剑桥构建视觉“语义大脑”:兼顾视觉信息和语义表示
点击上方“公众号”可以订阅哦!

来源:新智元
编译:大明
【导读】一般认为,大脑对可视目标的识别过程分为两部分:视觉属性和语义属性,即目标“像什么“和”是什么“。过去人们对这两部分一般是分开研究的,现在,剑桥大学的研究人员利用计算机视觉的标准深度神经网络AlexNet,可以将二者结合起来研究,并探寻它们之间的信息交互和映射关系究竟是怎样的。
剑桥大学的神经科学研究人员将计算机视觉与语义相结合,开发出一种新模型,可以更清晰地理解大脑对视觉目标的处理方式。
人类识别目标的能力分为两个主要过程,对目标的快速视觉分析,以及对整个生命过程中获得的语义知识的激活。大多数过去的研究一般是对这两个过程进行分别研究。因此,这两个过程之间的相互作用目前仍然很不清楚。
剑桥大学的研究人员团队使用一种新方法研究了大脑对目标的识别过程,该方法结合了深度神经网络与吸引子网络语义模型。与之前的大多数研究相比,这一识别技术既考虑了视觉信息,也考虑了关于被识别目标的概念知识。
剑桥大学的研究人员表示:“我们之前曾对健康人和脑损伤患者进行了大量研究,以更好地了解大脑中对识别目标的处理方式。这项工作的主要贡献之一是,它表明了大脑在理解‘目标是什么’这个问题时,涉及到视觉输入随着时间的推移,迅速转变为有意义的表现形式,这种转变过程是沿着腹侧颞叶完成的。”
研究人员坚信,对语义记忆的访问是理解“目标是什么”的关键,因此仅关注与视觉相关的属性的理论并不能完全捕捉到这个复杂的过程。
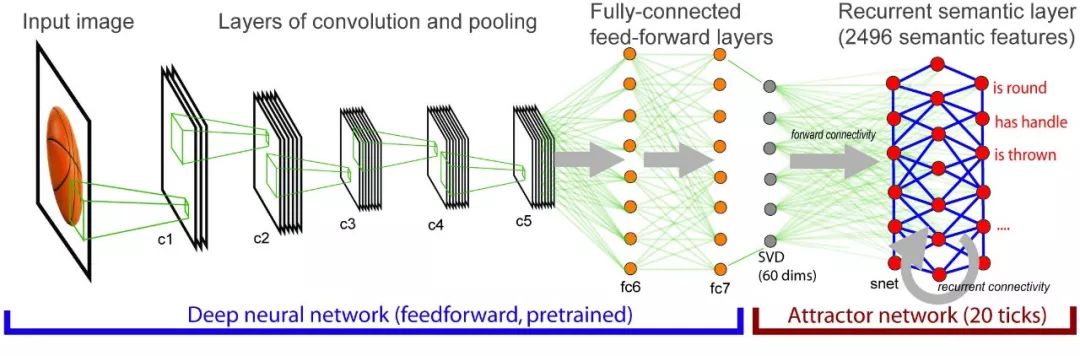
该集成模型的体系结构,可以看到,会有越来越复杂的视觉信息映射到语义信息上。
来源:Lorraine Tyler等。
“就是这个问题催生出了我们目前的研究,我们希望能够完全理解低级视觉输入是如何映射到对象意义的语义表示上的。”研究人员解释说。为此,他们使用了一个专门用于计算机视觉的标准深度神经网络,称为AlexNet。
他们解释说:“这个模型以及其他类似模型可以非常精确地识别图像中的对象,但模型中不包含任何关于对象语义属性的明确知识。例如,香蕉和猕猴桃的外观(不同的颜色,形状,质地等)有很大不同,但是,我们能够正确地理解它们都是水果。计算机视觉的模型可以区分香蕉和猕猴桃,但这些模型并不是对更抽象的知识进行编码,即:它们都是水果。”
研究人员认识到神经网络在计算机视觉应用方面的局限性,将AlexNet视觉算法与神经网络相结合,将概念性的意义(包括语义知识)纳入到对方程的分析中。
研究人员表示:“在这个组合模型中,会将视觉处理映射至语义处理,并激活我们关于概念的语义知识,”这个新技术已经在16名志愿者的神经影像数据上进行了测试,志愿者被要求在接受功能性核磁共振(fMRI)扫描的同时说出测试图片中目标的名字。与传统的深度神经网络(DNN)视觉模型相比,新方法能够识别与视觉和语义处理相关的不同脑区。
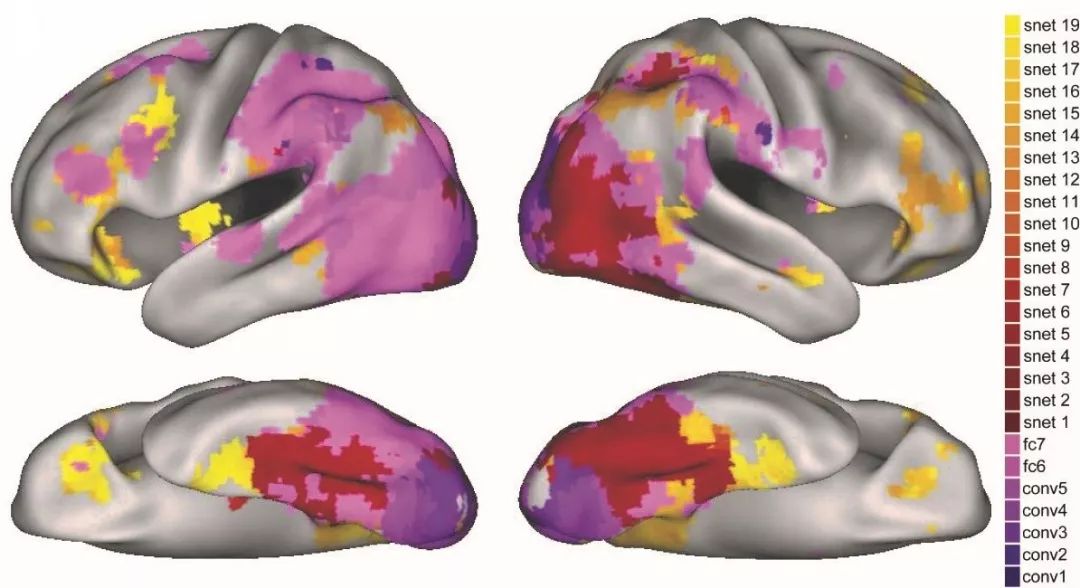
图为视觉深度神经网络(紫色)和语义吸引网络(红色-黄色)的不同层如何映射到大脑的不同区域。
来源:Lorraine Tyler等。
“这项研究最关键的发现是,通过考虑物体的视觉和语义属性,可以更好地模拟物体识别过程中的大脑活动,这可以通过计算建模方法捕获,”研究人员解释说。
研究人员设计的方法对大脑中语义激活的阶段进行了预测,预测结果与先前对目标的处理结果是一致的,其中粒度更粗的语义处理被更精细的处理所取代。研究人员还发现,该模型在不同阶段预测了大脑不同区域的对象处理方式的激活。
“最终,关于如何有意义地处理视觉目标的更优秀的模型可能具有重要的临床意义。例如,语义性痴呆症的患者就失去了对象概念意义的知识,这项研究的发现对于该病的治疗是很有帮助的。”研究人员说。
剑桥大学的这项研究是对神经科学领域的重要贡献,因为它展示了大脑的不同区域是如何推进对目标的视觉处理和语义处理的。该研究最近发表在《Scientific Reports》上。
参考链接:
https://techxplore.com/news/2018-07-visual-semantic-neural-network-human.html
注:投稿请电邮至124239956@qq.com ,合作 或 加入未来产业促进会请加:www13923462501 微信号或者扫描下面二维码:

文章版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将删除内容或协商版权问题!联系QQ:124239956




