结合人类视觉注意力进行图像分类
注:昨天推送发现内容有一个严重错误,所以临时删除了文章的链接,希望关注的您能够谅解,我们也是希望推送最完整最准确的内容,谢谢您的支持与关注,谢谢!
好久没有和大家见面了,也没有动手写过一些东西,还写错了一些东西,感觉对不住大家的关注和支持。最近,抽空看了一篇不错的Paper,我想和大家分享一下。
现在应该有很多都在做目标检测和分类的吧,今天就来讲讲图像分来的一些创新技术,主要是通过2017年的一篇Paper来给大家详细说明下,希望可以给在该领域准备做创新的朋友带来一点灵感,谢谢!
文章源自于——《Residual Attention Network for Image Classification》
该文章主要就说明了两点:
引入残差网络;
引入注意力机制(Attention Mechanism);
最主要的是他可以实现端到端自适应的调整。
Residual Attention Network由多个注意模块(Attention Modules)组成,产生注意感知特征。这个想法特别好,实现了简单的人眼注意力的机制,根据人眼注意的一种方式来应用在图像分类,简单来说,就是应用了显著性的特征。个人认为显著性是一个特别好的研究方向,我也在这方面接触一段时间,觉得在这领域有很多待挖掘和创新,因为我们人类观察一些事物,都是从局部到全局,更是从显著性部分区域开始观察,所以利用Saliency去做一个预处理,是一个绝对不错的选择,有机会我下次写一份我做的一些成果,有兴趣的朋友更加可以联系我,一些讨论,也可以加入我们战队的微信群进行详细交流。扯远了,现在开始正式讲解。
该文章除了更多注意机制带来的的判别性特征表示以外,文章模型还具有以下吸引人的特性:
随着不同类型的注意被广泛捕获,越来越多的关注模块会导致性能相对的提升;
模型能够在一个先进的深度网络(ResNet)上进行端到端的训练。具体来说,网络的深度可以很容易地扩张到上百层。
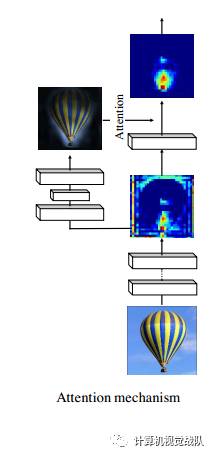
简单的记忆力机制,展示了特征和注意力之间的相互作用
主要通过以下来实现以上的特性:
Stacked network structure:Residual Attention Network是由堆叠多个注意模块来构建的。堆叠结构是mixed attention机制的基本应用。因此,不同类型的注意力能够在不同注意模块被捕获;
Attention Residual Learning:其实堆叠网络结构会直接影响性能。所以,文章提出用残差学习机制去进行学习百层的Residual Attention Network;
Bottom-up top-down feedforward attention:自底向上的前馈结构在很多领域已经被人用过,如人体姿势估计,图像分割。文章利用这个结构作为Attention Modules的一部分,并在特征中添加了软约束权重。这结构可以模仿自底向上快速前馈的过程和自顶向下注意力的反馈,允许文章模型实现end-to-end的训练。

现在来详细了解下内部结构:
Residual Attention Network
Attention Module H的计算如下:
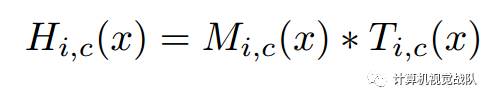
i表示所有空间位置的范围,c∈{1,2,...,C}表示通道的索引。
注意模块,attention mask 不仅可以作为在向前推理过程的特征选择器,而且还可以作为在BP过程的一个梯度更新滤波器。在soft mask的分支,对输入特征的mask的梯度为:
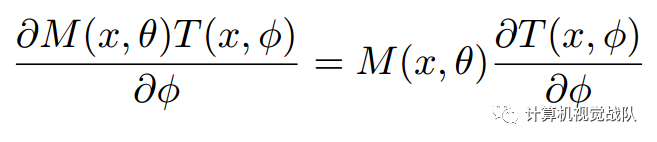
θ是mask branch的参数,Φ是trunk branch 的参数。
然而,这些方法在挑战性的数据集,如ImageNet有几个缺点。首先,图像杂波背景,复杂的场景,和大的外观变化,需要根据不同的类型选择关注模型。在这种情况下,不同的层需要由不同attention masks建模。使用一个单一的mask支流,会需要指数型数量的通道去捕捉不同元素的素有组合。其次,一个单模块只修改特征一次,如果对图像中的某些部分修改失败,下面的网络模块不会有第二次机会。
因此,本文为了缓解上述问题,每个主干分支都有学习自己的attention masks,如之前得图所示。
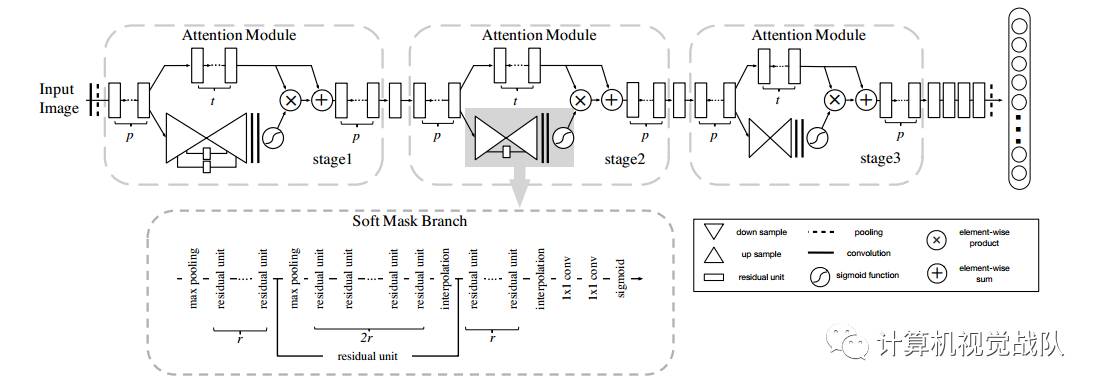
网络框架
Attention Residual Learning
文章修改了H的输出,如下形式:
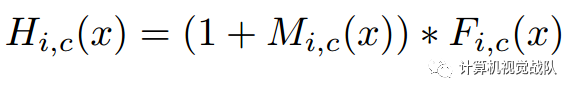
这个学习方式不同于残差学习,在ResNet中:
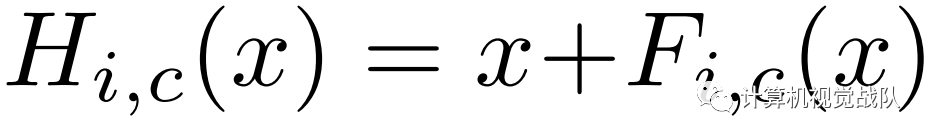
其中F(x)近似残差函数。而本文中,F(x)包含了由深度网络生成的特征。关键在于mask branches M(x)。
Soft Mask Branch
文章采用了不同尺度的去捕获信息。
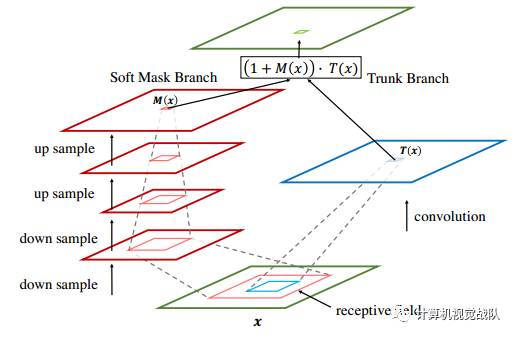
mask branch和trunk branch感受野的比较
Spatial Attention and Channel Attention
在文章中,mask branch根据trunk branch特征自适应改变来提供attention,然而,通过改变归一化步骤,在soft mask输出之前的激活函数,约束attention仍可以添加到mask branch。
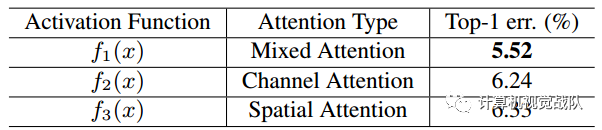
文章通过三种激活函数表示相对应的mixed attention、channel attention和spatial attention。Mixed attention f1对于每个channel和spatial没有额外的限制去使用简单的Sigmoid;Channel attention f2对每一个spatial position在所有channels中使用L2范数,为了去除spatial information;Spatial attention f3在每个channel的特征图执行归一化,然后Signoid去得到相对应spatial information的soft mask。
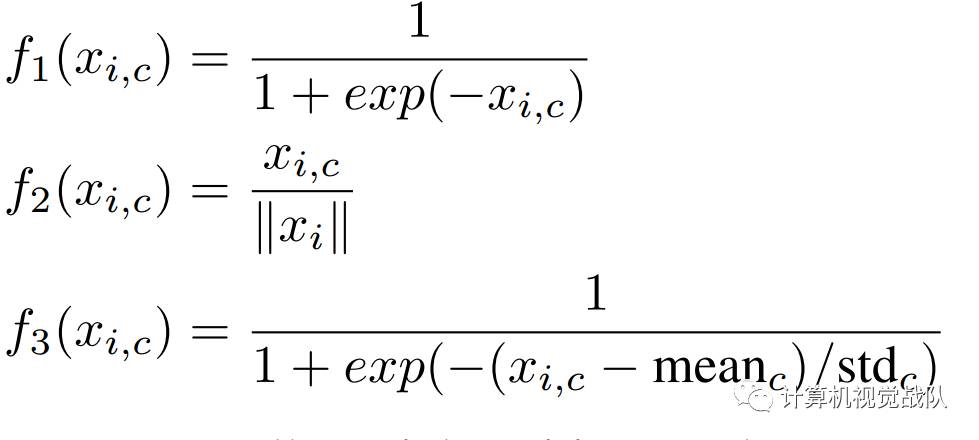
从实验科研看出,不同激活函数的作用。在CIFAR-10的测试误差,用的是Attention-56网络。
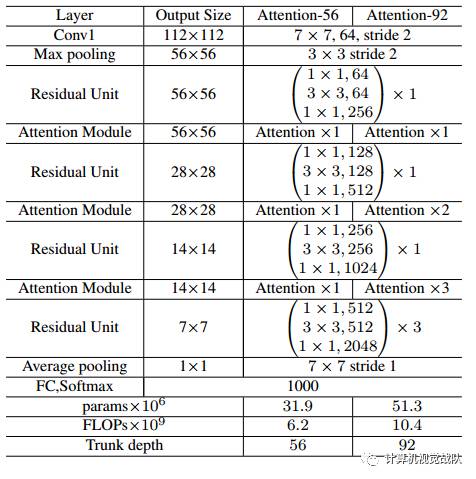
网络的详细信息。
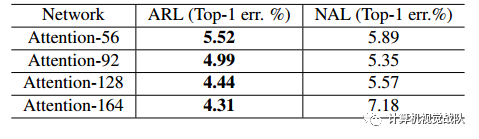
实验
最后来贴一下实验结果和分析。这个是在CIAFR-10的分类误差。
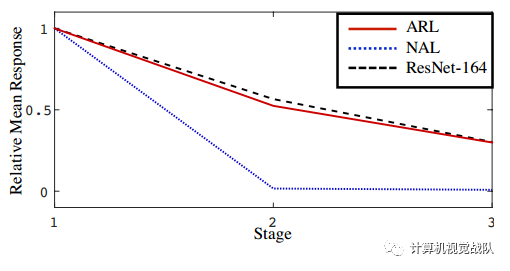
每个阶段的平均响应如下图所示:
文章还做了噪声影响的实验,证明文章的网络对Noisy Label鲁棒的。其中,confusion matrix Q为:
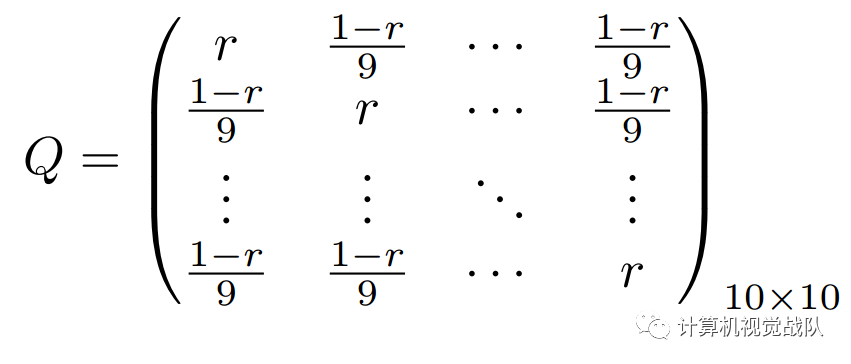
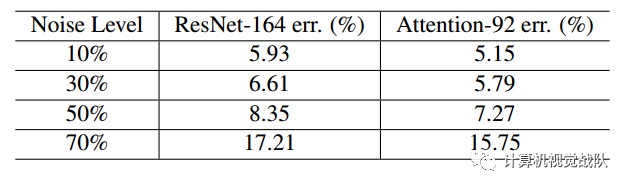
在CIFAR-10的实验结果。
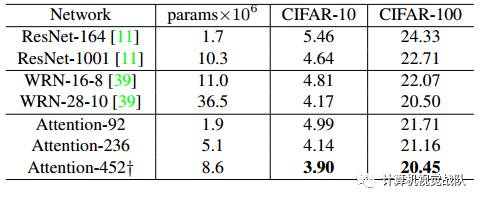
与先进网络的比较
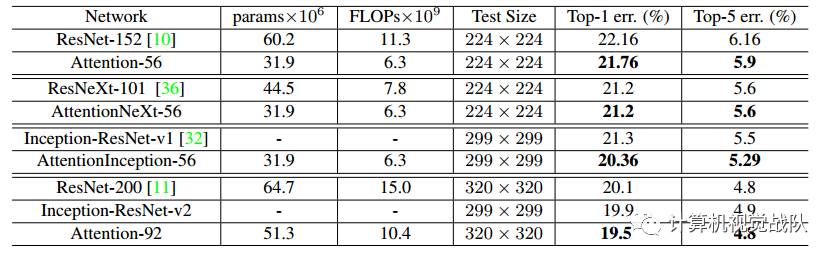
居然文章一直在讲图像分类,实验肯定是要在大数据集做分类实验的,如下就是在ImageNet中的实验误差:
总结一下:
网络的第一个好处在于不同注意模块捕获不同类型的注意导向特征学习。文章还通过激活函数的形式实验也验证了这一点:自由的形式mixed attention会比constrained (including single) attention有更好的性能。第二个好处是将自上而下的注意机制编码为每个注意模块的自底而上的前馈卷积结构。因此,基本注意力模块可以结合起来形成更大的网络结构。此外,residual attention学习允许训练非常深的Residual Attention Network。
小小展望一下下:
在未来,将利用Residual Attention Network不同的用途,如检测和分割,去为了更好的探索具体任务的mixed attention机制。





