NeurIPS 2021 Spotlight | 针对有缺失坐标的聚类问题的核心集


关键词:核心集,聚类问题,缺失坐标

导 读
本文是《针对有缺失坐标的聚类问题的核心集(Coresets for Clustering with Missing Values)》的解读。该工作为带有多个缺失坐标的 k-聚类问题,特别是 k-means,设计第一个有理论保证的、可在近线性时间构造的核心集(coreset)。我们的核心集可以用来加速一个最近的 SODA 2021 结果,从而得到第一个带缺失坐标k-means问题的近线性时间近似方案。本工作还提供相应的实验来证明算法的实用性。
本文被 NeurIPS 2021 接收为 Spotlight(top 3%),论文共同作者为约翰霍普金斯大学副教授 Vladimir Braverman,北京大学助理教授姜少峰,以色列魏茨曼科学研究所教授 Robert Krauthgamer 和约翰霍普金斯大学博士生吴旋。按照理论计算机科学界的习惯,论文作者按照姓氏的首字母排序。

论文地址:
https://www.zhuanzhi.ai/paper/fbcc67171ac1a666645f7612458b9575
01
问题介绍
坐标缺失在实际数据集中是很常见的现象,处理带缺失坐标的数据是数据科学中的重要挑战。常见的处理数据缺失的方法是数据插补(data imputation),亦即利用某些先验知识或者统计假设来尝试补齐缺失的数据。然而,这种方法必须基于某些假设,而这些假设未必可以有效获得或被可靠验证。因此,我们考虑一种针对最坏情况且不基于任何假设的处理方法:对于两个具有缺失坐标的点 x 和 y(假设缺失坐标用

我们考虑针对带缺失坐标聚类问题的核心集(coreset)。粗略来说,一个
02
主要结果
我们的主要结果是一个针对 k-means 问题的大小为:
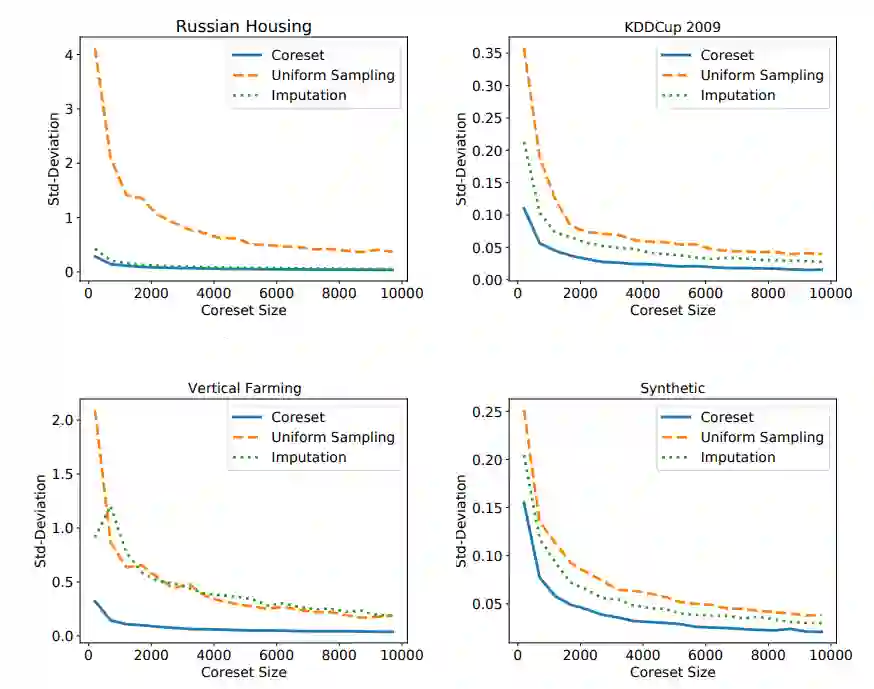
另外,我们还在若干数据集上测试了我们的核心集的实际性能,并与简单均匀采样构造核心集,以及基于数据插补的核心集等两种基线方法进行对比。我们发现对于每个数据集,我们的方法均优于另两个基线方法,并且一个中等大小、大概2000点的核心集即可达到5%-20%不等的误差。
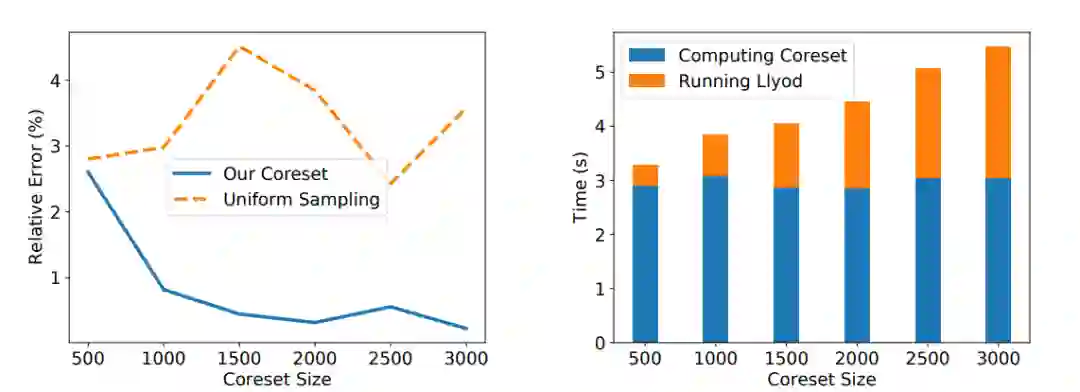
我们进一步用这个核心集来加速一个基于经典的 Lloyd 算法的聚类算法,我们观察到了5倍以上的加速以及仅有大约1%的相对误差。
03
方法和技术创新
构造核心集最有效的方法是由 [Feldman and Langberg, STOC 11] 提出、并在一系列工作中持续改进的依重要性采样(important sampling)方法。该方法已经成功地被应用在大量聚类问题核心集的构造上。大体来说,该方法首先针对每个数据点 x 计算一个重要性分数
然而,具体到本问题,应用该方法存在一些明显的困难。其中最大的困难是在有多个坐标缺失的情况下,由于缺乏三角不等式,数据点的重要性分数不能使用传统方法计算。因此,我们采用了一种较为不常见、但是可以适用于不带三角形不等式距离度量的计算重要性分数的方法(该方法在 [Varadarajan and Xiao, SODA 12] 中提出)。具体来说,该方法将重要性分数的计算问题归约到了针对数据的若干子集来有效构造 k-center 核心集上。为有效构造这种 k-center 的核心集,我们采用如下两个关键步骤,并且这两个步骤也是我们的主要技术创新。
1. 我们给出了一种从带缺失坐标的 k-center 问题的核心集,到传统 k-center 问题的核心集的规约。具体来说,我们随机抽取若干个坐标子集,然后对于每个坐标子集,我们将数据限制在该子集上来构造一个不带缺失坐标的新数据集。我们证明在每个新(不带缺失坐标的)数据集上计算 k-center 核心集后再取并,即可得到一个原(带缺失坐标)数据集的 k-center 核心集。该方法的技术核心是利用一种组合数学技术来给出算法需要用到的坐标子集个数的上界。该上界直接影响了核心集的大小。
2. 由于我们需要针对若干子集反复构造 k-center 核心集,直接套用传统的 k-center 核心集构造方法将仅能得到平方时间的算法。因此,为在近线性时间内针对所有需要的子集构造 k-center 核心集,我们设计了一种专门针对传统 k-center 核心集构造的动态算法。该动态算法能够在

图文 | 姜少峰、吴旋
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CCMV” 就可以获取《NeurIPS 2021 Spotlight | 针对有缺失坐标的聚类问题的核心集》专知下载链接






