谷歌开发EfficientNets,扩大CNN并与AutoML结合,效率提升10倍|一周AI最火论文

大数据文摘专栏作品
作者:Christopher Dossman
编译:笪洁琼、conrad、云舟
呜啦啦啦啦啦啦啦大家好,拖更的AIScholar Weekly栏目又和大家见面啦!
AI ScholarWeekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯。
每周更新,做AI科研,每周从这一篇开始就够啦!
本周关键词:Google AI、深度预测、反欺诈
本周热门学术研究
人类的本质是复读机,GANs的本质是复制粘贴
研究人员从Copy-Pasting(GANs)中得到启发,设计了一种新的对象发现训练程序。在这一新的训练流程中,生成器不会像传统的对象发现方法那样直接生成对象。相反,它会识别并分割现有对象。该方法适用于各种不同的数据集,包括复杂背景下有外观变换的大型对象。

研究表明,通过训练Copy-Pasting GANs,防止生成模型走捷径,可以实现无监督的对象发现。该方法可以处理来自真实图像的杂乱背景,并且可以在不从头开始的情况下,以更高效的数据方式预先训练用于有监督的对象检测模型。它还可以用作智能代理的视觉模块。基本上,这项工作可以有效地为用户驱动的图像处理、对象检测和分割等任务创建实际的可视化数据。
原文:https://arxiv.org/pdf/1905.11369v1.pdf
Google AI:变大的CNN,变小的模型
谷歌研究人员提出了一种新的方法,该方法实现了一个简单但高效的复合系数来扩大CNN。传统方法会随意地缩放网络规模(宽度、深度和分辨率),而这种新方法将每一个规模的维度都与固定系数进行了平衡。
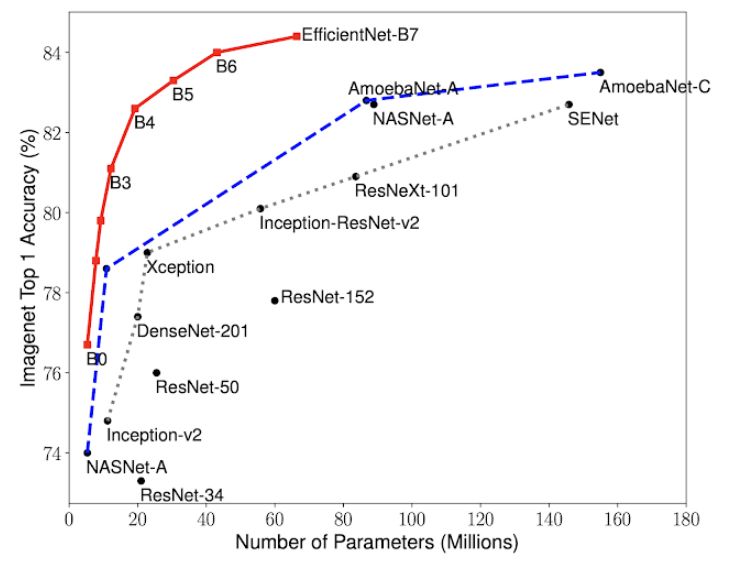
通过将这一方法和最新的AutoML技术结合起来,研究人员开发了EfficientNets,它能够在实现更小更快的模型的同时优化精度和效率(10倍),远远超过了传统方法。
EfficientNets有望成为最先进的计算机视觉任务的基础。为了机器学习社区的利益,研究人员还开发了开源的高效网络算法。
代码运行:
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
原文:https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html
基于深度学习的深度预测
谷歌人工智能的一组研究人员已经应用深度学习来解决从二维图像数据重建几何场景的挑战。他们开发了一种新的模型,能够在摄像机和拍摄对象都自由移动的情况下创建深度图。通过对人体姿态和数据形状的先验学习,该算法能够避免直接使用三维三角定位。
研究人员主要关注于人类,因为他们是增强现实和3D视频效果的良好目标。令人惊讶的是,虽然有许多方法可以预测深度图,但这一研究是第一项帮助设计和实现照相机和人体同时运动的工作。
生成的预测深度图可用于创建各种3D感知视频效果。它们可以帮助生成单目立体视频,也可以将合成CG对象插入到场景中。此外,它们还提供了用视频其他帧中的内容填充孔和不被遮挡区域的能力。
原文:https://ai.googleblog.com/2019/05/moving-camera-moving-people-deep.html
电话诈骗时代的落幕
即便是最先进的欺骗检测系统,也严重依赖于关于欺骗的技术知识。本文通过探索传统和自动编码器的音频特性来解决这一局限性,这些特性在不同类型的重播欺骗中都是可推广的。
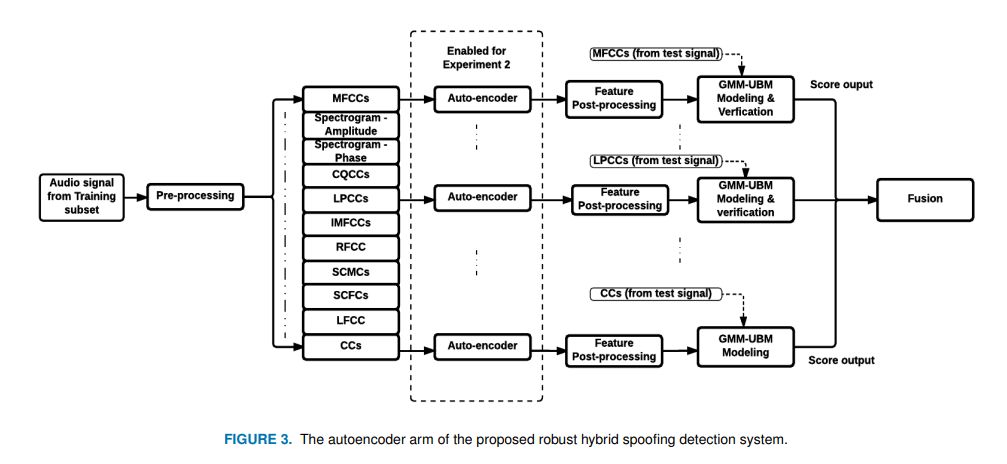
研究人员全面解释了建立高级音频特征检测所需的所有步骤,包括预处理和后处理。他们还评估了强大的重放扬声器检测系统的性能,该系统将提取的和机器学习的音频特征进行了不同的组合,并在嘈杂环境下于ASVSpoof 2017数据集上进行了测试。
与当前最先进的技术相比,这一程序提供了极具竞争力的结果,并重申了集成不同类型音频特征以开发用于欺骗检测的强大模型的重要性。
原文:https://arxiv.org/abs/1905.12439
移动设备的自监督音频表示学习
Google Research最近基于移动设备音频剪辑中的时间环境提出了一种自我监督的学习方法。在这一研究中他们推荐了Audio2Vec,这是一个受Word2Vec启发的自我监督学习过程,但应用于音频频谱图。
他们同样推荐了TemporalGap,这是另一种自我监督的学习过程,它可以估计随机抽取的任意两对音频片段之间的时间距离。
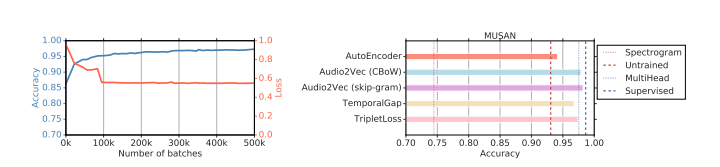
基于可能部署在移动设备上的小型编码器架构,研究人员证明,Audio2Vec和TAemporalGap能够生成可重复用于各种下游任务(如语音、音乐检测、扬声器识别和语言识别等)的表示,而无需在训练工程中使用有标记数据集。
研究表明,自监督模型能在一定程度上减小与完全监督模型的精度差距。
未来,研究人员计划以分布式方法直接在设备上研究自我监督模型的训练。有趣的是,他们还计划合并从不同的自我监督模型中学习到的表示(比如在嵌入语音的情况下)以改进他们的发现。
原文:https://arxiv.org/abs/1905.11796
其它爆款论文
一个非自回归的seq2seq模型,能够将文本转换为频谱图,并减少Attention错误:
https://arxiv.org/pdf/1905.08459.pdf
史上最强基于神经网络的端到端文本-语音转换:https://arxiv.org/abs/1905.09263
如何测量语音转换在说话人识别和自动语音识别系统中的有效性:https://arxiv.org/pdf/1905.12531.pdf
通过观看视频学习导航子例程:
https://arxiv.org/pdf/1905.12612.pdf
AI新闻
电脑能通过回声定位吗?
https://www.wired.com/story/this-ai-uses-echolocation-to-identify-what-youre-doing/
英伟达发布Edge Computing平台致力工业界的实时AI计算:https://www.bloomberg.com/press-releases/2019-05-27/nvidia-launches-edge-computing-platform-to-bring-real-time-ai-to-global-industries

Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
志愿者介绍
后台回复“志愿者”加入我们