开域聊天机器人技术介绍(未来篇:上)

前面的文章 “开域聊天机器人技术介绍(现实篇)” 以微软小冰的技术架构为例详细介绍了目前工业界实用的聊天机器人是如何工作的。使用这种复杂架构的原因是现在的技术水平只能利用这种方法来平衡系统的智能性和可控性。但大家都憧憬着能通过深度学习构建端到端的开域聊天机器人。虽然不少研究团队在这方面一直努力着,但直到最近,Google的Meena 和 Facebook的Blender 才让我(们)看到了这条路的希望。个人认为 Meena 和 Blender 最大的贡献,就是验证了端到端这条路真的走得通。相信接下来的一两年内会有很多大公司在这方面做出很多有意思的工作,进一步提升聊天机器人的对话能力。
本文主要介绍 Google Meena(未来篇:上)和 Facebook Blender(未来篇:下)这两个工作,它们分别发表于今年1月和4月(他们远程办公的效率看来很高)。这两篇论文在模型方面都没有什么创新,但融合了很多有意思的技术,这些模型之外的技术值得做对话的同学了解一下。期望大家阅读完后跟我一样,对端到端的开域聊天机器人更有信心。现在大概是聊天机器人的 GPT-1 时代,谁会开启聊天机器人的 BERT 时代呢?
Google Meena
模型
Meena(论文 “Towards a Human-like Open-Domain Chatbot”)的seq2seq模型每层使用的是Evolved Transformer (ET) 块。Encoder端使用了1个ET层(相当于2层 Transformer),Decoder端使用了13个ET层(相当于26层 Transformer)。相比于GPT-2训练使用了40GB的文档数据,Meena训练使用了341GB的对话数据。Meena的模型参数规模达到了2.6B,在GPT-2的基础上又大了不少。
Meena的训练样本格式为 (context, response),其中 context 由前几轮(最多7轮)对话拼接而成。训练使用的是标准的MLE。
Decoding阶段有两种方法:Beam Search和Sampling方法。其中sampling有两种常用方法:
top-k sampling:每个时间步从top-k个候选词中按概率选取一个词;
sample-and-rank:抽样N次获得N个候选回复句子,然后从中选取概率最高的结果。抽样使用带温度的softmax分布:
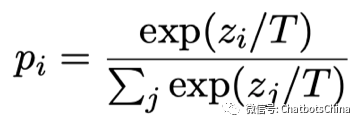
Meena使用了sample-and-rank的抽样方法,论文中选取 N = 20, T = 0.88。
评估方法
模型评估一般包括自动评估和人为评估。自动评估最常用的是decoder上的混淆度Perplexity (PPL):
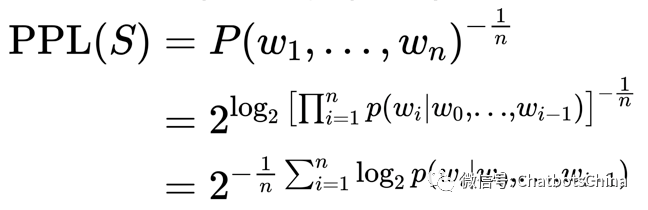
Meena的一大贡献是定义了一种新的人为评估方法,叫 Sensibleness and Specficity Average (SSA),它是以下两个值的平均值:
Sensibleness:回复合理;符合逻辑、保持一致性
Specficity:回复具体,有内容
评估时针对一个session里机器人的每个回复先问此回复是否合理,合理的话再问回复是否具体。
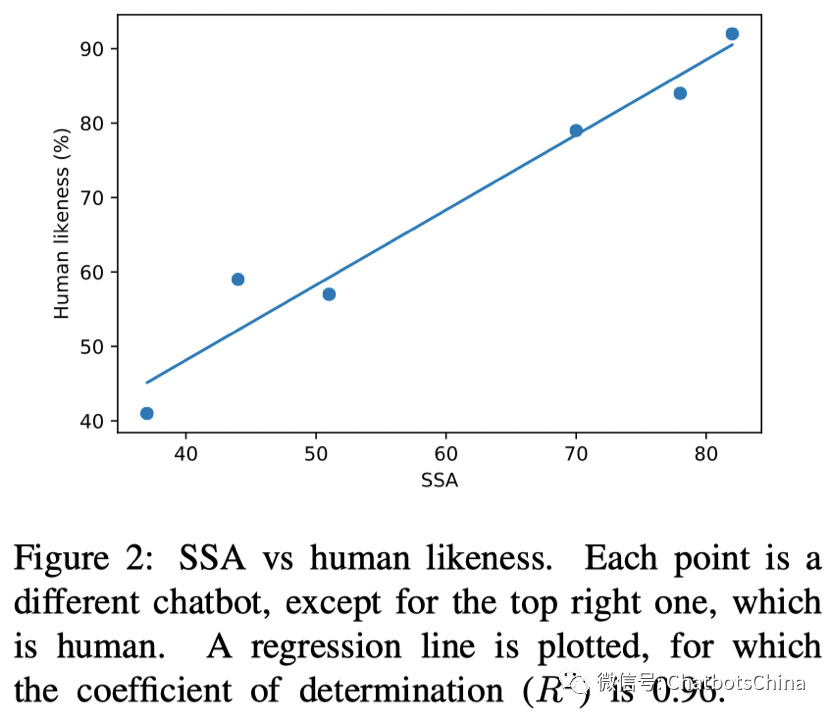
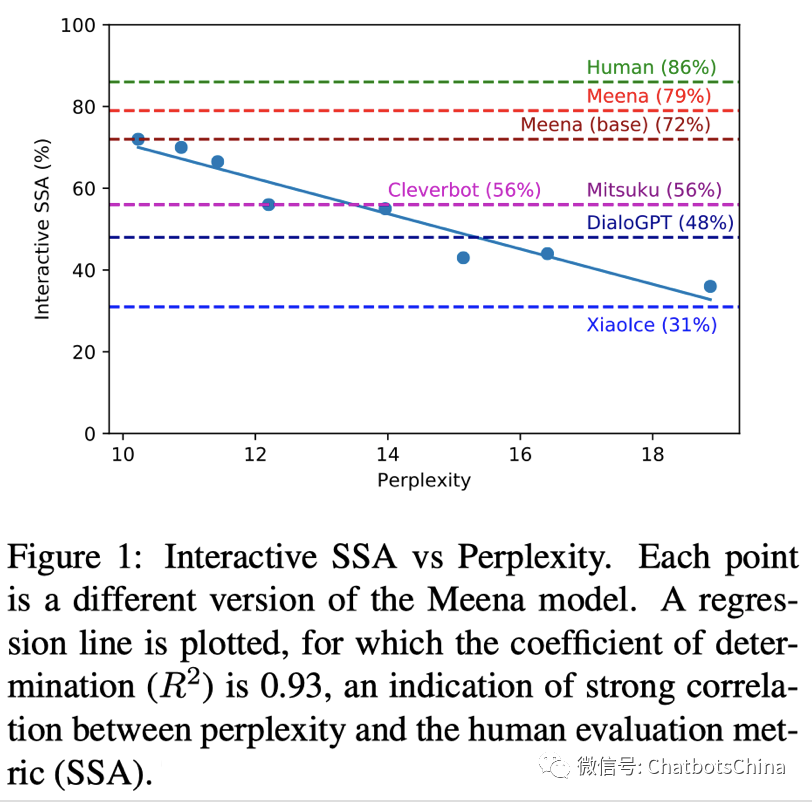
论文首先验证了SSA和人对机器人的喜好程度是正相关的,也就是真的可以用SSA评价一个聊天机器人的好坏。图中最右边的点对应的是人,其他的点对应不同的机器人。
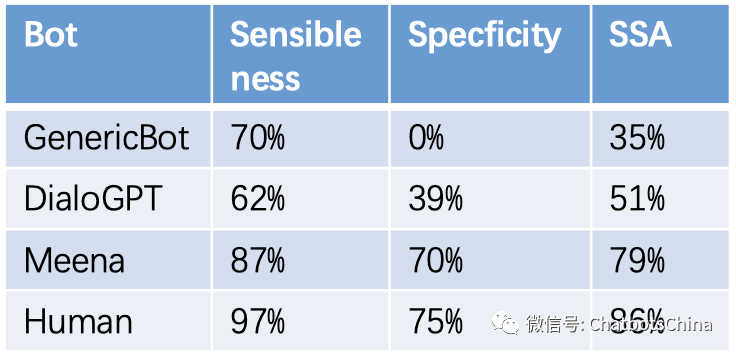
以下表格中给出了上图中部分机器人的具体数值。GenericBot 是作者创建的一个基准机器人,它对所有问句都回答 “I don’t know”,对所有陈述句都回答 “ok”。可见SSA的定义还是比较合理的。
接着,作者验证了SSA与PPL是高度负相关的,即PPL越低,SSA就越高。这样以后评价机器人好坏就不用费力做人为评估了,只要看PPL就行了。当然,这个结论有人是不认同的,存在PPL低的机器人反而比PPL高的机器人效果更差的情况。下图给出了不同机器人对应的SSA,可见Meena大模型达到了79%,已经接近人类的86%了。小冰要不要这么惨。。估计不久的将来小冰团队会有反杀工作发布,当然前提是小冰的研究团队还在。
示例
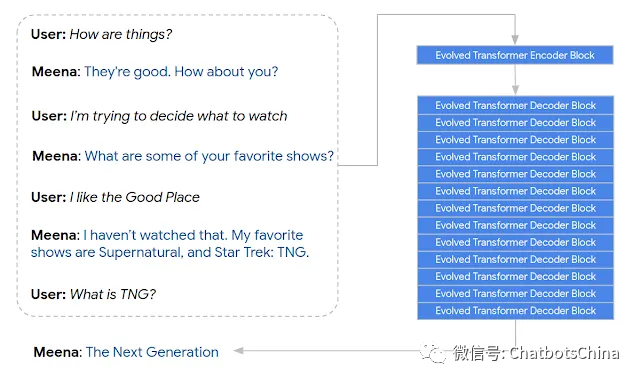
以下是Meena对话示例,大家可以感受下它的效果:
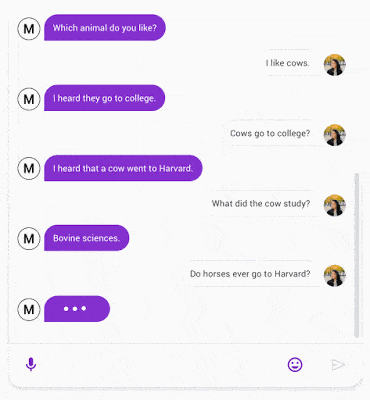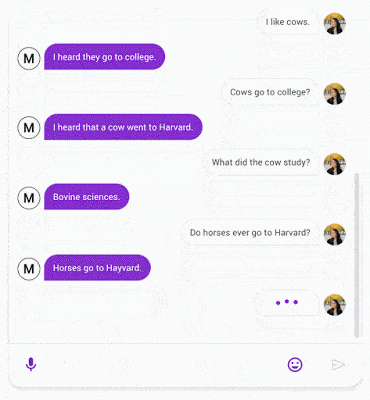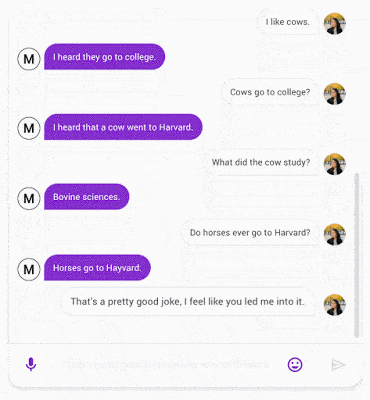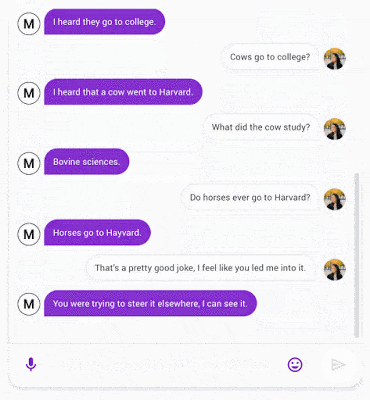
论文中可以找到更多示例。
Meena 总结
作者自己总结的论文三大贡献:
提出了评估多轮对话效果的指标SSA;
PPL和SSA高度负相关,所以可用PPL自动评估模型效果;
足够大的端到端模型可以打败复杂架构的对话系统。
最后一条最重要,其他两条其实都没获得普遍的支持。





