作,并且在不同任务上训练时会用上这些经验。
重建的实验中,有一项名为“恒河猴实验(Harlow Experiment)”的项目,这是上世纪40年代的一种心理学测试,用来探寻元学习的概念。在最初的测试中,科学家们给一群猴子两种不同的物品,让它们从中选择,只有其中一个物品会得到奖励。这一实验进行了六次,每次科学家都会交换左右两个物品,让猴子学会辨认哪种物品会得到奖励。之后他们又换了两种不一样的物品,同样只有其中一个会获得奖励。通过这次训练,猴子学会了挑选能得到奖励的策略:第一次,它们只是随机挑选,然后根据奖励反馈选择特殊的物品,而不是简单地挑选左右。实验表明,猴子可以将一项任务的基本规则内化,学习抽象的规则结构,也就是“学着学习”。
当我们用虚拟屏幕模拟类似的测试,并随机选择图片时,我们发现,我们的“元强化学习智能体”表现出“恒河猴实验”中动物的行为,即使我们提供的是完全陌生的图片。

事实上,我们发现,元强化学习智能体可以学着快速适应多种具有不同规则和结构的任务。而且由于网络学会了如何适应不同任务,它同样可以学会如何高效学习的基本通用原则。
重要的是,我们发现学习的大部分都发生在循环网络中,这也证实了我们的想法“多巴胺在元学习过程中的内部作用更重要”。传统观点认为,多巴胺是用来加强前额叶系统的突触连接、强化特定行为的。在人工智能中,这意味着类似多巴胺的奖励信号会调整神经网络中的人工突触权重,让它学习正确的解决任务方法。然而,在我们的实验中,神经网络的权重是固定的,也就是说它们无法再学习过程中进行调整。但是,元强化学习智能体仍然可以解决并适应新的问题。这就表明,多巴胺似的奖励并不仅仅用来调整权重,而且还蕴含了许多关于抽象任务和规则的重要信息,使其对新的任务适应得更快。
神经科学家们花了很长时间观察大脑前额叶皮质区的类似神经活动,即能够快速地适应,并且非常灵活。但是很难找到出现这种情况的原因。有观点这样认为:前额叶皮质区并不依赖缓慢的突触权重的改变学习规则结构,而是利用抽象的、基于模型的信息直接解码多巴胺中的信息。这一观点为前额叶皮质区的多功能性提供了令人满意的解释。
在探究AI和大脑中生成元强化学习的关键因素的过程中,我们提出的理论不仅适用于已知的多巴胺在前额叶皮质区的作用,而且还能解释神经科学和心理学中许多神秘的成果。特别是这项理论对于大脑中有结构的、基于模型的学习的产生、多巴胺为何自身具有基于模型的信息、以及前额叶皮质区的神经元是如何转换成与学习相关的信号的,都有了新的发现。用从人工智能系统中得到的发现探究神经科学和心理学的研究,表明两种不同领域之间的相互作用。未来,我们希望这一过程能反过来,用大脑中特殊组织来设计强化学习智能体学习的新模型。
原文地址:deepmind.com/blog/prefrontal-cortex-meta-reinforcement-learning-system/

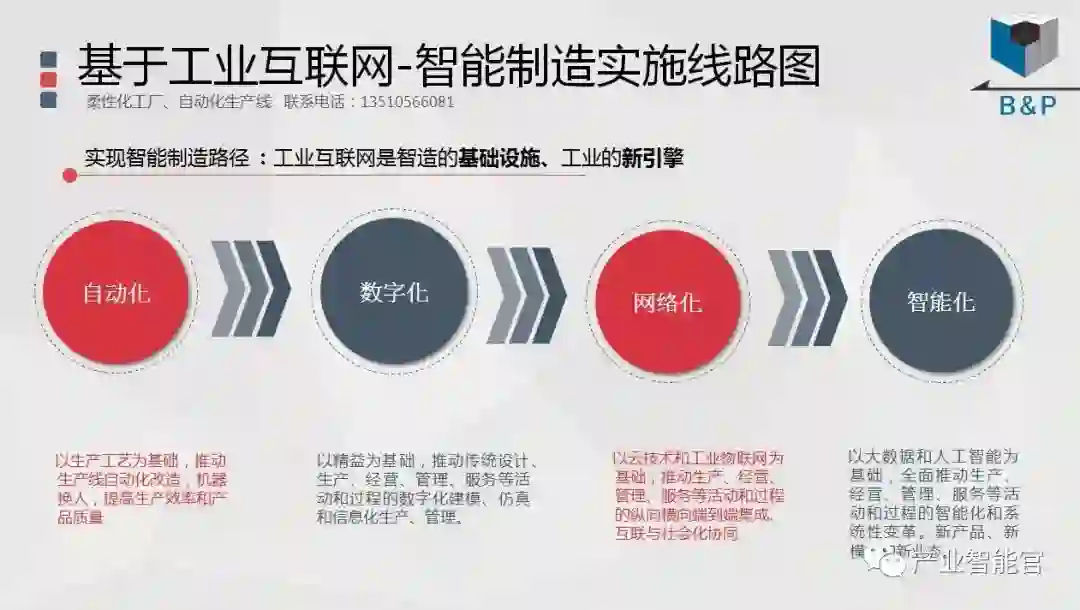

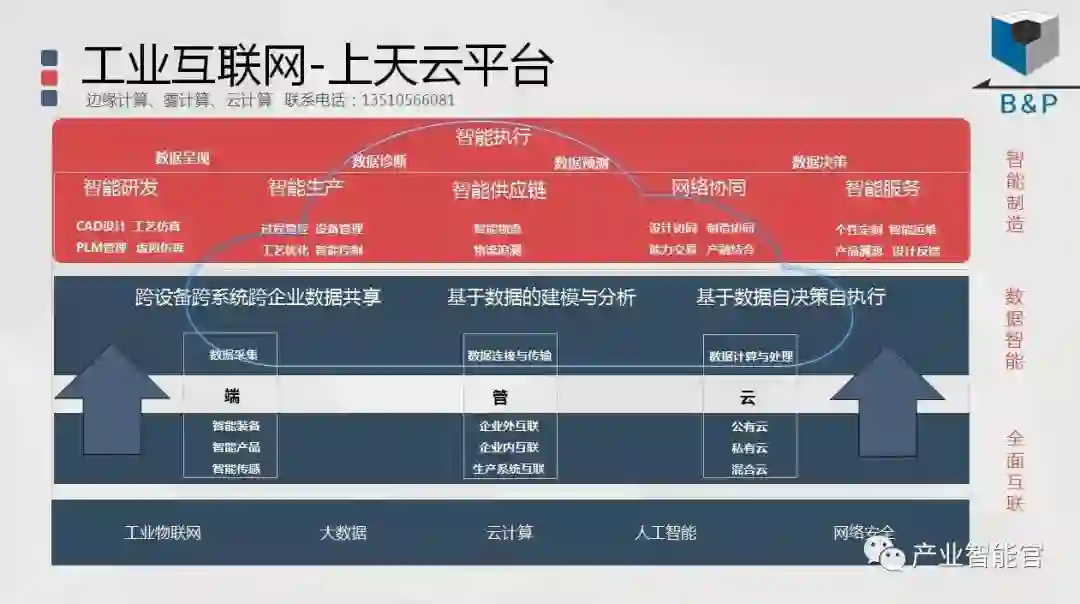
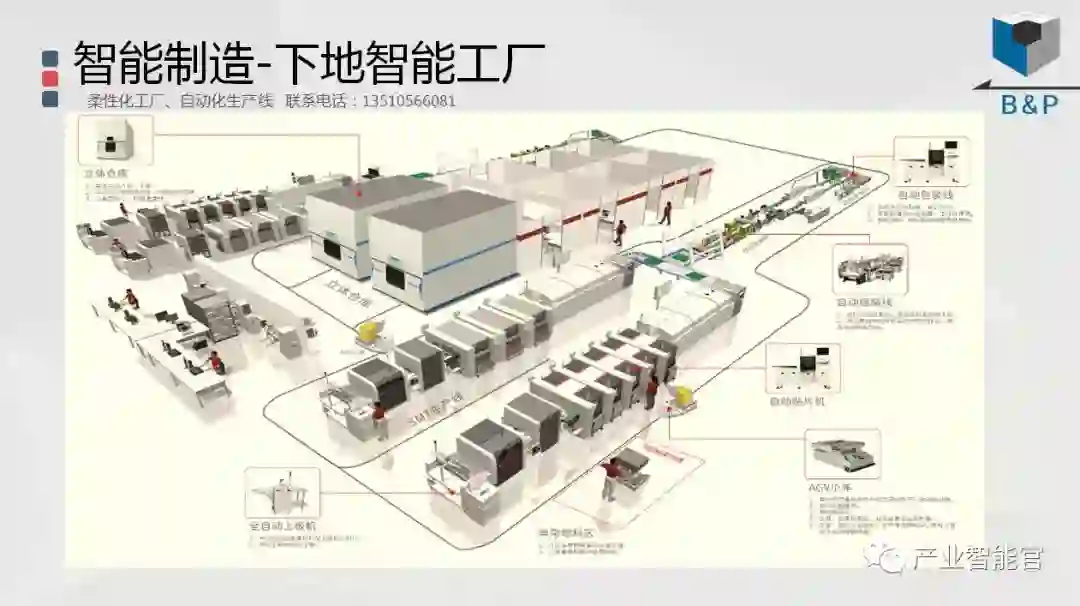
工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。




