SIGIR 2018 | 大会最佳短论文:利用对抗学习的跨域正则化
选自arXiv
作者:Daniel Cohen等
机器之心编译
参与:路、李泽南
ACM 国际信息检索研究与发展会议 SIGIR 2018 近日于美国密歇根州 Ann Arbor 举行。目前,大会已公布最佳论文等奖项,马德里自治大学(Universidad Autónoma de Madrid)的论文《Should I Follow the Crowd? A Probabilistic Analysis of the Effectiveness of Popularity in Recommender Systems》获得了最佳论文奖,微软与马萨诸塞大学阿姆赫斯特分校合作论文《Cross-Domain Regularization for Neural Ranking Models Using Adversarial Learning》获得最佳短论文奖。本文将对最佳短论文进行简要介绍。
1 引言
近期学界有多个神经排序模型被提出,这些模型通过考虑原始查询-文档文本(query-document text)[14]、基于确切的查询词项匹配文档的模式 [5],或结合二者 [10] 来估计文档与查询之间的相关性。这些模型通常通过在训练过程中观察大量相关和不相关的样本,来学习区分对应相关查询-文档对和相关性较低的查询-文档对的输入特征分布。与依赖人工制作特征的传统学习排序(LTR)模型不同,这些深度神经模型直接从数据中学习可用于目标任务的更高级别表征。它们从训练数据中学习特征的能力是一个强大的属性,使之有潜力发现手动制作特征没有捕获的新关系。
但是,正如 Mitra 和 Craswell [9] 所讨论的那样,学习新特征的能力可能以在训练过程未涉及域上的较差泛化能力和性能为代价。例如,模型可能观察到某一对短语在训练语料库中同时出现的频率比其他短语高,如「Theresa May」和「Prime Minister」。或者,模型可能基于短语在训练查询中共现的相对频率,推断得到学习「Theresa May」的优秀表征比学习「John Major」的表征更加重要。尽管要想在单个域中取得最佳性能这些相关性和分布很重要,但是如果我们更关心模型在未见过域上的性能,那么模型必须学习对未见域具备更强的鲁棒性。与之相反,传统的检索模型(如 BM25 [12])和 LTR 模型通常在跨域性能方面展示出较强的鲁棒性。
本研究的目标是训练从数据中学习有用表征的深度神经排序模型,且不会与训练域的分布产生「过拟合」。近期,对抗学习已经被证实是一个适合分类任务的有效跨域正则化项 [3, 17]。本论文研究者对此进行调整,提出一种类似策略,可使神经排序模型学习对不同域具备更强鲁棒性的表征。研究者在小型域集合上训练神经排序模型,并在留出域上评估模型性能。训练过程中,研究者结合神经排序模型和对抗判别器,后者尝试基于排序模型学习到的表征预测训练样本的域。当反向传播通过排序模型的层时,对抗判别器的梯度被逆转。这向排序模型提供了负反馈,阻止它学习仅对特定域有意义的表征。实验证明该对抗训练在留出域上的排序性能有一致的改进,有时甚至实现高达 30% 的 precision@1 改进。
3 利用对抗学习的跨域正则化
对抗判别器的动机是使神经模型学习独立于域的特征,这些特征有助于估计相关性。传统神经排序模型的训练目的仅仅是优化相关性评估,无视内部学到的特征的本质。本论文研究者提出使用对抗智能体,通过在流形上域特定空间上调整模型参数方向(至相反方向)来使排序模型学到的特征独立于域。这种通过域混淆(domain confusion)[17] 的跨域正则化可以用以下联合损失函数来表示:
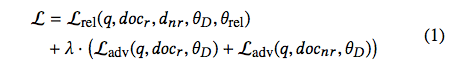
其中 L_rel 是基于损失函数的相关性,L_adv 是对抗判别器损失。q、docr 和 docnr 分别是查询、相关文档和无关文档。最后,θ_rel 和 θ_D 分别是相关性模型和对抗模型的参数。λ 决定域混淆损失对优化过程的影响程度。研究者将其作为训练过程中的一个超参数。排序模型在多个训练域 D_train = {d_1, . . . ,d_k } 上进行训练,在留出域 D_test = {d_k+1 , . . . ,d_n } 上进行评估。
判别器是检查排序模型隐藏层输出的分类器,且尝试预测训练样本的域 d_true ∈ D_train。判别器使用标准交叉熵损失进行训练。
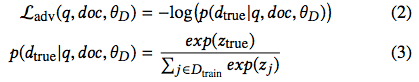
梯度更新通过在所有后续层上的反向传播来执行,包括属于排序模型的层。但是,研究者利用了梯度逆转层(gradient reversal layer,Ganin et al. [3])。该层将标准梯度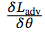
行人检索模型。研究者在行人检索任务上评估了该对抗学习方法。他们使用 Tan 等人 [16] 提出的神经排序模型(下文中用 CosSim 指代)和 Duet 模型 [10] 作为基线模型。本论文重点是学习独立于域的文本表征。因此,与 Zamani et al. [20] 类似,本研究仅考虑 Duet 模型的分布式子网络。
CosSim 模型是一个基于 LSTM 的交互作用架构。研究者使用 [16] 的方法训练 CosSim 模型,得到了比 hinge 损失函数高出 0.2 的结果。按照 [10] 提出的方法,通过最大化正确行人的对数似然来训练 Duet-distributed 模型。与 [11] 类似,研究者调整 Duet 模型的超参数,以适应行人检索任务。经过最大池化表征,哈达玛积(Hadamard product)的输出被显著降低,查询长度从 8 个 token 扩展到 20 个,最大文档长度从初始的 1000 个 token 减少到 300。
与之前使用对抗方法的研究 [3, 6, 17] 不同,排序需要建模查询和文档之间的互动。如图 1a 所示,在该设置中,对抗判别器检查神经排序模型学到的查询-文档联合表征。对于更深的架构,如 Duet-distributed 模型,研究者允许判别器在排序模型中检查额外的层,如图 1b 所示。
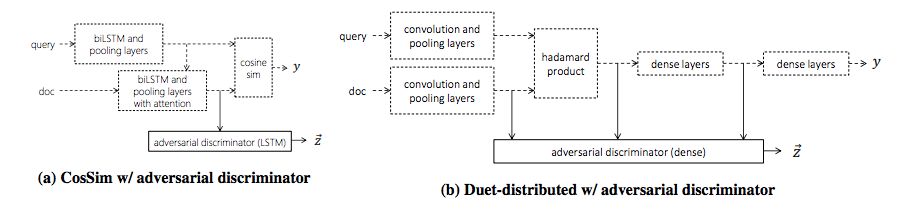
图 1:两个基线模型(CosSim 和 Duet-distributed)使用对抗判别器的跨域正则化。判别器检查排序模型学到的表征,并对任意帮助域判别的表征提供负反馈信号。
5 结果和讨论
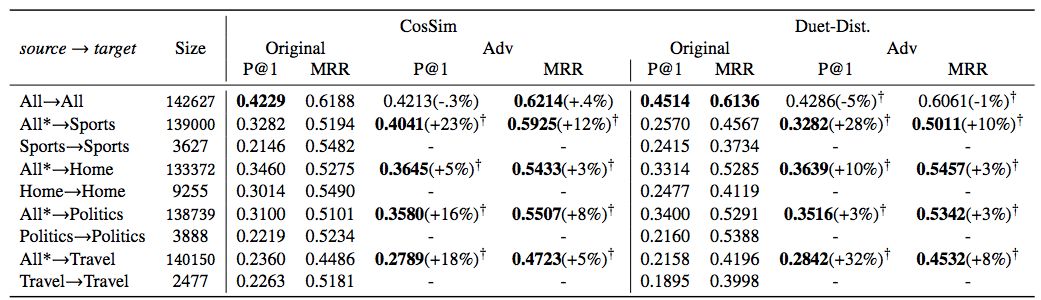
表 1:模型在 L4 topics 上的表现,每个集合下的度量指标表示在其他两个集合上训练的模型的性能。All*指整个 L4 集合(删除了目标话题)。† 表示相比非对抗模型的显著性能提升(p < 0.05,Wilcoxon 检验)。

表 2:跨集合的性能,每个集合下的性能代表在其他两个集合上训练的模型的性能。† 表示相比非对抗模型的显著性能提升(即 p<0.05,Wilcoxon 检验)
论文:Cross Domain Regularization for Neural Ranking Models Using Adversarial Learning

论文链接:https://arxiv.org/abs/1805.03403
摘要:与传统学习排序模型依赖于手动制作特征的情况不同,神经表征学习模型通过在大型数据集上的训练,为排序任务学习更高级别的特征。然而,这种直接从数据中学习新特征的能力可能得付出代价。在没有任何特殊监督的情况下,这些模型可以学到仅在训练数据采样领域中存在的关系,却很难泛化至训练期间未观察到的领域。我们在排序任务上研究了将对抗学习作为跨域正则化项的有效性。我们使用对抗判别器在少量域上训练我们的神经排序模型,判别器提供负反馈信号以阻止模型学习域特定的表征。我们的实验表明,在使用对抗判别器时,模型在留出域上的表现始终更好——有时甚至实现高达 30% 的 precision@1 改进。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




