一种新颖的贝叶斯优化的1-Bit CNNs

转载自:学术头条(ID:SciTouTiao)
作者:Liyang
前言
本文将对ICCV2019会议论文《Bayesian Optimized 1-Bit CNNs》进行解读,这篇论文在二值化神经网络(1-bit CNNs)方面取得了最新进展。作者提出了一种新颖的贝叶斯优化的1-Bit CNNs(简称BONNs),利用贝叶斯学习,将全精度kernels和features的先验分布纳入贝叶斯框架,以端到端的方式构造1-bit CNNs,这是以往任何相关方法都没有考虑到的。实现了连续和离散空间中的贝叶斯损失同时优化网络,将不同的损失联合起来提高模型容量。作者在ImageNet和CIFAR数据集上的实验表明,与最先进的1-bit CNNs相比,BONNs具有更好性能。
研究现状
量化采用低精度值代替全精度值,可加速卷积运算,同时节省存储开销。而1-Bit卷积神经网络是量化的极端情况,其卷积核和激活是二值化的。DoReFa-Net【1】开发了具有低比特宽度参数和梯度的1-Bit卷积核以加快训练和推理。不同的是,ABC-Net【2】采用多个二进制权值和激活来近似全精度权值,从而可以降低预测精度退化。
除此之外,wang等【3】提出了调制卷积网络,仅对核进行二值化,并取得了比参考基线更好的结果。Leng等借鉴了ADMM思想,由少量比特表示网络权重来压缩深度模型【4】。Bi-real net【5】探索了残差结构的新变体,以保留符号函数之前的真实激活,并提出了对不可微分符号函数的导数的紧逼近。Zhuang等提出了一种使用两阶段方法对权重和激活进行交替量化的2~4位量化方法【6】,并在存储器,效率和性能之间提供了最佳均衡方案。
此外,Wu等提出了对训练和推理过程进行离散化的方法【7】,它不仅量化了权重和激活,而且量化了梯度和误差。Gu等提出了一种基于离散投影反向传播算法的量化方法【8】,以获得更好的1-bit CNNs。
作者认为1-bit CNNs与全精度CNNs相比,精度明显降低的原因有两个:1)全精度和1-bit CNNs之间的关系并未充分研究;2)贝叶斯学习作为一种公认的全局优化策略【9】,在1-bit CNNs领域被忽略了。
方法
概述
作者利用贝叶斯学习的有效性以端到端的方式构建1-bit CNNs。特别地,引入了两个新的贝叶斯损失,在此基础上优化1-bit CNNs,提高了效率和稳定性。在统一的理论框架下,这些贝叶斯损失不仅考虑了1-bit CNNs的kernel、weight分布,而且还监督了feature分布。下图显示了损失如何与CNN backbone相互作用。
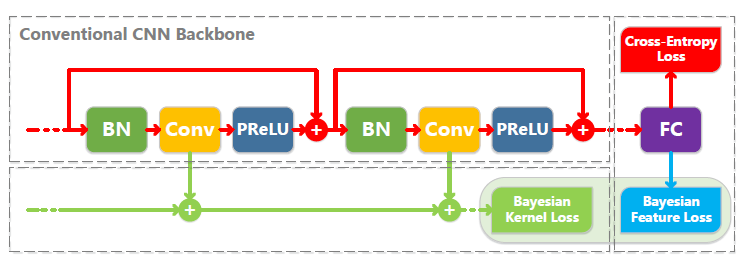
考虑贝叶斯框架中kernels和features的先验分布,实现了两个新的贝叶斯损失,以优化1-bit CNNs的计算。贝叶斯kernel损失改善了各卷积层的分层kernel分布,而贝叶斯feature损失引入了类内紧密度(intra-class compactness)以减轻量化过程带来的干扰。注意,贝叶斯feature损失仅适用于全连接层。
贝叶斯损失(Bayesian Losses)
训练1-bit CNNs有三个步骤:正向传递,反向传递和通过梯度更新参数。二值化的权重仅在前向(inference)和梯度计算时考虑。更新参数后,获得了全精度权重。如何将其连接是确定网络性能的关键。作者在概率框架中对其进行求解,以获得最佳的1-bit CNNs。
1.贝叶斯kernel损失



2.贝叶斯feature损失

通过贝叶斯学习优化1-bit CNNs

反向传递


实验
消融实验
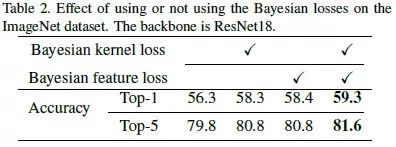
作者使用WRN22在CIFAR-10数据集上,结果如下表所示,贝叶斯kernel损失和贝叶斯feature损失都可以提高准确度,一起使用时,Top-1准确度达到最高59.3%。
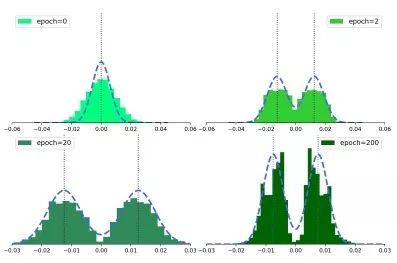
如下图所示为BONNs第1个二值化卷积层的kernel权重分布。在训练之前,将kernel初始化为单模高斯分布。从第2个到第200个epoch,两种模式下的kernel权重分布在变得越来越紧凑,证明了贝叶斯kernel损失可以将kernel正则化为可能的二进制分布。
如下图所示,为XNOR和BONN的权重分布对比。XNOR和BONN之间的权重分布差异表明,通过我们提出的贝叶斯kernel损失,在卷积层上对kernel实现了了正则化。
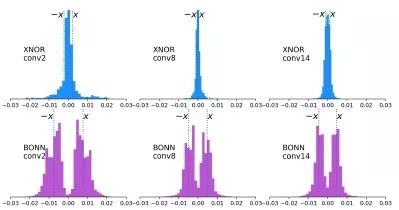
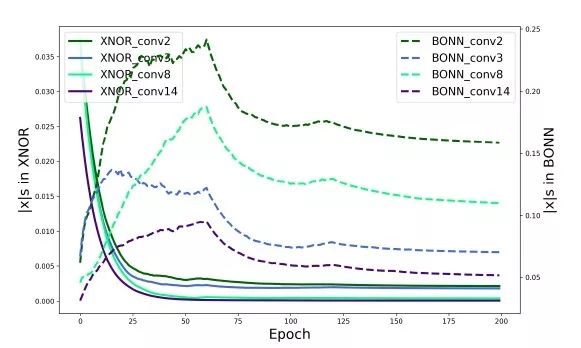
下图显示了XNOR Net和BONN训练过程中二值化值的演变,表明在BONN中学习到的二值化值更加多样化。
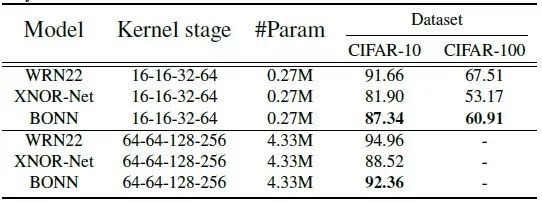
CIFAR10/100数据集结果
作者使用Three WRN变种:22层WRN,kernel stage为16-16-32-64和64-64-128-256。如下表所示,BONN在两个数据集上的性能均优于XNOR Net。即使与全精度WRN相比,BONN性能也相当不错 。
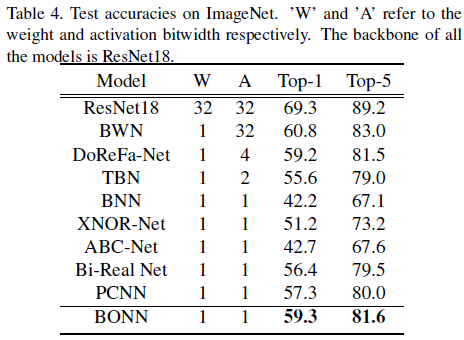
ImageNet数据集结果
如下表所示,与其他最先进1-bit CNNs量化网络相比, BONN获得最高的准确度,其中Bi-Real Net和PCNN的性能与BONN最为接近,而BONN的Top-1分别超过前者大约3%和2%。DoReFa-Net和TBN尽管使用了超过1-bit来量化激活,性能仍逊于BONN。
内存使用率和效率分析
在BONN中,BONN遵循XNOR-Net采用的策略,该策略在第一个卷积层,所有1×1卷积和全连接层中保持全精度参数,由此,ResNet18的总体压缩率为11.10。对于效率分析,如果卷积的所有操作数都是二进制的,可以通过XNOR和位计数操作来估计卷积【M. Courbariaux, I. Hubara, D. Soudry, R. El-Yaniv, and Y. Bengio. Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or- 1. arXiv preprint arXiv:1602.02830, 2016】。
总结
作者提出了贝叶斯优化的1-bit CNNs(BONN),该模型考虑了全精度kernel和features分布,从而形成了具有两个新贝叶斯损失的统一贝叶斯框架。贝叶斯损失用于调整kernel和features的分布,以达到最佳解决方案。
——END——


