【深度学习】深度学习与神经科学相遇
深度学习与神经科学相遇(一)
开始之前看一张有趣的图 – 大脑遗传地图:
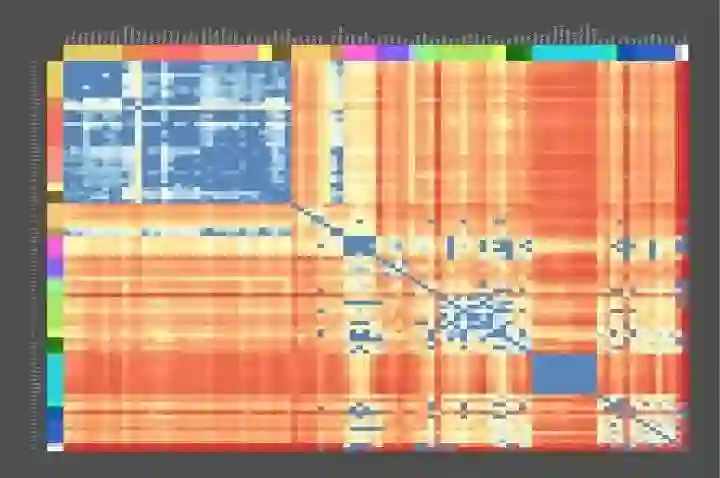
Figure 0. The Genetic Geography of the Brain – Allen Brain Atlas
成年人大脑结构上的基因使用模式是高度定型和可再现的。 Figure 0 中所示的动态热图表示跨个体的这种图案化模式的共同结构,特别是一些介于解剖区域对(pairs of anatomic regions)之间差异表达的基因数目,在我们的实验测量中,有5/6的大脑中发现了类似共同的模式。 热红色阴影代表在其转录调节中非常不同的脑区域,而较冷的蓝色阴影代表高相似性的区域。
先看这张图的用意是在于让读者了解目前大脑、神经科学的前沿,人类不仅具有了解全部大脑基本功能的能力,并且已经具备将各功能区域映射到自身遗传物质编码上的能力。不仅如此,更多先进的探测技术已经能让人们记录下更详细的神经元内部的活动(dynamics),这使得对大脑内部计算结构的分析成为可能,上图所示内容凝结了众多科学家的努力,相信一定是21世纪最伟大的科学突破之一。
说明:
1. 翻译这篇文章出于学习目的,有翻译或者理解有误的地方还望大家多多指教;
2. 本文可以任意转载,支持知识分享,但请注明出处或附上原文地址;
3. 文章中所有的引用都在本文内嵌链接中可以找到,该论文有488篇引用!
4. 翻译将进行连载,这是系列的第一部分,对应论文第一章;
Standing on the shoulders of giants, to touch the hands of “god”.
引言
计算神经科学专注于计算的详细实现,研究神经编码、动力学和电路。然而,在机器学习中,人工神经网络倾向于避开较精确设计的代码,动力学或电路,有利于成本函数的强力优化(暴力搜索),通常使用简单和相对均匀的初始架构。在机器学习中,近期的两个发展方向创造了连接这些看似不同观点的机会。首先,使用结构化体系架构,包括用于注意力机制,递归和各种形式的短期和长期存储器存储的专用系统(Specialized System)。第二,成本函数和训练过程变得更加复杂,并且随着时间的推移而变化。在这里我们根据这些想法思考大脑。我们假设(1)大脑优化成本函数,(2)成本函数是多样的且在不同的发展阶段大脑不同位置的成本函数是不同的,和(3)优化操作是在一个由行为预先架构好的、与对应计算问题相匹配的框架内执行。为了支持这些假设,我们认为通过多层神经元对可信度分配(Credit Assignment)的一系列实现是与我们当前的神经电路知识相兼容的,并且大脑的一些专门系统可以被解释为对特定问题实现有效的优化。通过一系列相互作用的成本函数,这样非均匀优化的系统使学习过程变得数据高效,并且较精确地针对机体的需求。我们建议一些神经科学的研究方向可以寻求改进和测试这些假设。
这里提到的相互作用的成本函数非常有趣,在目前的深度学习领域,使用多目标函数的学习任务包括multi-task learning,transfer learning,adversarial generative learning等,甚至一些带约束条件的优化问题都可以一定程度上看做是多目标函数的。(“目标函数”是旨在最小化成本的函数,论文中使用成本函数,而所有的智能学习过程都是旨在降低各种成本函数值,比较普遍地人们会使用“信息熵”来作为量化标准,那么学习就可以看做是降低不确定性的行为)更有趣的是怎么相互作用?相互作用的目标函数对学习过程有怎样的帮助?
1. 介绍
今天的机器学习和神经科学使用的并不是同一种“语言”。 脑科学发现了一系列令人眼花缭乱的大脑区域(Solari and Stoner, 2011)、细胞类型、分子、细胞状态以及计算和信息存储的机制。 相反,机器学习主要集中在单一原理的实例化:函数优化。 它发现简单的优化目标,如最小化分类误差,可以导致在在多层和复现(Recurrent)网络形成丰富的内部表示和强大的算法能力(LeCun et al., 2015; Schmidhuber, 2015)。 这里我们试图去连接这些观点。
如今在机器学习中突出的人工神经网络最初是受神经科学的启发(McCulloch and Pitts, 1943)。虽然此后神经科学在机器学习继续发挥作用(Cox and Dean, 2014),但许多主要的发展都是以有效优化的数学为基础,而不是神经科学的发现(Sutskever and Martens,2013)。该领域从简单线性系统(Minsky and Papert, 1972)到非线性网络(Haykin,1994),再到深层和复现网络(LeCun et al., 2015; Schmidhuber, 2015)。反向传播误差(Werbos, 1974, 1982; Rumelhart et al., 1986)通过提供一种有效的方法来计算相对于多层网络的权重的梯度,使得神经网络能够被有效地训练。训练神经网络的方法已经改进了很多,包括引入动量的学习率,更好的权重矩阵初始化,和共轭梯度等,发展到当前使用分批随机梯度下降(SGD)优化的网络。这些发展与神经科学并没有明显的联系。
然而,我们将在此论证,神经科学和机器学习都已经发展成熟到了可以再次“收敛”(交织)的局面。 机器学习的三个方面在本文所讨论的上下文中都显得特别重要。 首先,机器学习侧重于成本函数的优化(见Figure 1)。
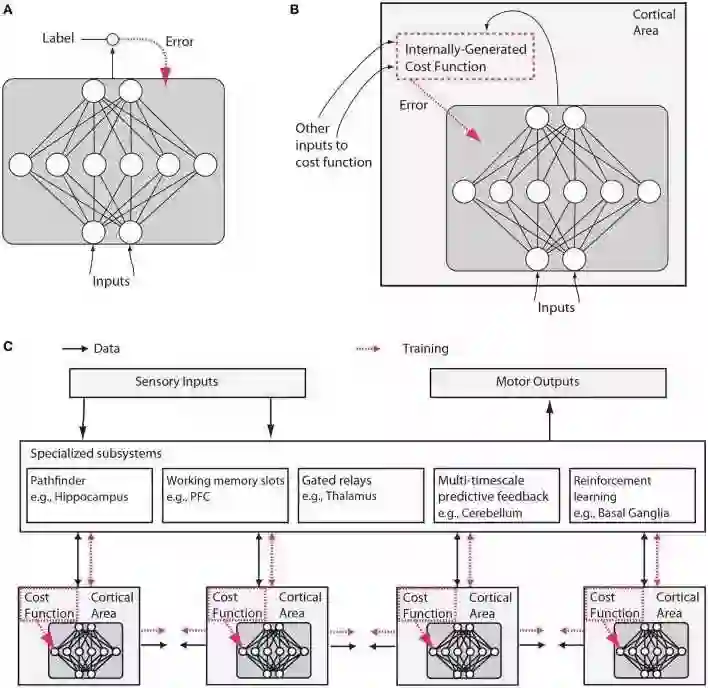
Figure 1. 传统人工神经网络和类脑神经网络设计之间的假设差异。 (A)在常规深度学习中,监督训练基于外部提供的标记数据。 (B)在大脑中,网络的监督训练仍然可以通过对误差信号的梯度下降发生,但是该误差信号必须来自内部生成的成本函数。这些成本函数本身是由遗传基因和后天学习所指定的神经模块计算而来。内部生成的成本函数创建heuristics(这个实在不好翻译,“启发”有些抽象,类似于元信息,大家意会吧),用于引导更复杂的学习。例如,识别面部的区域可以首先使用简单的heuristic来训练以来检测面部,这种heuristic就比如是在直线之上存在两个点,然后进一步训练以使用来自无监督学习的表示结合来自其他与社交奖励处理相关的大脑区域的错误信号来区分显著的面部表情。 (C)内部生成的成本函数和错误驱动的神经皮质深层网络经过训练形成包含几个专门系统的较大架构的一部分。虽然可训练皮层区域在这里被示意为前馈神经网络,但是LSTM或其他类型的recurrent网络可能才是更较精确的比喻,并且许多神经元和网络性质例如神经脉冲、树突计算、神经调节、适应和稳态可塑性、定时依赖性可塑性、直接电连接、瞬时突触动力、兴奋/抑制平衡、自发振荡活动、轴突传导延迟(Izhikevich, 2006)等将影响这些网络学习的内容和方式。
这里说到的“来自无监督学习的表示”可以用人工智能里的知识表示来理解,来自大脑其他区域的错误信号也是一种表示,所以他们可以结合。深度学习中我们用实值张量来表示知识,个人认为knowledge representation是智能形成最基础的核心之一。C中描述的结构与《On Intelligence》中作者提到的”柱状体“神经网络非常类似。结尾的一大串神经动力学名词真是又一次让我深深感受到自己的无知…
第二,近来在机器学习中的工作开始引入复杂的成本函数:在层和时间上不一致的成本函数,以及由网络的不同部分之间的交互产生的那些函数。 例如,引入低层的时间相干性(空间上非均匀成本函数)的目标改进了特征学习(Sermanet and Kavukcuoglu, 2013),成本函数计划(时间上非均匀成本函数)改进了泛化能力(Saxe et al., 2013; Goodfellow et al., 2014b; Gülçehre and Bengio, 2016)以及对抗网络 – 内部交互作用产生的成本函数的一个例子 – 允许生成式模型基于梯度训练(Goodfellow et al., 2014a)。 更容易训练的网络正被用于提供“提示”,以帮助引导更强大的网络的训练(Romero et al., 2014)。
第三,机器学习也开始多样化进行优化的架构。 它引入了具有多重持久状态的简单记忆细胞(Hochreiter and Schmidhuber, 1997; Chung et al., 2014),更复杂的基本计算结构单元如“胶囊”和其他结构(Delalleau and Bengio, 2011; Hinton et al., 2011; Tang et al., 2012; Livni et al., 2013),内容可寻址性(Graves et al., 2014; Weston et al.,2014)和位置可寻址存储器(Graves et al., 2014),另外还有指针 (Kurach et al., 2015)和硬编码算术运算(Neelakantan et al., 2015)。
这三个想法到目前为止在神经科学中没有受到很多关注。 因此,我们将这些想法形成为关于大脑的三个假设,检查它们的证据,并且描绘可以如何测试它们的实验。 但首先,我们需要更准确地陈述假设。
1.1 假设1 – 大脑进行成本函数优化
连接两个领域的中心假设是,像许多机器学习系统一样,生物系统能够优化成本函数。成本函数的想法意味着大脑区域中的神经元可以以某种方式改变它们的属性,例如它们的突触的属性,使得它们在做任何成本函数定义为它们的角色时更好。人类行为有时在一个领域中达到最优,例如在运动期间(Körding, 2007),这表明大脑可能已经学习了较佳策略。受试者将他们的运动系统的能量消耗最小化(Taylor and Faisal, 2011),并且使他们的身体的风险和损害最小化,同时较大化财务和运动获益。在计算上,我们现在知道轨迹的优化为非常复杂的运动任务提出了非常不错的解决方案(Harris and Wolpert, 1998; Todorov and Jordan, 2002; Mordatch et al., 2012)。我们认为成本函数优化更广泛地发在大脑使用的内部表示和其他处理过程之中。重要的是,我们还建议这需要大脑在多层和recurrent网络中具备有效的信用分配(credit assignment,感觉翻译成中文还是有些奇怪)机制。
1.2 假设2 – 不同的发展阶段中不同大脑区域的成本函数不同
第二个假设的另一种表达是:成本函数不需要是全局的。 不同脑区域中的神经元可以优化不同的事物,例如,运动的均方误差、视觉刺激中的惊喜或注意分配。 重要的是,这样的成本函数可以在局部大脑区域生成。 例如,神经元可以局部评估其输入的统计模型的质量(Figure1B)。 或者,一个区域的成本函数可以由另一个区域生成。 此外,成本函数可以随时间改变,例如,神经网络先指导小孩早期理解简单的视觉对比度,稍后再进行面部识别。 这可以允许发展中的大脑根据更简单的知识来引导更复杂的知识。 大脑中的成本函数是非常复杂的,并且被安排成在不同地区和不同发展之间变化。
1.3 假设3 – 专门系统提供关键计算问题上的高效解
第三个认识是:神经网络的结构很重要。信息在不同大脑区域流动的模式似乎有根本性差异的,这表明它们解决不同的计算问题。一些脑区是高度recurrent的,可能使它们被预定为短期记忆存储(Wang, 2012)。一些区域包含能够在定性不同的激活状态之间切换的细胞类型,例如响应于特定神经递质的持续发射模式与瞬时发射模式(Hasselmo, 2006)。其他区域,如丘脑似乎有来自其他区域的信息流经它们,也许允许他们确定信息路由(Sherman, 2005)。像基底神经节的区域参与强化学习和分离决定的门控(Doya, 1999; Sejnowski and Poizner,2014)。正如每个程序员所知,专门的算法对于计算问题的有效解决方案很重要,并且大脑可能会很好地利用这种专业化(Figure1 C)。
这些想法受到机器学习领域的进展的启发,但我们也认为大脑与今天的机器学习技术有很大的不同。特别是,世界给我们一个相对有限的信息量以让我们可以用于监督学习(Fodor and Crowther, 2002)。有大量的信息可用于无人监督的学习,但没有理由假设会存在一个通用的无监督算法,无论多么强大,将按人们需要知道的顺序较精确学习人类需要知道的事情。因此,从进化的角度来看,使得无监督学习解决“正确”问题的挑战是找到一系列成本函数,其将根据规定的发展阶段确定性地建立电路和行为,使得最终相对少量的信息足以产生正确的行为。例如,一个成长中的鸭子跟随(Tinbergen, 1965)其父母的行为印记模板,然后使用该模板来生成终级目标,帮助它开发其他技能,如觅食。
根据上述内容和其他研究(Minsky, 1977; Ullman et al., 2012),我们认为(suggest)许多大脑的成本函数产生于这样的内部自举过程。事实上,我们提出生物发展和强化学习实际上可以程序化实现生成一系列成本函数,较精确预测大脑内部子系统以及整个生物体面临的未来需求。这种类型的发展程序化地引导生成多样化和复杂的成本函数的内部基础设施,同时简化大脑的内部过程所面临的学习问题。除了诸如家族印记的简单任务之外,这种类型的引导可以扩展到更高的认知,例如,内部产生的成本函数可以训练发育中的大脑正确地访问其存储器或者以随后证明有用的方式组织其动作。这样的潜在引导机制在无监督和强化学习的背景下运行,并且远远超出当今机器学习、人工智能课程学习的理念(Bengio et al.,2009)。
这段是至今我所看过的人工智能文献里最精彩的部分。
本文的其余部分,我们将阐述这些假设。 首先,我们将认为局部和多层优化,出乎意料地与我们所知道的大脑兼容。 第二,我们将认为成本函数在大脑区域和不同时间的变化是不同的,并且描述了成本函数如何以协调方式交互以允许引导复杂函数。 第三,我们将列出一系列需要通过神经计算解决的专门问题,以及具有似乎与特定计算问题匹配的结构的脑区域。 然后,我们讨论上述假设的神经科学和机器学习研究方法的一些影响,并草拟一组实验来测试这些假设。 最后,我们从演化的角度讨论这个架构。
深度学习与神经科学相遇(二)
来源:数盟
2. 大脑能够进行成本函数优化
许多机器学习方法(如典型的监督式学习)是基于有效地函数优化,并且,使用误差的反向传播(Werbos, 1974; Rumelhart et al., 1986)来计算任意参数化函数的梯度的能力是一个很关键的突破,这在下文我们将详细描述。在假设1中,我们声称大脑也是,至少部分是,优化机(optimization machine,指具有优化函数能力的装置)。但是,究竟说大脑可以优化成本函数是什么意思呢?毕竟,许多自然界中的许多过程都可以被视为优化。例如,物理定律通常被认为是最小化一个动作的功能,而进化优化的是复制基因(replicator)在长时间尺度上的适应性。要明确的是,我们的主张是:(a)大脑在学习期间具有强大的信用分配机制,允许它通过调整每个神经元的属性以提升全局输出结果,以此来优化多层网络中的全局目标函数,以及(b)大脑具有确定哪些成本函数对应其哪些子网络的机制,即,成本函数是高度可调的,这是由进化逐步形成并与动物的生理需求相匹配。因此,大脑使用成本函数作为其发展的关键驱动力,就像现代机器学习系统一样。
可能部分读者在系列一中对credit assignment(信用分配)还存在疑惑,这里解释一下:信用分配问题主要考虑的是如何确定系统的整体性能的成功是由系统组件的各种贡献哪些部分决定的(Minsky,1963),这是人工智能先驱Marvin Minsky提出的,本质上应属于对目标函数优化的一部分,实际上神经网络权重调节的机制就是一直信用分配。
为了理解这些主张的基础,我们现在必须深入了解大脑如何有效地执行大型多层网络中的信用分配的细节,以优化更为复杂的函数。我们认为大脑使用几种不同类型的优化来解决不同的问题。在一些结构中,其可以使用遗传基因预先规定的神经回路去解决仅需要基于数据即可快速学习的问题,或者可以利用局部优化以避免通过多层神经元来分配信用的需要。它还可以使用许多后天发展出来的电路结构(神经回路),允许其通过多层神经元网络执行误差的反向传播(这里误差来至于网络实际输出与真实期望值之间的差距),这个过程使用生物学上实际存在的机制是可以实现的 – 曾经一度被广泛认为是不具有生物学可解释性的(Crick, 1989; Stork, 1989)。潜在的此类机制包括:以常规的方式反向传播误差导数(gradient,梯度)的神经电路,以及提供对梯度进行有效估计(gradient approximation,最近也有突破,避免了直接从目标函数开始求导计算)的神经回路,即快速计算成本函数对于任何给定连接权重的近似梯度。最后,大脑可以利用某些特定的神经生理学方面的算法,例如神经脉冲的时间依赖可塑性(spike timing dependent plasticity)、树突计算(dendritic computation)、局部兴奋性抑制网络或其他性质,以及更高级别大脑系统的综合性质。这样的机制可以允许学习能力甚至超过当前基于反向传播的网络。
2.1 无多层信用分配的局部自组织与优化
不是所有的学习过程都需要一个通用的优化机制,如梯度下降。许多关于神经皮质的理论(George and Hawkins, 2009; Kappel et al., 2014)强调潜在的自组织和无监督的学习属性,可以消除多层反向传播的需要。 根据突触前后活动的相关性来调整权重的神经元Hebbian可塑性理论已经被很好的确立。Hebbian可塑性(Miller and MacKay, 1994)有很多版本,例如,加入非线性(Brito and Gerstner, 2016),可以引发神经元之间的不同形式的相关和竞争,导致自我组织(self-organized)的眼优势柱(ocular dominance columns)、自组织图和定向列形成(Miller et al., 1989; Ferster and Miller, 2000)。通常这些类型的局部自组织也可以被视为优化成本函数:例如,某些形式的Hebbian可塑性可以被视为提取输入的主要分量,这最小化重建误差(Pehlevan and Chklovskii, 2015) 。
Auto-encoders 这类人工神经网络就是上述功能的代表。
为了生成复杂的具有时间关联的学习模式,大脑还可以实现任何与不需要通过多层网络的完全反向传播等效的其他形式的学习。例如,“液体状态机”(Maass et al., 2002)或“回波状态机(echo state)”(Jaeger and Haas, 2004)是随机连接的复现网络(recurrent net),其可形成随机的基础滤波器集合(也称为“库滤波器),并利用可调谐的读出层权重来学习。体现混沌(chaotic)和自发动力(spontaneous dynamics)的变体甚至可以通过将输出层结果反馈到网络中并抑制混沌活动(chaotic activity )来训练(Sussillo and Abbott, 2009)。仅学习读出层使得优化问题更简单(实际上,等价于监督学习的回归)。此外,回波状态网络可以通过强化学习以及监督学习来训练(Bush, 2007; Hoerzer et al., 2014)。随机非线性滤波器的储层(reservoirs)是对许多神经元的多样化、高维度、混合选择性调谐特性的一种解释,例如这种现象存在与大脑前额叶皮质中(Enel et al., 2016)。其他学习规则去仅修改随机网络内部的一部分突触的变体,正发展成为生物短期记忆(working memory)和序列生成的模型(Rajan et al., 2016)。
这段读起来非常吃力,但值得注意的是其中提到的只对输出层进行无监督训练的方式,是否一定能使优化变得简单呢?可以尝试做实验验证一下。另外,局部自组织,也可理解为“局部无监督学习”。
2.2 优化的生物学实现
我们认为上述局部自组织的机制可能不足以解释大脑的强大学习表现(Brea and Gerstner, 2016)。 为了详细说明在大脑中需要有效的梯度计算方法,我们首先将反向传播置于其计算的上下文环境中(Hinton, 1989; Baldi and Sadowski, 2015)。 然后我们将解释大脑如何合理地实现梯度下降的近似。
这里厉害了,gradient approximation (梯度近似)是深度学习里最迫切需要解决的问题,因为这样将大大减少对计算资源的消耗。
2.2.1 多层神经网络对高效梯度下降的需求
执行成本函数优化的最简单的机制有时被称为“旋转”算法,或更技术上称为“串扰”。这种机制通过以小增量扰动(即“twiddling”) 网络中的一个权重,以及通过测量网络性能(对比成本函数的变化,相对于未受干扰的权重)来验证改进。 如果改进是显著的,扰动被用作权重的变化方向; 否则,权重沿相反方向改变(或根本不改变)。 因此串行扰动是对成本“coordinate descent”的方法,但是它是缓慢的并且需要全局协调:每个突触按顺序被扰动而要求其他保持固定。
总的来说,twiddling思想是比较简单的,但是在全局范围实现却很困难,并不是一个可行的解决方案。
另一方面,自然地我们会想到全局权重扰动(或平行扰动)即同时扰动网络中的所有权重。 它能够优化小型网络以执行任务,但通常引发高方差。 也就是说,梯度方向的测量是有噪声的,并且其在不同扰动之间剧烈变化,因为权重对成本函数的影响被所有其他权重的变化掩蔽,然而只有一个标量反馈信号指示成本的变化。 对于大型网络,全局权重扰动是非常低效的。 事实上,如果时间测量计数网络从输入到输出传播信息的次数,则并行和串行扰动以大致相同的速率学习(Werfel et al., 2005)。
上述的过程,在反向传播过程中形成了一对多(目标函数标量变化对应多种可能的权重变化)的映射关系,这是任何一般意义上的函数都无法拟合的(信息不能被完全学习),因为这种映射不属于函数。
一些效率增益可以通过扰乱神经活动而不是突触权重来实现,遵循神经突触的任何长程效应通过神经元介导的事实。就像在权重扰动中,而不同于串扰的是,最小的全局协调是必须的:每个神经元仅需要接收指示全局成本函数的反馈信号。在假定所有神经元或所有权重分别被扰动并且它们在相同频率处被扰动的假设下,节点扰动梯度估计的方差远小于权重扰动的方差。在这种情况下,节点扰动的方差与网络中的细胞数量成比例,而不是突触的数量。
所有这些方法都是缓慢的,不是由于对所有权重的串行迭代所需的时间复杂度大,就是对于低信噪比梯度估计的平均所需的时间复杂度大。然而,他们的信誉(credit),这些方法都不需要超过关于局部活动和单一全局成本信号的知识。大脑中的真实神经回路似乎具有编码与实现那些算法相关的信号的机制(例如,可扩散神经调节器)。在许多情况下,例如在强化学习中,基于未知环境的交互计算的成本函数不能直接进行微分,并且代理(agent,智能代理,强化学习中的术语)不得不部署聪明的twiddling以在系统的某个级别进行探索(Williams, 1992)。
这个方法对于不可微的目标函数是非常有用的,在我的知识范围内,目前还没有发现深度学习有对不可微分的目标函数探索过。但如上文所述,这是非常缓慢的,可能也只适合在强化学习(reinforcement learning)中使用。在深度强化学习中(比如AlphaGo)可否使用不可微分的目标函数呢?值得探索
相反,反向传播通过基于系统的分层结构计算成本函数对每个权重的灵敏度来工作。 相对于最后一层的成本函数的导数可以用于计算关于倒数第二层的成本函数的导数,等等,一直到最早的输入层。 可以快速计算反向传播,并且对于单个输入 – 输出模式,其在其梯度估计中不存在方差(variance = 0)。 反向传播的梯度对于大型系统而言比对于小系统没有更多的噪声,因此可以使用强大计算能力有效地训练深而宽的架构。
这段基本解释了目前的深度神经网络为什么使用BP可以被有效训练。
深度学习与神经科学相遇(三)
作者:Jeven 来源:
上一篇: 论文翻译:整合深度学习和神经科学
上次说到误差梯度的“反向传播”(Backpropagation),这次咱们从这继续。需要说明的是,原文太长,有的地方会有些冗长啰嗦,所以后面的我会选择性地进行翻译,然后附上一些思考和问题的注释,会更像读书笔记吧,这样也可以让学习过程更高效一些。
2.2.2. Biologically plausible approximations of gradient descent
这一节主要讲的是为了在生物学习中实现机器学习中的误差梯度的反向传播,更复杂的gradient propagation机制应该被考虑。虽然这些机制在细节上不同,但是它们都调用具有相位误差的反馈连接。学习是通过将预测与目标进行比较来进行的,并且预测误差用于驱动自底向上活动中的自上而下的改变。
文中很多地方提到neuron spike, 神经元的电活动,但不代表该神经元一定被激活。个人觉得比较难翻译, “神经元动作电位”在有的地方不太通顺,所以后面就直接使用英文来描述这个概念。Google一番之后找到的定义是:During a spike, or action potential as it is called by neuroscientists, a neuron's membrane potential quickly rises from values around -65 mV to about 20 mV and then drops back to -65 mV.
反向传播的近似也可以通过神经活动的毫秒级定时来实现(O'Reilly et al., 2014b)。例如,Spike timing dependent plasticity(STDP)(Markram et al., 1997)是一些神经元的特征,其中突触权重变化的符号取决于突触前后spike的精确至毫秒量级相对定时。这通常被解释为测量突触前和突触后之间的因果关系的潜力的Hebbian可塑性:突触前的spike可能有助于突触后的spike,仅当两者发生的时间间隔很小的时候。为了实现反向传播机制,Hinton提出了一种替代解释:神经元可以在它们的激活率(firing rate)的时间导数中对反向传播所需的误差导数类型进行编码(Hinton, 2007, 2016)。于是STDP就与这些对误差导数敏感的学习规则相关联(Xie and Seung, 2000; Bengio et al., 2015b)。换句话说,在适当的网络环境中,STDP学习可以产生反向传播的生物实现。
STDP,Wikipedia:是大脑自身调整其神经元之间的连接强度的生物过程。 该过程基于特定神经元的输出和输入动作电位(或spike)的相对定时来调整连接强度。 STDP过程部分解释神经系统的活性依赖性发展,特别是关于Long-term potentiation和Long-term depression。(从定义可以看出它与Backpropagation之间有很高的相似性)
生物神经网络可以近似反向传播的另一种可能机制是“反馈比对”(feedback alignment)(Lillicrap et al., 2014; Liao et al., 2015)。在feedback alignment中,反向传播中的反馈通路由一组随机反向连接代替,一个层的误差导数是通过该反馈通路从后续层的误差导数来计算的,而不依赖于前向权重。根据前馈和反馈连接之间的突触归一化机制和近似符号一致性的存在(Liao et al., 2015),计算误差导数的这种机制几乎与各种任务的反向传播一样好。实际上,前向权重能够适应性地使网络进入一种状态,其中随机后向权重实际上可以携带用于近似梯度的信息。这是一个引人注目和令人惊讶的发现,并且它表明我们对梯度下降优化的理解,特别是反向传播本身起作用的机制仍然是不完全的。在神经科学中,我们发现几乎无论在哪里找到前馈连接,哪里就伴随有反馈连接,讨论它们的作用是很多研究理论的主题(Callaway, 2004; Maass et al., 2007)。应当注意的是,feedback alignment本身并不精确地指定神经元如何表示和利用误差信号,它仅放宽对误差信号的传送的约束。因此,feedback alignment更多的是作为反向传播的生物学实现的基础,而不是完全生物学实现本身。因此,可以将其并入这里讨论的几个其他方案中。
毋庸置疑,大脑计算误差导数的方式是复杂的,相信这与其使用多样化且相互作用的动态目标函数机制是紧密联系在一起的。而如今深度学习中的误差导数传播方法被Backpropagation所主导,相比之下,chain rule显得有些naive。值得注意的是这里提到的随机反馈连接,这是一个非常有意思的研究方向,如果添加注意力机制,可以理解为使用全局的信息对反向传播的误差导数进行近似,会加速收敛吗?
这些讨论的核心实际上是:使用另一个(或多个)神经网络去做求导的工作,至于为什么要这么做,可能就会涉及到需要对普通的微积分(黎曼积分)的局限性、函数空间等等进行讨论了,这就需要很深入的数学知识了。
这里附上一篇最近比较前沿的关于合成梯度的paper:Decoupled Neural Interfaces using Synthetic Gradients,个人觉得它和NTM(Neural Turing Machine)、GAN(Generative Adversarial Networks)一样,很可能是具有"里程碑"式意义的
上述的反向传播的“生物学”实现仍然缺乏生物实际性(biological realism)的一些关键方面。 例如,在大脑中,神经元往往是兴奋性的或抑制性的,但不是两者同时存在,而在人工神经网络中,单个神经元可向其下游神经元同时发送兴奋性和抑制性信号。 幸运的是,这种约束不会限制其可以学习各种函数的能力(Parisien et al., 2008; Tripp and Eliasmith, 2016)。 然而,其他生物学考量则需要更详细地看待:生物神经网络的高度重现(recurrent)性质,其显示在时间尺度上丰富的动力学特性(dynamics, 这个词也很难翻译,个人更倾向于“动态”),以及哺乳动物大脑中的大多数神经元通过spike通信的事实。 我们下面依次考虑这两个问题。
2.2.2.1. Temporal credit assignment
再次遇到credit assignment,之前有翻译成“信用分配”,还是有些模糊,有人翻译成“功劳分配”,有些“能者多劳”的感觉,通俗地解释是:认为表现好的组件就多给它一些权重,这样对实现目标更有利
这个部分主要讲的是BPTT(backpropagation through time),主要就是针对RNN,就不赘述了,就是把backpropagation在时间尺度上展开,然后可以把credit assign到不同的time steps(或者internal state)。不过作者表示:While the network unfolding procedure of BPTT itself does not seem biologically plausible, to our intuition, it is unclear to what extent temporal credit assignment is truly needed (Ollivier and Charpiat, 2015) for learning particular temporally extended tasks. BPTT生物学的生物学可解释性目前还是不太确定的。
如果系统被授予对时间上下文(context)的适当存储器存储和表示(Buonomano and Merzenich, 1995; Gershman et al., 2012, 2014)的访问,这可以潜在地减少对时间尺度上credit assignment的需要, 可以“空间化”时间credit assignment的问题。 例如,Memory Network(Weston et al., 2014)
有兴趣的读者可以看看Memory Network,引入记忆存储之后网络将具备实现推理的基础,这个话题就会引发一系列的关于Memory Augmented Networks的讨论和研究,目前是非常热门的,比如DeepMind的DNC就是一个对这类网络更广义的扩展,已经抽象到了另一种计算机实现,这个论文是发在Nature上的。
Werbos在他的“error critic”中提出,通过学习以与强化学习中的价值函数的预测类似的方式学习预测BPTT的梯度信号(costate),可以实现对BPTT的online approximation(Werbos and Si, 2004)。这种想法最近被应用于(Jaderberg et al., 2016,就是之前提到合成梯度的那个研究),以允许在训练期间网络的不同部分的解耦,并且便于通过时间的反向传播。广义上,我们才刚开始理解神经活动本身如何表示时间变量(Xu et al., 2014; Finnerty et al., 2015),以及如何经常性的网络可以学习生成人口变化随时间的轨迹(Liu and Buonomano, 2009)。此外,正如我们在下面将讨论的,一些cortical models也提出,除了BPTT还可通过其他方式去训练网络以完成序列预测任务,甚至是在线学习(O'Reilly et al., 2014b; Cui et al., 2015; Brea et al., 2016)。可以使用很多更实际的手段来近似BPTT。
2.2.2.2. Spiking networks(这个不太熟悉,虽然大概60年前就提出了)
这个部分不太熟悉,跳过一些。但里面提到的快速、慢速连接是非常赞的idea,在Bengio的一些演讲中好像有提到,但我还没有很理解具体如何实现这种不同速率的计算连接
使用具有多个时间尺度的循环连接(recurrent connection)可以消除在直接训练spike reccurrent networks的过程中反向传播的需要(Bourdoukan and Denève, 2015)。 快速连接将网络维持在慢速连接能够局部访问全局错误信号的状态。 虽然这些方法的生物依据仍然是未知的,它们都允许在spike networks中学习连接权重。
这些新颖的学习算法说明了一个事实,我们才刚开始理解生物神经网络中的时间动力学特性和时间和空间credit assignment机制之间的联系。 然而,我们认为在这里现有的证据表明生物似真的神经网络可以解决这些问题 - 换句话说,在生物神经元的spiking networks的上下文环境下,复杂的与时间历史相关的函数可能被有效地优化。 这些复杂的函数可以是认知相关的,但问题是发展中的大脑如何有效地学习这样复杂的功能。
小结:本节文中讨论的内容与RNN训练和学习关系密切,为了更好的理解这部分以及后面部分的内容,个人觉得需要还做一些功课。Bengio从他博士期间就开始研究RNN至今,目前可以说深度学习占领着机器学习的半壁江山,而RNN则是深度学习的核心。
这里建议暂停一下先认真看看下面三篇paper,甚至RNN更基础的东西。
On the difficulty of training recurrent neural networks
Professor Forcing: A New Algorithm for Training Recurrent Networks
Decoupled Neural Interfaces using Synthetic Gradients
#待续...

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“数据科学家”、“赛博物理”、“供应链金融”。
官方网站:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com





