上海交大提出LRNNet:实时语义分割新网络,速度高达71 FPS!仅0.68M
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI算法修炼营 | 论文已上传,文末附下载方式

本文是 上海交通大学团队提出的轻量级实时语义分割算法。本文主要从视觉注意力机制中的non-local 模块出发,通过对non-local模块的简化,使得整体模型计算量更少、参数量更小、占用内存更少。在Cityscapes测试集上,没有预训练步骤和额外的后处理过程,最终LRNNET模型在GTX 1080Ti显卡上的速度为71FPS,获得了72.2% mIoU,整体模型的参数量仅有0.68M。
语义分割可以看作是逐像素分类的任务,它可以为图像中的每个像素分配特定的预定义类别。该任务广泛应用于在自动驾驶领域。开发轻量,高效和实时的语义分割方法对于语义分割算法实际应用至关重要。在这些属性中,轻量级可能是最重要的属性,因为使用较小规模的网络可以导致更快的速度和更高的计算效率,或者更容易获得内存成本。
随着视觉注意力机制在计算机视觉领域的广泛应用。语义分割中也采用non-local网络来建模远程依赖(具体的Non-local网络的讲解可以参考公众号视觉注意力机制系列文章,在文末有推荐)。但是,针对每个像素建模位置关系计算和存储成本都非常大。本文利用spatial regional dominant singular vectors 得到更简洁但更具表示能力的non-local 模块,更加有效地建模远程依赖关系并进行全局特征选择。
本文的主要贡献:
1、本文提出了分解因子卷积块(FCB),通过更适当的方式处理远程依赖关系和短距离的特征来构建轻量级且高效的特征提取网络。
2、本文提出的高效简化Non-local模块,其利用了区域性奇异向量可产生更多的简化特征和代表性特征,以对远程依赖关系和全局特征选择进行建模。
3、实验显示了LRNNet在Cityscapes数据集和Camvid数据集上兼顾了计算速度和分割精度,都具有不错的表现。
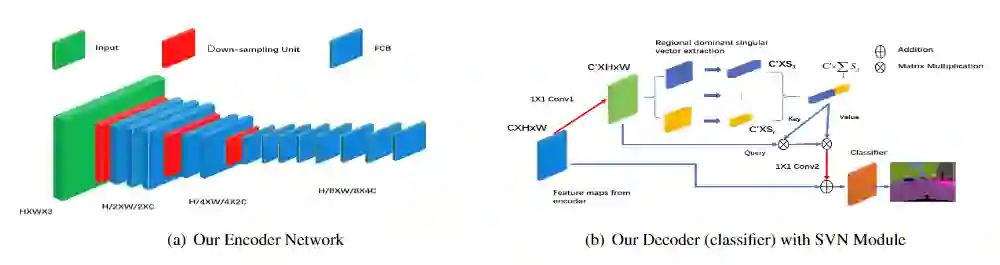
LRNNet整体结构:(a)LRNNet的编码器,由分解因子卷积块(FCB)和下采样模块组成 (b)LRNNet带SVN模块的解码器。上分支以不同比例的区域优势奇异向量来执行非局部运算。红色箭头表示1×1卷积,可调整通道大小以形成瓶颈结构。分类器(classifier)包括一个3×3卷积,然后是一个1×1卷积。
编码器环节
LRNNet编码器大致来看是由三个阶段的ResNet形式组成。在每个阶段的开始都使用下采样单元用于对各个阶段提取的特征图进行过渡。编码器环节的核心组件是分解因子卷积FCB(Factorized Convolution Block)单元,可提供轻量级且高效的特征提取。同时,在最后一个下采样单元之后,采用了空洞卷积上输出特征图的分辨率保持在1/8。
FCB(Factorized Convolution Block)
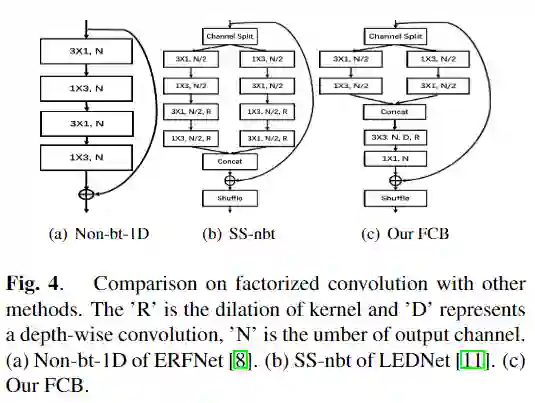
具有较大空洞率的空洞卷积核在空间中接收复杂的远程空间信息特征,并且在空间中需要更多参数。同时,具有较小空洞率的空洞卷积核在空间中接收简单的或较少信息的短距离特征,而只需要较少参数就足够了。因此FCB(上图(c))首先将通道拆分成两组,然后在两组通道中分别用两个一维卷积处理短距离和空间较少的信息特征,这样会大大降低参数和计算量。将两个通道合并后,FCB利用2维卷积来扩大感受野捕获远距离特征,并使用深度可分离卷积来减少参数和计算量。最后设置了通道混洗操作。
LEDNet中的SS-nbt模块(具体代码可以用来参考,复现本文的模型)
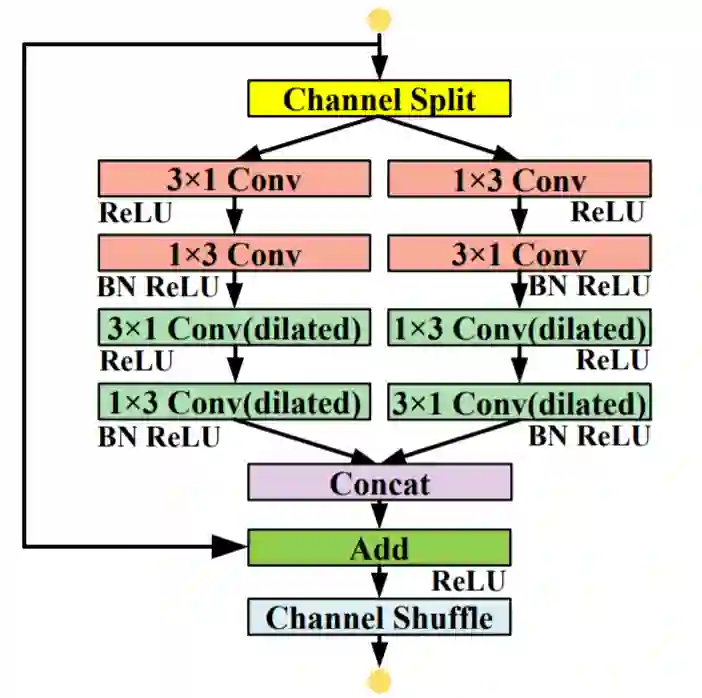
def Split(x):c = int(x.size()[1])c1 = round(c * 0.5)x1 = x[:, :c1, :, :].contiguous()x2 = x[:, c1:, :, :].contiguous()return x1, x2def Merge(x1,x2):return torch.cat((x1,x2),1)def Channel_shuffle(x,groups):batchsize, num_channels, height, width = x.data.size()channels_per_group = num_channels // groupsx = x.view(batchsize,groups,channels_per_group,height,width)x = torch.transpose(x,1,2).contiguous()x = x.view(batchsize,-1,height,width)return xclass SS_nbt_module_paper(nn.Module):def __init__(self, chann, dropprob, dilated):super().__init__()oup_inc = chann//2self.conv3x1_1_l = nn.Conv2d(oup_inc, oup_inc, (3,1), stride=1, padding=(1,0), bias=True)self.conv1x3_1_l = nn.Conv2d(oup_inc, oup_inc, (1,3), stride=1, padding=(0,1), bias=True)self.bn1_l = nn.BatchNorm2d(oup_inc, eps=1e-03)self.conv3x1_2_l = nn.Conv2d(oup_inc, oup_inc, (3,1), stride=1, padding=(1*dilated,0), bias=True, dilation = (dilated,1))self.conv1x3_2_l = nn.Conv2d(oup_inc, oup_inc, (1,3), stride=1, padding=(0,1*dilated), bias=True, dilation = (1,dilated))self.bn2_l = nn.BatchNorm2d(oup_inc, eps=1e-03)self.conv3x1_1_r = nn.Conv2d(oup_inc, oup_inc, (3,1), stride=1, padding=(1,0), bias=True)self.conv1x3_1_r = nn.Conv2d(oup_inc, oup_inc, (1,3), stride=1, padding=(0,1), bias=True)self.bn1_r = nn.BatchNorm2d(oup_inc, eps=1e-03)self.conv3x1_2_r = nn.Conv2d(oup_inc, oup_inc, (3,1), stride=1, padding=(1*dilated,0), bias=True, dilation = (dilated,1))self.conv1x3_2_r = nn.Conv2d(oup_inc, oup_inc, (1,3), stride=1, padding=(0,1*dilated), bias=True, dilation = (1,dilated))self.bn2_r = nn.BatchNorm2d(oup_inc, eps=1e-03)self.relu = nn.ReLU(inplace=True)self.dropout = nn.Dropout2d(dropprob)def forward(self, x):residual = xx1, x2 = Split(x)output1 = self.conv3x1_1_l(x1)output1 = self.relu(output1)output1 = self.conv1x3_1_l(output1)output1 = self.bn1_l(output1)output1_mid = self.relu(output1)output2 = self.conv1x3_1_r(x2)output2 = self.relu(output2)output2 = self.conv3x1_1_r(output2)output2 = self.bn1_r(output2)output2_mid = self.relu(output2)output1 = self.conv3x1_2_l(output1_mid)output1 = self.relu(output1)output1 = self.conv1x3_2_l(output1)output1 = self.bn2_l(output1)output2 = self.conv1x3_2_r(output2_mid)output2 = self.relu(output2)output2 = self.conv3x1_2_r(output2)output2 = self.bn2_r(output2)if (self.dropout.p != 0):output1 = self.dropout(output1)output2 = self.dropout(output2)out = Merge(output1, output2)out = F.relu(residual + out)out = Channel_shuffle(out,2)return out
LRNNet的解码器环节主要有上下两个分支,上分支是对Non-local模块进行简化来捕获长距离依赖关系的信息,下分支是一个分类器(classifier),其结构包括一个3×3卷积,然后是一个1×1卷积。解码器环节中最重要的SVN模块,这也是简化Non-local模块的根本。
SVN模块

本文通过两种方式降低了Non-local的计算成本:1、通过Conv1和Conv2两个1x1卷积以减少non-local计算操作的通道数;2、用区域主导的奇异向量(spatial regional dominant singular vectors)替换key和value。
SVN由两个分支组成,下分支是输入的残差连接,上分支是简化的non-local操作。在上分支中,将C′×H×W特征图划分为S = H×W/H′×W′(S远小于N = WH)个空间子区域,其尺度为C′×H′×W′。对于每个子区域,将其展平为大小为C'×(H'W')的矩阵,然后使用幂迭代算法( Power Iteration Algorithm)有效地计算其主导的奇异左向量(C'×1)。主导的奇异左向量(C'×1)与展平方式无关,并且此属性类似于合并。然后将区域主导奇异向量用作Non-local运算S集合下的Keys和Value,而来自特征的Queries位置向量(C′×1)提前映射。为了增强简化的non-local模块,还执行了多尺度区域提取,并收集了不同尺度的优势奇异向量作为key和value。
幂迭代算法如下:

实验配置:在Cityscapes数据集上使用480×360图像进行训练和测试。采用单个GTX 1080Ti进行训练和测试。
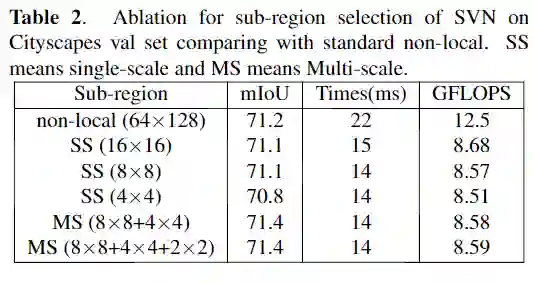
在消融实验中,将不带SVN的LRNNet表示为model A,带单尺度的SVN(有64(8×8)个子区域)表示为model B和带多尺度的SVN(有8×8 + 4×4个子区域)表示model C。
FCB的消融
ERFNet 和LEDNet 仅使用一维因式分解内核来处理短距离和长距离特征。FCB能够利用一维分解因子小卷积核捕获短程特征的同时利用二维大卷积核捕获远程特征。
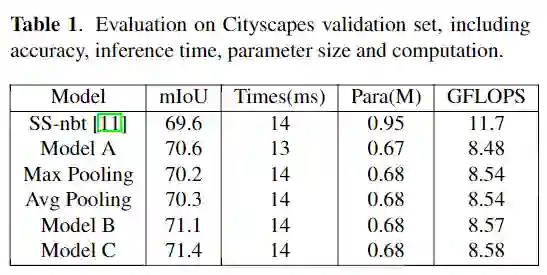
SVN的消融
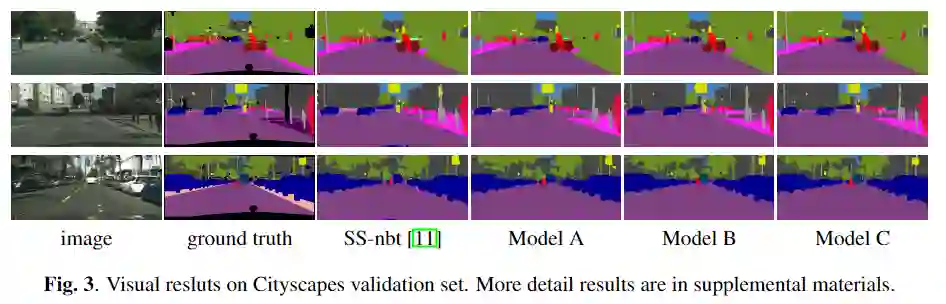
与其他模型对比实验
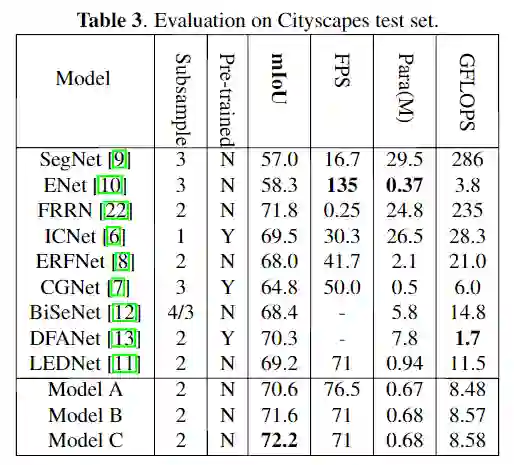
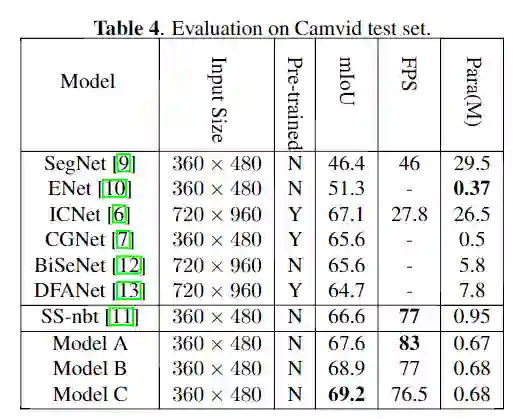
从表格可以看出,在Cityscapes测试集上,没有预训练步骤和额外的后处理过程,最终LRNNET模型在GTX 1080Ti显卡上的速度为71FPS,获得了72.2% mIoU,整体模型的参数量仅有0.68M。
论文下载
在CVer公众号后台回复:LRNNet,即可下载本论文
重磅!CVer-图像分割 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已汇集1300人!涵盖语义分割、实例分割和全景分割等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、TensorFlow和PyTorch等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加群
▲长按关注我们
请给CVer一个在看!



