
强化学习定义了仅通过行动和观察来学习做出好的决策的代理所面临的问题。为了成为有效的问题解决器,这些代理必须能有效地探索广阔的世界,从延迟的反馈中分配信用,并归纳出新的经验,同时要利用有限的数据、计算资源和感知带宽。抽象对所有这些努力都是必要的。通过抽象,代理可以形成其环境的简洁模型,以支持一个理性的、自适应的决策者所需要的许多实践。在这篇论文中,我提出了强化学习中的抽象理论。首先,我提出了执行抽象过程的函数的三个要求:它们应该1)保持近似最优行为的表示,2) 有效地被学习和构造,3) 更低的规划或学习时间。然后,我提出了一套新的算法和分析,阐明了代理如何根据这些需求学习抽象。总的来说,这些结果提供了一条通向发现和使用抽象的部分路径,将有效强化学习的复杂性降到最低。
强化学习问题如下。RL代理通过以下两个离散步骤的无限重复与环境进行交互:
- 代理收到观察和奖励。
- 代理从这种交互中学习并执行一个动作。 这个过程如图1.2所示。在这种互动过程中,agent的目标是做出决策,使其获得的长期报酬最大化。
论文余下组织如下: 第1部分。在第2章中,我提供了关于RL(2.1节)以及状态抽象(2.2节)和动作抽象(2.3节)的必要背景知识。
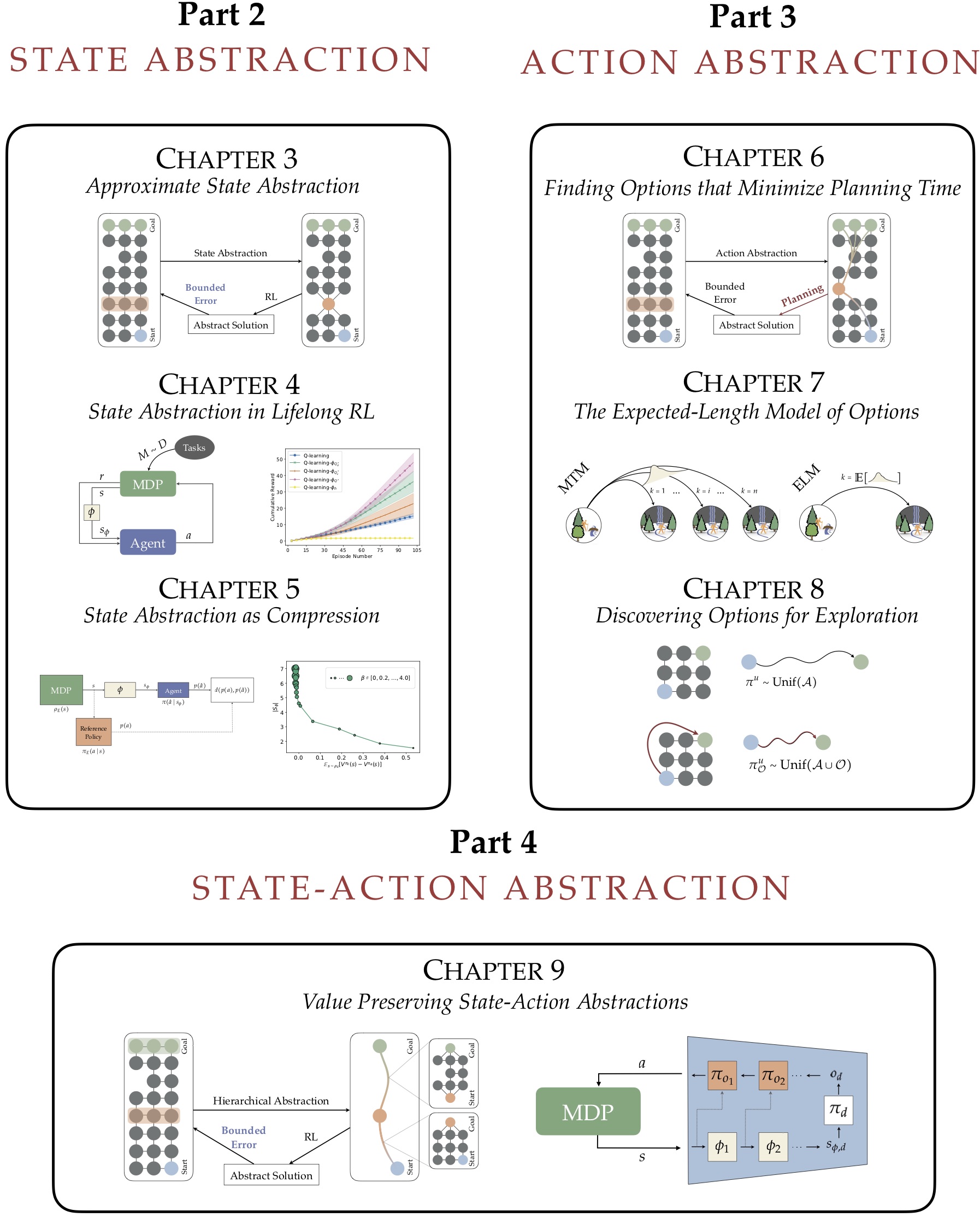
第2部分。下一部分将专注于状态抽象。我提出了新的算法和三个紧密相连的分析集,每一个目标是发现满足引入的需求的状态抽象。在第3章中,我开发了一个形式化的框架来推理状态抽象,以保持近似最优的行为。这个框架由定理3.1总结,它强调了值保持状态抽象的四个充分条件。然后,在第4章中,我将这一分析扩展到终身RL设置,在终身RL设置中,代理必须不断地与不同的任务交互并解决不同的任务。本章的主要观点是介绍了用于终身学习设置的PAC状态抽象,以及澄清如何有效计算它们的结果。定理4.4说明了保证这些抽象保持良好行为的意义,定理4.5说明了有多少以前已解决的任务足以计算PAC状态抽象。我着重介绍了模拟实验的结果,这些结果说明了所介绍的状态抽象类型在加速学习和计划方面的效用。最后,第五章介绍了信息论工具对状态抽象的作用。我提出了状态抽象和率失真理论[283,43]和信息瓶颈方法[318]之间的紧密联系,并利用这种联系设计新的算法,以高效地构建状态抽象,优雅地在压缩和良好行为表示之间进行权衡。我以各种方式扩展了这个算法框架,说明了它发现状态抽象的能力,这些状态抽象提供了良好行为的样本高效学习。
第3部分。然后我转向行动抽象。在第6章中,我展示了Jinnai等人的分析[144],研究了寻找尽可能快地做出计划的抽象动作的问题——主要结果表明,这个问题通常是NP困难的(在适当简化的假设下),甚至在多项式时间内很难近似。然后,在第7章中,我解决了在规划中伴随高层次行为构建预测模型的问题。这样的模型使代理能够估计在给定状态下执行行为的结果。在本章中,我将介绍并分析一个用于这些高级行为的新模型,并证明在温和的假设下,这个简单的替代仍然是有用的。我提供的经验证据表明,新的预测模型可以作为其更复杂的对等物的适当替代者。最后,在第8章中,我探讨了抽象行动改善探索过程的潜力。我描述了Jinnai等人开发的一种算法[145],该算法基于构建可以轻松到达环境所有部分的抽象行动的概念,并证明该算法可以加速对基准任务的探索。
第4部分。最后,我转向状态动作抽象的联合过程。在第9章中,我介绍了一个将状态和动作抽象结合在一起的简单机制。使用这个方案,然后我证明了哪些状态和动作抽象的组合可以在任何有限的MDP中保持良好的行为策略的表示,定理9.1总结了这一点。接下来,我将研究这些联合抽象的反复应用,作为构建分层抽象的机制。在对层次结构和底层状态动作抽象的温和假设下,我证明了这些层次结构也可以保持全局近最优行为策略的表示,如定理9.3所述。然后,我将在第十章中总结我的思考和今后的方向。
总的来说,这些结果阐明了强化学习的抽象理论。图1.4展示了本文的可视化概述。

